本文最后更新于:2024年10月11日 下午
Good old MEMORIES has gone…
0x00. 一切开始之前 不知不觉这个系列的文章居然已经鸽了大半年了…虽然说已经拖了这么久没有继续进行下一步的代码编写,不过笔者目前暂时并没有放弃这个项目,只是确实不像本科那样能有大段大段的空闲时间去抛开一切去做自己想做的事情了:)
言归正传,这一次我们将要脱离引导阶段,进入到位于高地址的真正的内核,并建立内存管理系统,笔者选择优先实现内存管理的原因是因为这是一个非常核心的模块,操作系统内核的各个部分几乎都无时无刻不在进行动态内存分配与释放,因此完成了这个模块的开发之后我们后续的工作也能变得更加方便
本项目代码开源在 https://github.com/arttnba3/ClosureOS
注: 本章暂时省略了常规的内核输出语句 (如类似 printk() 的东西),我们将在下一章完成图形与串口驱动初始化后再重新引入这部分功能,如若你需要查看调试信息,则可以 临时重新引入 boot 阶段的输出模块
注2:本章额外引入了部分辅助用的基础内核数据结构(例如双向链表),由于其实现简单且并非讲述重点,因此本文 不会详细叙述所有额外添加了的东西 ,而是仅关注于 内存分配 这一主线,对于此类基础数据结构的实现方式感兴趣的同学可以自行查看源码:)
内核内存布局设定与链接脚本调整 目前我们暂定的内核内存布局如下所示,笔者在设计时尽量使各个区域都对齐到一个四级页表条目 (512 GB),从而使得我们在后续创建进程时无需重复拷贝过多的内核页表项,而可以尽量进行复用:
Start address
End address
Size
Description
0x0000000000000000
0x00007FFFFFFFFFFF
128TB
memory space for user-mode process, isolate for per one
0x0000800000000000
0xFFFF7FFFFFFFFFFF
16776960 TB
unused hole
shared kernel-space virtual memory for all processes
0xFFFF800000000000
0xFFFFBFFFFFFFFFFF
64TB
direct mapping of first 64TB physical memory (physmem_base)
0xFFFFC00000000000
0xFFFFCFFFFFFFFFFF
16TB
dynamic kernel memory mapping region (vmremap_base)
0xFFFFD00000000000
0xFFFFEFFFFFFFFFFF
32TB
unused hole
0xFFFFF00000000000
0xFFFFF7FFFFFFFFFF
8TB
page database (pgdb_base)
0xFFFFF80000000000
0xFFFFF9FFFFFFFFFF
2TB
unused hole
0xFFFFFA0000000000
0xFFFFFA0FFFFFFFFF
64GB
kernel stack, isolate for each process
0xFFFFFA1000000000
0xFFFFFF7FFFFFFFFF
5568GB
unused hole
0xFFFFFF8000000000
0xFFFFFF800FFFFFFF
256MB
kernel .text segment
0xFFFFFF8010000000
0xFFFFFF801FFFFFFF
256MB
kernel .data segment
0xFFFFFF8020000000
0xFFFFFF802FFFFFFF
256MB
kernel .rodata segment
0xFFFFFF8030000000
0xFFFFFF803FFFFFFF
256MB
kernel .bss segment
0xFFFFFF8050000000
0xFFFFFFFFFFFFFFFF
511GB
unused hole
相应地,我们需要略微调整一下原有的链接脚本中的内核部分,在第一章时笔者仅是简单地将其放置在高内存区域,现在我们根据如上所示内存布局进行调整,这里注意计算各个段的物理位置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 OUTPUT_FORMAT("elf64-x86-64" )boot .loader :KEEP (*(.boot .header))arch /x86/boot /libBoot.aboot .text ALIGN(4096) :arch /x86/boot /libBoot.a(.text)boot .rodata ALIGN(4096) :arch /x86/boot /libBoot.a(.rodata)boot .data ALIGN(4096) :arch /x86/boot /libBoot.a(.data)arch /x86/boot /libBoot.a(.*)
0x01. 内存探测,临时内存分配器,页表重建 内存容量获取与线性内存分配器 在初始化内存管理器之前,首先我们需要知道当前究竟有多少内存,熟悉 BIOS 下 OS 开发的同学肯定对BIOS 0x15 中断的 0xE820 、0xE801 、0x88 这三板斧再熟悉不过了,然而在 UEFI 启动中我们是无法使用 legacy BIOS 的中断进行内存探测的
万幸的是在 UEFI 中同样有类似的接口供我们获取内存容量——UEFI GetMemoryMap() ,不过在我们的系统当中,通过该接口获取内存容量的任务是由 EFI 程序 Grub 完成的—— 得益于 multiboot2 规范的存在,我们可以直接从 multiboot2 header 中获取到内存容量
multiboot2 规范 中 Memory Map 段的 tag 格式如下,其中 size 为 tag header 加上 所有 entry 的大小, entry_size 为单条 entry 的大小:
1 2 3 4 5 6 7 +-------------------+ type = 6 | size | entry_size | entry_version | entries |
每个 entry 的格式如下:
1 2 3 4 5 6 +-------------------+ base_addr | length | type | reserved |
我们简单写一个示例函数(非正式代码)进行测试:
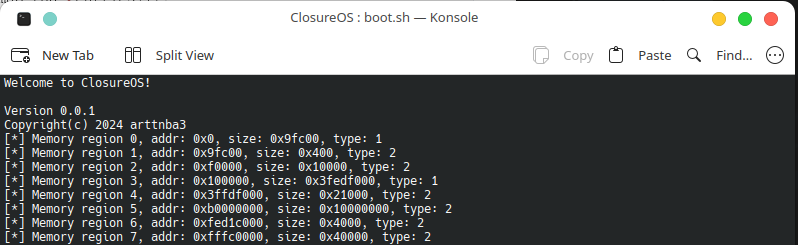
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 void boot_mm_test (multiboot_uint8_t *mbi) struct multiboot_tag *tag;struct multiboot_tag_mmap *mmap_tag = NULL ;int mmap_entry_nr;for (tag = (struct multiboot_tag *) (mbi + 8 );struct multiboot_tag *)multiboot_uint8_t *) tag + ((tag->size + 7 ) & ~7 ))) {if (tag->type == MULTIBOOT_TAG_TYPE_MMAP) {struct multiboot_tag_mmap*) tag;break ;if (!mmap_tag) {boot_puts ("[x] Unable to find mmap tag in multiboot info! Halting..." );asm volatile (" hlt; " ) sizeof (*mmap_tag)) / sizeof (struct multiboot_mmap_entry);for (int i = 0 ; i < mmap_entry_nr; i++) {boot_printstr ("[*] Memory region " );boot_printnum (i);boot_printstr (", addr: 0x" );boot_printhex (mmap_tag->entries[i].addr);boot_printstr (", size: 0x" );boot_printhex (mmap_tag->entries[i].len);boot_printstr (", type: " );boot_printnum (mmap_tag->entries[i].type);boot_putchar ('\n' );
可以看到我们有不少内存段,但其中绝大部分都是不可作为内存使用的保留段(type ==2),我们能用来作为内存使用的只有 type==1 的段:
这些保留段包括 MMIO 区域等
现在让我们正式开始编写与内存管理相关的代码,类似于内核需要分步装载(boot loader 到 kernel),我们的内存管理器同样采用 分步走 的设计思路:
先创建一个最基本的内存管理器,由其分配正式的内存管理器所需的内存,再启用正式的内存管理器
这个内存分配器的作用 仅 是为我们接下来创建正式的内存管理器进行内存分配,因此我们 不需要考虑释放内存的情况,直接线性地分配可用内存空间即可 ,为了简化此阶段的内存分配模型,这里我们限定每次分配的内存大小为单张内存页:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 static struct multiboot_tag_mmap *mmap_tag = nullptr ;static uint32_t mmap_entry_nr;struct multiboot_mmap_entry *curr_entry = nullptr ;int curr_entry_idx = -1 ;phys_addr_t curr_avail, curr_end;static auto boot_mm_page_alloc_internal (void ) -> void *void *res;if (!curr_entry) {for (int i = (curr_entry_idx + 1 ); i < mmap_entry_nr; i++) {if (mmap_tag->entries[i].type == MULTIBOOT_MEMORY_AVAILABLE) {phys_addr_t base = mmap_tag->entries[i].addr;phys_addr_t end = base + mmap_tag->entries[i].len;if (base > end) {boot_puts ("[x] FATAL ERROR: " "integeter overflow at parsing multiboot tags" );asm volatile (" hlt; " ) PAGE_ALIGN (base);if ((end < base) || ((end - base) < PAGE_SIZE)) {continue ;break ;if (!curr_entry) {boot_puts ("[x] FATAL ERROR: NO MEMORY AVAILABLE!" );return ERR_PTR (-ENOMEM);void *) curr_avail;if (curr_avail == curr_end) {nullptr ;return res;
需要注意的一点是, 我们的内核本体便位于可用内存区域 ,因此在进行内存分配时我们应当跳过这些区域,得益于 Multiboot 规范的存在, boot loader 会向我们提供一个如下格式的 tag 来存放 ELF 各节的信息:
1 2 3 4 5 6 7 8 9 +-------------------+ type = 9 | size | num | entsize | shndx | reserved | section headers |
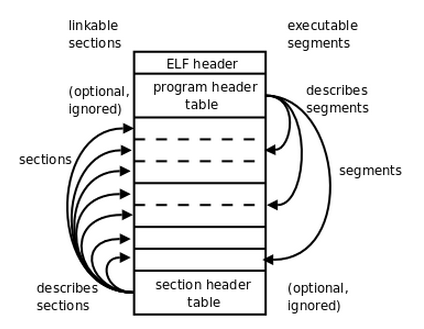
ELF 格式是 *nix 系统中常用的可执行程序的格式,也是我们的 ClosureOS kernel 文件的格式,简单理解可以认为其由一个 ELF header 存储总的信息,由一个 header table 存储不同 section 的信息,简而言之一个 ELF 文件应当长这个样子:
更加详细的细节笔者就不赘叙了,感兴趣的可以自行参考 Linux Foundation - Executable and Linking Format (ELF) Specification ,这里我们简单介绍一下 section header 的格式,multiboot2 elf tag 提供给我们的 section headers 和 ELF 中的 section header table 是一样的,都是一个如下所示结构体的数组,不同的是 sh_offset 段被 GRUB 填上其相对于 ELF 加载起始地址的偏移(在上一篇文章中,我们在链接脚本中将这个起始地址设为 1M ):
1 2 3 4 5 6 7 8 9 10 11 12 struct elf64_shdr {
至于为什么是 section header 而不是 program header,总之 multiboot2 specification 就是这么定义的…
这里我们简单写一个 wrapper 在每次进行内存分配之后将地址与 ELF tag 中各 section 的地址范围进行对比,若刚好位于 ELF 范围则重新进行内存分配,这里我们仅考虑 shdr->sh_type == SHT_PROGBITS 的情况,因为 .text 等段都是这个类型,其他的一些例如 .symtab 等段对于我们程序运行而言其实并不重要;此外我们仅考虑 shdr->sh_flags 包含 SHF_ALLOC 的情况,只有存在该标志位才表示这个段在运行时需要内存
至于 .bss 段,我们所获得的类型为 shdr->sh_type == SHT_NOBITS ,因为这个段的数据全为 0,所以在这里我们可以暂时忽略,等到后续重建高端内核内存映射时再分配这个段的空间
此外,我们还需要避免覆写掉 multiboot tags 所在的区域以及 frame buffer 所在区域:
实际上,frame buffer 的内存区域通常并不直接来自 RAM,而是来自显卡,不过保险起见这里多加一份检查
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 static struct multiboot_tag_elf_sections *elf_info_tag = nullptr ;phys_addr_t multiboot_tag_start, multiboot_tag_end;static auto addr_is_in_used_range (mm::phys_addr_t addr) -> bool struct elf64_shdr *shdr;void *shdr_end;phys_addr_t seg_start, seg_end;void *) ((mm::phys_addr_t ) &elf_info_tag->sectionssizeof (*shdr));for (shdr = (elf64_shdr*) &elf_info_tag->sections;void *) shdr < shdr_end;phys_addr_t ) shdr + sizeof (*shdr))) {if ((shdr->sh_type != SHT_PROGBITS)continue ;0x100000 + shdr->sh_offset;PAGE_ALIGN (seg_start + shdr->sh_size);if (addr >= seg_start && addr < seg_end) {return true ;if (boot_tty_has_fb ()) {if ((addr >= (mm::phys_addr_t ) boot_fb_base)phys_addr_t ) boot_fb_end)) {return true ;if ((addr >= multiboot_tag_start) && (addr <= multiboot_tag_end)) {return true ;return false ;
页表重建立 有了临时的动态内存分配器,现在我们可以开始 建立一个常规的四级页表,并将内核本体对应的物理内存映射到高端内存空间 ,完成这一部分的初始化工作之后我们的后续工作都将在高半部内核完成
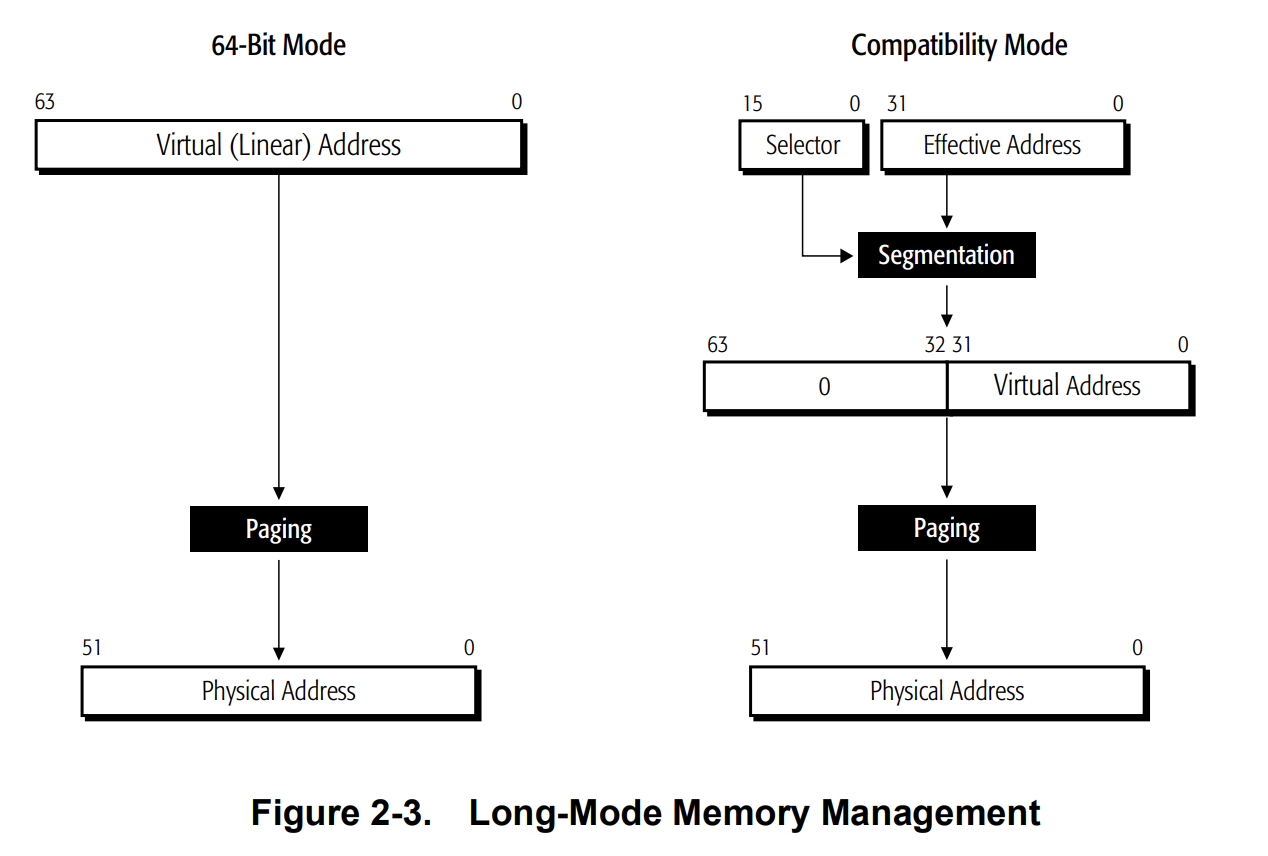
首先是页表映射的建立,页表主要用于将由页表所定义的虚拟地址空间映射到物理地址空间上,在 CPU 进行内存访问时内存管理单元(Memory Management Unit)会根据页表将虚拟地址翻译(translate)成物理地址,在纯 64 位模式下虚拟地址的最大长度为 8 字节,在兼容模式下虚拟地址仅能用前 4 字节,且需要额外经历基于分段的翻译, 我们的 ClosureOS 为纯 64 位系统,暂时不考虑 32 位的情况 :
注: 本章 暂时不考虑 翻译后备缓冲区 (Translation Lookaside Buffer),感兴趣的同学可以先自行了解
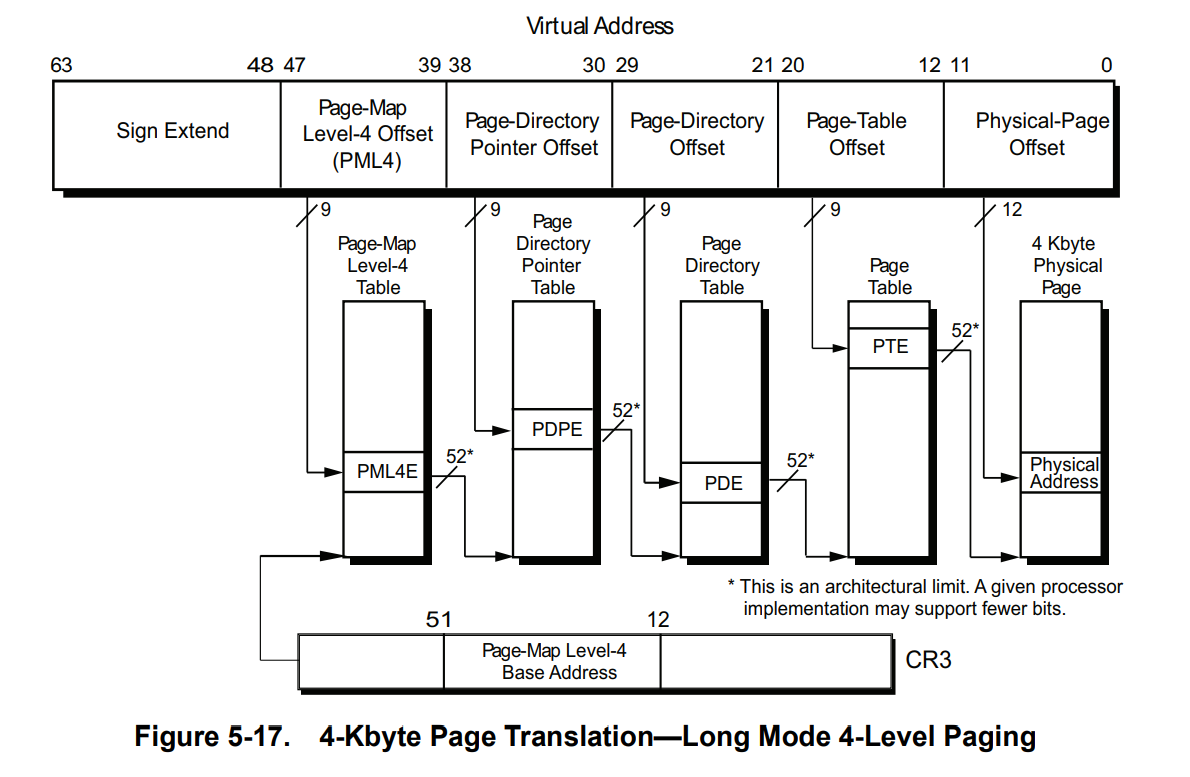
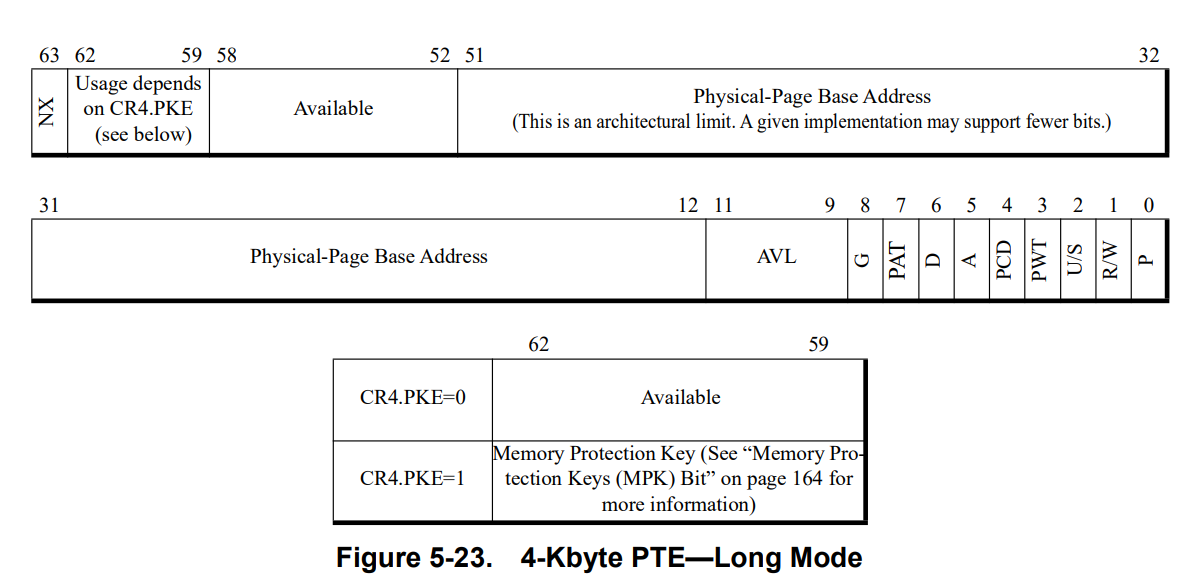
64 位下最常用的是 4 级页表结构,页顶级表的地址被存放在 CR3 寄存器中,通常情况下一张内存页被设定为 4KB,单条页表项的长度为 8 字节:
对于虚拟地址而言,前 12 位被用来表示内存页内的偏移;对于页表项而言,前 12 位用于存放页权限等信息
剩下的 36 位每 9 位用来表示在页表不同级别的偏移,开启 5 级分页后额外多用 9 位表示第 5 级的偏移,否则作为保留位
剩下 7 位用作扩展
纯 64 位模式下,4K 页的页表项结构如下:
前 12 位的各位说明如下:
AVL :available,该页是否可用,可忽略G :是否为全局页 ,全局页会被保存在 TLB 中方便调用;1为是PAT :页属性表位,用以在分级页表中设定页的属性,这里暂且先置0D :Dirty,当一张内存页被写入时,CPU会将该页标脏 ,仅针对页表项有效A :Accessed,该页每次被访问时该位都会被置1,定期清零,置1次数用以表示使用频率PCD :Page-level Cache Disable,0 为启用高速缓存,1 为禁止PWT :Page-level Write-Through,页级通写位,与高速缓存有关,这里暂且置 0US :User/Supervisor,权限位,1 时 ring0~ring3 均可访问该页,0时仅 ring0~ring2 可访问(一般来说操作系统只需要用到 ring0 与 ring3)RW :即 Read/Write,该位为 1 时该页可读写,否则只可读不可写P :Present,即该页是否存在,0 表示该页不存在于物理页中,此时对该页的访问会引发缺页异常
我们的 ClosureOS 使用的是常规的 4 级页表与 4KB 页大小,因为这更适合我们对不同的内存区域进行更加细粒度的映射管理,对于页表的映射建立操作,我们只需要直接分配各级页表项的空间后写入即可,这里需要注意的是 高级页目录表项权限会限制低级页表项的权限,因此对于存在映射的虚拟内存区域,除了最后一级页表项以外的页目录表项我们都应当给予可写的权限 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #define PDE_DEFAULT (PDE_ATTR_P | PDE_ATTR_RW) static auto boot_mm_pgtable_map (mm::phys_addr_t pgtable, mm::virt_addr_t va, mm::phys_addr_t pa, mm::page_attr_t attr) -> int pgd_t *pgd;pud_t *pud;pmd_t *pmd;pte_t *pte;int pgd_i = PGD_ENTRY (va);int pud_i = PUD_ENTRY (va);int pmd_i = PMD_ENTRY (va);int pte_i = PTE_ENTRY (va);pgd_t *) pgtable;if (!pgd[pgd_i]) {pgd_t ) boot_mm_page_alloc ();if (IS_ERR_PTR ((void *) pgd[pgd_i])) {pgd_t ) nullptr ;return -ENOMEM;boot_memset ((void *) ((mm::phys_addr_t ) pgd[pgd_i]), 0 ,PAGE_SIZE);pud_t *) (pgd[pgd_i] & PAGE_MASK);if (!pud[pud_i]) {pud_t ) boot_mm_page_alloc ();if (IS_ERR_PTR ((void *) pud[pud_i])) {pud_t ) nullptr ;return -ENOMEM;boot_memset ((void *) ((mm::phys_addr_t ) pud[pud_i]), 0 ,PAGE_SIZE);pmd_t *) (pud[pud_i] & PAGE_MASK);if (!pmd[pmd_i]) {pmd_t ) boot_mm_page_alloc ();if (IS_ERR_PTR ((void *) pmd[pmd_i])) {pmd_t ) nullptr ;return -ENOMEM;boot_memset ((void *) ((mm::phys_addr_t ) pmd[pmd_i]), 0 ,PAGE_SIZE);pte_t *) (pmd[pmd_i] & PAGE_MASK);return 0 ;
现在我们可以开始重新建立新的页表映射了,我们首先映射这几个区域:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 static auto boot_mm_pgtable_init (void ) -> int struct elf64_shdr *shdr;void *shdr_end;phys_addr_t seg_phys_start, seg_phys_end;virt_addr_t seg_virt_start, seg_virt_end;page_attr_t pte_attr;phys_addr_t physmem_start, physmem_end;size_t pgdb_page_nr;int ret;phys_addr_t ) boot_mm_page_alloc ();if (IS_ERR_PTR ((void *) boot_kern_pgtable)) {boot_puts ("[x] FAILED to allocate new page table!" );return -ENOMEM;boot_memset ((void *) boot_kern_pgtable, 0 , PAGE_SIZE);void *) ((mm::phys_addr_t ) &elf_info_tag->sectionssizeof (*shdr));for (shdr = (elf64_shdr*) &elf_info_tag->sections;void *) shdr < shdr_end;phys_addr_t ) shdr + sizeof (*shdr))) {if (!(shdr->sh_flags & SHF_ALLOC)) {continue ;if (shdr->sh_type & SHT_PROGBITS) { 0x100000 + shdr->sh_offset - PAGE_SIZE;PAGE_ALIGN (seg_phys_start + shdr->sh_size);while (seg_phys_start < seg_phys_end) {if (shdr->sh_flags & SHF_WRITE) {boot_mm_pgtable_map (boot_kern_pgtable,if (ret < 0 ) { return ret;else if (shdr->sh_type & SHT_NOBITS) { PAGE_ALIGN (seg_virt_start + shdr->sh_size);while (seg_virt_start < seg_virt_end) {if (shdr->sh_flags & SHF_WRITE) {phys_addr_t ) boot_mm_page_alloc ();if (IS_ERR_PTR ((void *) seg_phys_start)) {return -ENOMEM;boot_memset ((void *) seg_phys_start, 0 , PAGE_SIZE);boot_mm_pgtable_map (boot_kern_pgtable,if (ret < 0 ) { return ret;else { boot_puts ("[x] Unknown segment. ELF mapping stopped." );return -EFAULT;if (boot_tty_has_fb ()) {phys_addr_t ) boot_fb_base) & PAGE_MASK;PAGE_ALIGN (seg_phys_start + boot_tty_fb_sz ());while (seg_phys_start < seg_phys_end) {boot_mm_pgtable_map (boot_kern_pgtable,if (ret < 0 ) { return ret;0x0000000000000000 ;for (int i = 0 ; i < mmap_entry_nr; i++) {phys_addr_t base = mmap_tag->entries[i].addr & PAGE_MASK;phys_addr_t end = base + mmap_tag->entries[i].len;virt_addr_t vaddr = base + mm::KERN_DIRECT_MAP_REGION_BASE;if (end > physmem_end) {if (vaddr < base) {boot_printstr ("[x] FATAL: memory region base 0x" );boot_printhex (base);boot_puts (" has caused an integer overflow in memory mapping." );asm volatile (" hlt " ) while (base < end) {if (vaddr > mm::KERN_DIRECT_MAP_REGION_END) { break ;boot_mm_pgtable_map (boot_kern_pgtable,if (ret < 0 ) {return ret;
咕咕咕 🕊🕊🕊
暂时先留给大家当课后作业了,tips:映射前给几个变量加上偏移值就行,不过你或许还需要额外修改一些链接 flags? : )
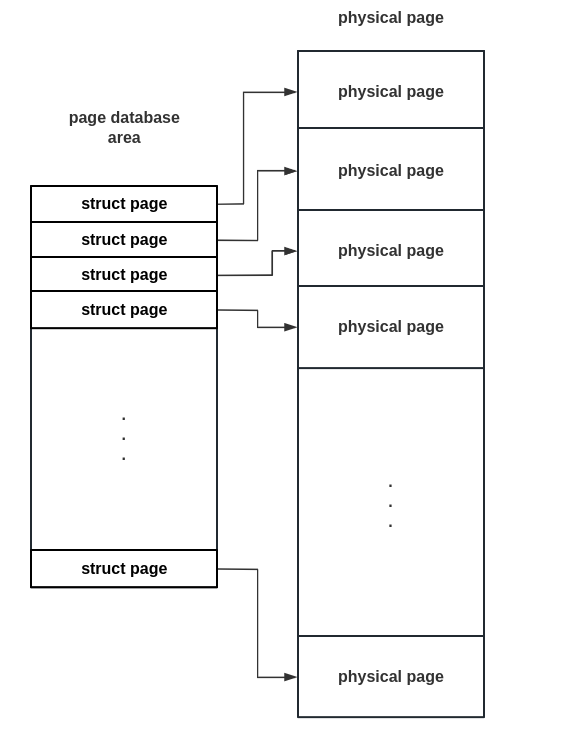
建立内存页数据库 接下来我们开始建立 内存页数据库 (page database),这一个内存区域的存在是为了能够更好地管理所有的物理页框,首先我们使用如下结构表示单张内存页,其中 type 字段用来表示当前内存页的类型,ref_count 字段为当前页面的引用计数(闲置时为 -1),其他字段我们会在后续使用到时进行说明:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 enum {0 ,enum migrate_type {0 ,struct Page {public :struct {unsigned type: 4 ;unsigned migrate_type: 4 ;unsigned is_free: 1 ; unsigned is_head: 1 ; unsigned order: 4 ;atomic_t ref_count; atomic_t map_count; void **freelist; size_t obj_nr; size_t unused[0 ];aligned (64 )));
现在我们引入内存页数据库的概念,这是一个由 struct page 所组成的数组, 数组下标直接对应物理页框号 ,通过这样的一个结构我们便能非常方便地管理所有的内存页,由于 struct page 大小为 64 字节,我们的内存页数据库将会使用相当数量的内存来表示所有的内存,为了保证这是一个虚拟地址连续的数组, 我们单独分配一个内存区域来存放 page 结构体 :
我们首先进行该区域的映射建立:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 static auto boot_mm_pgtable_init (void ) -> int for (base::size_t i = 0 ; i < pgdb_page_nr; i += mm::PGDB_PG_PAGE_NR) {void *new_page = boot_mm_page_alloc ();if (IS_ERR_PTR (new_page)) {return PTR_ERR (new_page);boot_memset ((void *) new_page, 0 , PAGE_SIZE);boot_mm_pgtable_map (boot_kern_pgtable,virt_addr_t ) &pgdb_base[i],phys_addr_t ) new_page,if (ret < 0 ) {return ret;
完成这些工作之后, 我们便直接装载这份新的页表,作为后续正式的内核页表 ,并初始化一些记录内存段的变量,以及将一些可能还会用到的指针重新映射到 Direct Mapping Area ,因为我们不能保证在加载新页表后其所在内存区域仍然有映射:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 static auto boot_mm_load_pgtable (mm::phys_addr_t pgtable) -> void asm volatile ( "mov %0, %%rax;" "mov %%rax, %%cr3;" : : "a" (pgtable) ) static auto boot_mm_pgtable_init (void ) -> int boot_mm_load_pgtable (boot_kern_pgtable);phys_to_virt ((mm::phys_addr_t ) elf_info_tag);phys_to_virt ((mm::phys_addr_t ) mmap_tag);return 0 ;
接下来我们根据 multiboot2 tags 所提供的内存信息来初始化 page 结构体数组,并根据临时线性内存分配器的分配地址计算页面引用计数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 static auto boot_mm_page_database_init (void ) -> int int ret;for (int i = 0 ; i < mmap_entry_nr; i++) {phys_addr_t base = mmap_tag->entries[i].addr;phys_addr_t end = base + mmap_tag->entries[i].len;size_t pfn;while (base < end) {Reset ();nullptr ;nullptr ;nullptr ;0 ;list_head_init (&mm::pgdb_base[pfn].list);switch (mmap_tag->entries[i].type) {case MULTIBOOT_MEMORY_AVAILABLE:if (base < curr_avail || addr_is_in_used_range (base)) {atomic_set (&mm::pgdb_base[pfn].ref_count, 0 );else {atomic_set (&mm::pgdb_base[pfn].ref_count, -1 );break ;case MULTIBOOT_MEMORY_RESERVED:atomic_set (&mm::pgdb_base[pfn].ref_count, 0 );break ;case MULTIBOOT_MEMORY_ACPI_RECLAIMABLE:atomic_set (&mm::pgdb_base[pfn].ref_count, 0 );break ;case MULTIBOOT_MEMORY_NVS:atomic_set (&mm::pgdb_base[pfn].ref_count, 0 );break ;case MULTIBOOT_MEMORY_BADRAM:atomic_set (&mm::pgdb_base[pfn].ref_count, 0 );break ;default :atomic_set (&mm::pgdb_base[pfn].ref_count, 0 );break ;return 0 ;
到目前为止,我们已经 基本完成进入高半部内核前的准备了 ,接下来我们直接跳转到位于高地址的代码继续进行后续的内核初始化工作
原子操作(atomic operations)指的是独立而 不可被打断的操作 ,这类操作可以由单个或多个子操作组成, 原子内存操作 即提供了原子性的内存操作,即在同一时刻仅有单个核心能够访问指定内存,其通常被用来在并发环境中实现同步,比较常用的有:
原子比较与赋值:对比指定内存位置上值是否与指定值相等,若是则赋予新值,否则报错
原子自增自减:将指定内存位置上值加一或减一
原子读写:获取/覆写指定内存位置上值
例如在 x86 下我们可以通过如添加了 lock 前缀的汇编指令在访问内存的同时完成对总线的控制,从而从硬件层面确保了内存访问的唯一性 :
注:该示例代码仅用于讲解原理, 未 用于 ClosureOS 中
1 2 3 4 5 6 7 8 9 10 11 12 static inline uint32_t atomic_xchg (volatile uint32_t *addr, uint32_t newval) uint32_t result;asm volatile ( "lock; xchgl %0, %1" : "+m" (*addr), "=a" (result) : "1" (newval) : "cc" ) return result;
在 GCC 中,我们可以直接使用 编译器内置的原子内存访问函数 来实现原子操作,编译器在生成代码时便会自动生成带有 lock 等前缀的指令:
我们将同一时间仅允许一个核心进行访问的资源称为临界资源(critical resource),将访问临界资源的代码称为临界区(critical region)—— 锁 (lock)是一种用来确保在同一时间仅有一个核心进入指定临界区的数据结构,软件设计规范中我们通常要求程序在访问临界资源前需要持有锁,在完成对临界资源的操作后释放锁,从而确保同一时间仅有单个核心在访问该临界资源
通过原子内存操作中的 比较与交换 操作,我们可以很容易实现一个简单的锁:
定义一个整形变量作为锁,0 为已释放,1 为仍被持有
循环调用 GCC 内建函数 __sync_bool_compare_and_swap() 进行原子操作:检测锁变量的值,其为 0 时将其改为 1
完成操作后将锁变量的值更改为 0
由于锁在被持有的情况下请求锁的一方会循环不停地检查,因此这种锁被称为 自旋锁 (spin lock),我们的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 typedef volatile base::int32_t atomic_t ;template <typename PtrType, typename OldValType, typename NewValType>__always_inline auto atomic_compare_and_swap (PtrType ptr, OldValType oldval, NewValType newval) -> bool return __sync_bool_compare_and_swap(ptr, oldval, newval);template <typename PtrType, typename NewValType>__always_inline auto atomic_set (PtrType ptr, NewValType newval) -> auto return __sync_lock_test_and_set(ptr, newval);#define SPINLOCK_LOCKED 1 #define SPINLOCK_FREE 0 class SpinLock {public :SpinLock ();SpinLock ();auto Lock (void ) -> void auto TryLock (void ) -> bool auto UnLock (void ) -> void auto Reset (void ) -> void private :atomic_t counter;SpinLock ()this ->Reset ();auto SpinLock::Lock (void ) -> void while (!atomic_compare_and_swap (&this ->counter, SPINLOCK_FREE, SPINLOCK_LOCKED)) {auto SpinLock::TryLock (void ) -> bool return atomic_compare_and_swap (&this ->counter, SPINLOCK_FREE, SPINLOCK_LOCKED);auto SpinLock::UnLock (void ) -> void atomic_set (&this ->counter, SPINLOCK_FREE);auto SpinLock::Reset (void ) -> void atomic_set (&this ->counter, SPINLOCK_FREE);
0x02. 页级内存分配器:buddy 算法 我们按惯例将内核侧的内存分配分为两部分:一部分是以内存页为单位的粗粒度页级内存分配器,另一部分是从页级内存分配器分配内存页后再将其划分为更多小对象的细粒度内存分配器,本节我们将实现页级内存分配器
伙伴算法 ( buddy memory allocation )是笔者所见过的几种页级内存管理算法当中 比较优雅的一种 ,因此在 ClosureOS 当中我们的页级内存分配器也采用这种算法,我们将这一内存分配器称为 buddy system
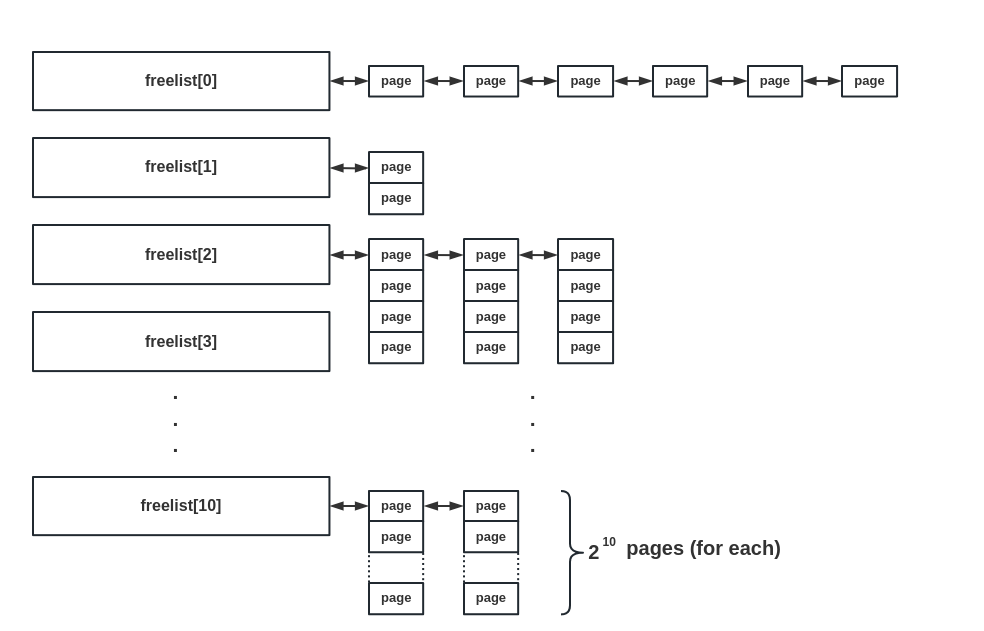
我们使用 struct page 结构体来管理空闲的内存页,并将连续的空闲内存页进行分阶 (order) 管理,一份 N 阶的空闲内存页表示 2^N 张连续的空闲内存页,最高阶设为 10 ,位于同一阶的空闲内存页通过第一张页的 list 字段连接为双向链表
相同阶的两份页面互相称为 buddy,为了方便进行页面管理,简化页面分配模型, 我们将一份 buddy pages 限制为页框号在 1 << order 上分别为 0 与 1 的两份页面 :
1 2 3 4 5 6 7 8 9 10 __always_inline auto buddy_page_pfn (pfn_t pfn, int order) -> base::size_t return pfn ^ (1 << order);__always_inline auto get_page_buddy (Page *p, int order) -> Page* pfn_t pfn = page_to_pfn (p);return pfn_to_page (buddy_page_pfn (pfn, order));
在上层,我们将单个页级内存池封装为一个 PagePool 类,其通过一个自旋锁确保内存分配的线程安全,空闲内存页按照其所属的阶链接到各自所属的空闲双向链表中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 inline constexpr base::size_t MAX_PAGE_ORDER = 11 ;class PagePool {public :PagePool (void );PagePool ();auto AllocPages (base::size_t order) -> Page *auto FreePages (Page *page, base::size_t order) -> void auto Init (void ) -> void auto AddPages (Page *page, base::size_t order) -> void private :auto __reinit_page(Page *p, base::size_t order, bool free) -> void ;auto __alloc_page_direct(base::size_t order) -> Page *;auto __alloc_pages(base::size_t order) -> Page *;auto __free_pages(Page *p, base::size_t order) -> void ;auto __reclaim_memory(void ) -> void ;
内存页分配:对齐到 2^N 张页,拆高阶页面 buddy 算法中的分配流程如下:
首先会将请求的内存大小向 2 的幂次方张内存页大小对齐,之后从对应的下标取出连续内存页,若成功取到则直接返回
若对应下标链表为空,则会从下一个 order 中取出内存页,一分为二,其中一份装载到当前下标对应链表中,另一份再返还给上层调用,若下一个 order 也为空则会继续向更高的 order 进行该请求过程,直到成功分配或超过最高阶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 auto PagePool::__alloc_page_direct(base::size_t order) -> Page *nullptr ;size_t allocated = order;while (allocated < MAX_PAGE_ORDER) {if (!lib::list_empty (&this ->freelist[allocated])) {list_entry (this ->freelist[allocated].next, &Page::list);list_del (&p->list);break ;else {if (!p) {goto out;if (allocated != order) {do {get_page_buddy (p, allocated);this ->__reinit_page(buddy, allocated, true );list_add_next (&this ->freelist[allocated], &buddy->list);while (allocated > order);this ->__reinit_page(p, allocated, false );return p;
完成内存页分配之后,我们还需要完成对分配的这一组内存页的标记,对于一份 order=N 的连续内存页,我们以其首页作为标识,其余页面则作为附属页,我们通过 is_head 标志位进行标识,并使用一个额外的 order 字段存储当前页面所属连续内存页的 order:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 auto PagePool::__reinit_page(Page *p, base::size_t order, bool free) -> void for (auto i = 0 ; i < (1 << order); i++) {nullptr ;nullptr ;false ;atomic_set (&p->ref_count, -1 );atomic_set (&p->map_count, -1 );0 ].is_head = true ;
此外,我们设计一个增加页面引用计数的 API ,当页面被引用时我们应当调用该函数增加其引用计数,在 ClosureOS 开发规范中我们应当在分配页面后调用该 API 增加引用计数:
1 2 3 4 __always_inline auto get_page (struct Page *p) -> void atomic_inc (&get_head_page (p)->ref_count);
内存页释放:检测相邻空闲页组, 向上合并 buddy 算法的内存页释放流程如下:
检查同一 order 的物理相邻高地址页面,若为空闲则将其脱链,合并成为一份新 pages
否则,检查同一 order 的物理相邻低地址页面,若为空闲则将其脱链,合并成为一份新 pages
order 增加,进入下一轮循环直到超过最大 order 或是同一 order 的前向与后向页面都非空闲
更新所有子页面信息,最后将页面挂到对应 order 的空闲页面链表上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 auto PagePool::__free_pages(Page *p, base::size_t order) -> void if (!p) {return ;if (order >= MAX_PAGE_ORDER) {return ;this ->lock.Lock ();while (order < (MAX_PAGE_ORDER - 1 )) {get_page_buddy (p, order);if (buddy->type == PAGE_NORMAL_MEM && buddy->is_head && buddy->is_free) {list_del (&buddy->list);if (buddy < p) {false ;continue ;break ;this ->__reinit_page(p, order, true );list_add_next (&(this ->freelist[order]), &p->list);this ->lock.UnLock ();
不过我们在 ClosureOS 中通常 并不直接调用页面释放的这个 API ,而是根据引用计数的减少来决定是否该释放页面,在引用计数减少为负数值时自动释放该页面,从而将引用计数管理与页面释放相统一,而无需开发者手动检查:
1 2 3 4 5 6 7 8 __always_inline auto put_page (struct Page *p) -> void get_head_page (p);if (lib::atomic::atomic_dec (&p->ref_count) < 0 ) {FreePages (p, p->order);
需要注意的是,目前还只是比较简陋的基础设计,尚未加入各种异常检测(例如 page::ref_count 小于 -1 的情况),我们将在后续添加上完整的错误处理系统(例如 kernel panic )后再行补充
0x03. 通用内存分配器:slub 算法
注:本章我们 暂时不考虑动态虚拟内存分配 (即传统的 vmalloc() ),仅考虑基于直接映射区的内存分配
现在我们基于页级内存分配器进行小对象分配器的设计:小对象分配器会先从 buddy system 分配页面,将其分割为多个小对象后,再将符合要求的内存对象返还给上层调用
对于小对象分配器,我们使用 slub allocator ——这是一种应用于 Linux kernel 中的久经检验的内存分配算法,其核心思想如下:
我们将不同大小的内存对象请求归到不同的内存池进行处理,例如对于大小为 16 字节的内存请求从 kmalloc-16 这一内存池进行分配,对于非对齐的内存分配大小则向上对齐到相应的内存池进行分配
不同的内存池独立持有一组页面,在需要时自行向 buddy system 进行内存分配请求
内存池向 buddy system 单次请求得到的一份连续内存页称为 slub ,一张 slub 会被分割为多个相同大小的小内存对象,空闲内存对象间连接成单向链表结构
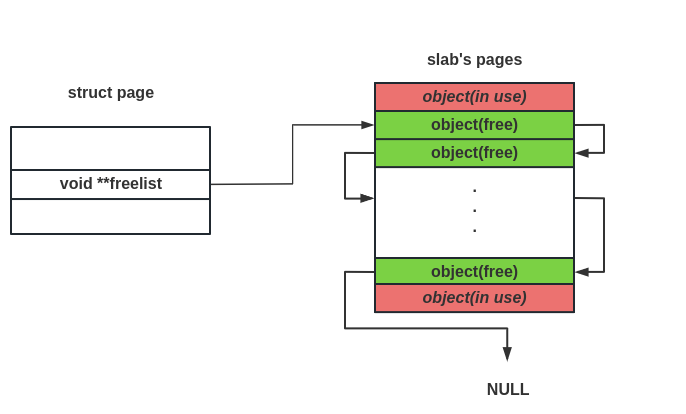
slub allocator 的好处在于 我们并不需要额外的数据字段去记录每个内存对象的状态信息 ,我们使用 direct mapping area 的地址来分割 slub pages,由此很容易能根据内存对象的地址获取到其所属的页面与对应的 page 结构体,同时使用链表组织空闲对象可以让我们很方便地得知当前 slub pages 的状态
我们使用 page 结构体中的一个字段记录其对应的 slub pages 的空闲对象链表,基本结构如下图所示:
为什么使用二阶指针?主要是因为笔者个人比较喜欢的一种链表迭代写法:
1 page->freelist = *page->freelist;
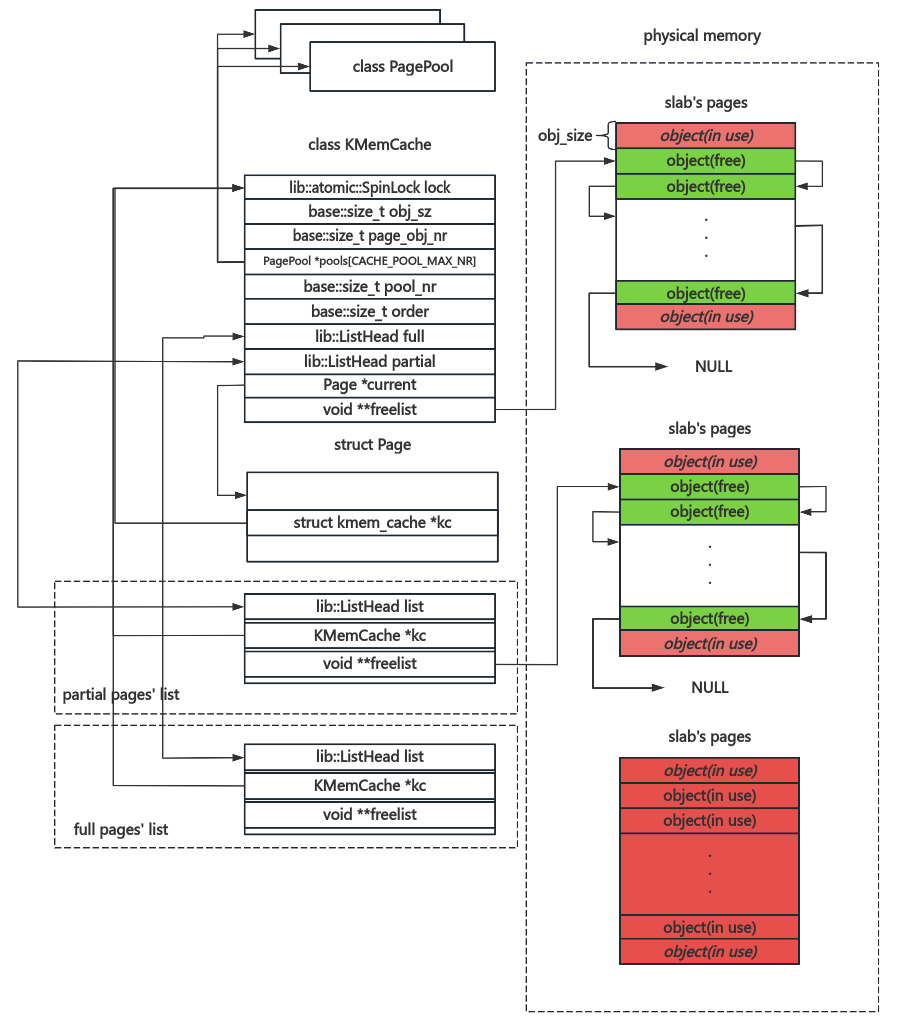
然后是内存池结构的设计,我们使用一个 class KMemCache 结构定义一个指定大小的内存池,并为每个内存池设计两个链表:
full :这个链表上的 slub pages 没有空闲对象partial 这个链表上的 slub pages 有一定的空闲对象
此外,我们在 KMemCache 中记录其所需的 slub pages 上的对象数量等信息
注:本章我们暂时不考虑针对多核的优化策略(如 cpu 独占的 KMemCacheCPU ),等到后期如果笔者还有精力再行优化:)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 class KMemCache {public :KMemCache (void );KMemCache ();auto Malloc (void ) -> void *auto Free (Page *page, void *obj) -> void auto AddPool (PagePool *pool) -> bool auto RemovePool (base::size_t index) -> PagePool*auto Init (base::size_t obj_sz) -> void private :size_t pool_nr;size_t order;auto __internal_page_alloc(void ) -> Page*;auto __page_obj_slicing(Page* page) -> void ;size_t page_obj_nr;size_t obj_sz;void **freelist;auto __internal_obj_alloc(void ) -> void *;auto __internal_obj_free(Page *page, void *obj) -> void ;enum {0 ,uint8_t GloblKMemCacheGroupMem[KOBJECT_SIZE_NR][sizeof (KMemCache)];
简而言之,我们的 KMemCache 结构如下图所示:
我们在内存管理模块初始化时进行内存池的初始化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 auto KMemCache::Init (base::size_t obj_sz) -> void for (auto i = 0 ; i < CACHE_POOL_MAX_NR; i++) {this ->pools[i] = nullptr ;this ->pool_nr = 0 ;this ->order = obj_sz >> PAGE_SHIFT;if (obj_sz >= PAGE_SIZE) {this ->order++;this ->obj_sz = obj_sz;this ->page_obj_nr = (PAGE_SIZE << this ->order) / this ->obj_sz;this ->current = nullptr ;list_head_init (&this ->partial);list_head_init (&this ->full);this ->freelist = nullptr ;this ->lock.Reset ();static auto kheap_pool_init (void ) -> void for (auto i = 0 ; i < KOBJECT_SIZE_NR; i++) {Init (kobj_default_size[i]);AddPool (GloblPagePool);
内存对象分配策略 首先是内存对象的分配,我们按照单次请求的大小将请求分为两类:
对于小于内存池组最大大小的内存请求,我们将请求大小向上对齐到最近的内存池对象大小,从中进行分配
对于大于内存池组最大大小的内存请求,我们将其对齐到 (2 ^ N) * PAGE_SIZE 大小,从 buddy system 进行页面分配请求
我们使用从 buddy system 分配的一份页面的首个 Page 结构体的 Page::kc 字段标识其是否属于某个 KMemCache ,从而区分这两类内存分配
在 KMemCache 与 PagePool 之上,我们再包装一层 KHeapPool 结构体作为内存分配的前端,用于隐藏背后的分配细节:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 class KHeapPool {public :KHeapPool (void );KHeapPool ();auto Malloc (base::size_t size) -> void *auto Free (void *obj) -> void auto PageAlloc (base::size_t order) -> Page*auto PageFree (Page *p) -> void auto Init (void ) -> void auto SetKMemCaches (KMemCache **caches, base::size_t cache_nr, base::size_t *cache_obj_sizes) -> void auto SetPagePools (PagePool **pools, base::size_t pool_nr) -> void private :size_t cache_nr;size_t *cache_obj_sizes;auto __malloc_caches(base::size_t size) -> void *;size_t pool_nr;auto __malloc_pools(base::size_t size) -> void *;auto KHeapPool::Malloc (base::size_t size) -> void *void *obj = nullptr ;this ->__malloc_caches(size);if (!obj) {this ->__malloc_pools(size);return obj;auto KHeapPool::__malloc_caches(base::size_t size) -> void *void *obj = nullptr ;for (auto i = 0 ; i < this ->cache_nr; i++) {if (size <= this ->cache_obj_sizes[i]) {this ->caches[i]->Malloc ();if (obj) {break ;return obj;
I. 小对象分配:当前 slub -> partial list -> PagePool 对于比较常见的小对象内存分配,我们的策略如下:
首先向上对齐分配大小,检查对应内存池的当前 freelist 是否仍有对象,若是则直接分配并返回
若否,检查当前是否有 slub page,若是则将其挂到 full list
检查 partial list 是否仍有空闲内存页,若是则取下并分配为当前 slub page 并回到第一步重新开始分配
若 partial list 也为空,向 PagePool 请求内存页,成功则回到第一步重新开始分配,失败则直接返回 NULL
需要注意的是在我们的设计中内存池应当在多个核之间进行共享,因此所有操作需要全程加锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 auto KMemCache::__internal_obj_alloc(void ) -> void *void *obj = nullptr ;if (this ->freelist != nullptr ) {this ->freelist;this ->freelist = (void **) (*this ->freelist);this ->current->obj_nr--;goto out;if (this ->current) {list_add_next (&this ->full, &this ->current->list);this ->current = nullptr ;if (!lib::list_empty (&this ->partial)) {this ->current = lib::container_of (this ->partial.next, &Page::list);this ->freelist = this ->current->freelist;list_del (&this ->current->list);goto redo;this ->current = this ->__internal_page_alloc();if (this ->current) {this ->__page_obj_slicing(this ->current);this ->freelist = this ->current->freelist;goto redo;return obj;auto KMemCache::__internal_page_alloc(void ) -> Page*nullptr ;for (auto i = 0 ; i < CACHE_POOL_MAX_NR; i++) {if (this ->pools[i]) {this ->pools[i]->AllocPages (this ->order);if (new_page) {break ;return new_page;auto KMemCache::Malloc (void ) -> void *void *obj;this ->lock.Lock ();this ->__internal_obj_alloc();this ->lock.UnLock ();return obj;
在进行新的 slub pages 分配时,我们应当根据当前内存池信息将其分割为相应数量的空闲对象,并将空闲对象链接为单向链表:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 auto KMemCache::__page_obj_slicing(Page* page) -> void void *curr_obj;virt_addr_t next_obj;void **obj_ptr;page_to_virt (page);nullptr ;void **) next_obj;for (auto i = 0 ; i < this ->page_obj_nr; i++) {void *) next_obj;this ->obj_sz;void **) next_obj;this ->page_obj_nr;void **) curr_obj;this ;get_page (page);
II. 大内存分配:退化至 PagePool 对于较大的内存分配,KMemCache 会直接拒绝请求,此时在 KHeapPool 的分配前端中会回退到 PagePool 进行分配:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 auto KHeapPool::__malloc_pools(base::size_t size) -> void *size_t order = 0 , need = size;1 );while (size > 0 ) {1 ;if (((1 << order) * PAGE_SIZE) < need) {for (auto i = 0 ; i < this ->pool_nr; i++) {this ->pools[i]->AllocPages (order);if (obj) {get_page (obj);return (void *) page_to_virt (obj);return nullptr ;
内存对象释放:对象回归与链表迁移 内存释放的逻辑则简单得多:
首先根据虚拟地址找到对应的 page 结构体,若不属于任一 KMemCache 则说明为大内存分配,直接释放回所属 PagePool
否则,找到其对应的 KMemCache ,判断当前 slub page 所属:
若为正在使用的 slub page,直接将对象挂回 KMemCache::freelist
否则,挂回对应 page 的 freelist,若为 full list 则迁移至 partial list
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 auto KHeapPool::Free (void *obj) -> void get_head_page (virt_to_page ((virt_addr_t ) obj));if (!page->kc) {put_page (page);return ;Free (page, obj);auto KMemCache::Free (Page *page, void *obj) -> void this ->lock.Lock ();this ->__internal_obj_free(page, obj);this ->lock.UnLock ();auto KMemCache::__internal_obj_free(Page *page, void *obj) -> void if (page == this ->current) {void **) obj = this ->freelist;this ->freelist = (void **) obj;else {if (page->obj_nr == 1 ) { list_del (&page->list);list_add_next (&this ->full, &page->list);else if (page->obj_nr == this ->page_obj_nr) { list_del (&page->list);put_page (page);
0x04. C++ 的初步引入 现在我们考虑进行 C++ 代码的引入,笔者选择引入 C++ 代码的主要原因是为了 OOP 特性,虽然说使用 C 同样可以编写面向对象的代码,但是总归没有 C++ 的原生 OOP 看起来那么直观
在 bare bone 环境下,我们 无法使用标准库 ,因此此时的 C++ 几乎 是相当于 C with class,不过额外多了一些特性:
隐式的对构造函数与析构函数的调用
隐式的内存分配与释放
对于构造函数与析构函数的自动调用,这是由编译器去决定的,因此大部分情况下我们可以不用处理, 除了全局对象的构造函数 —— 我们应当确保其在我们完成内存管理子系统的初始化之后再进行
对于隐式的内存分配与释放,我们只需要 重载全局 new/delete 运算符即可
此外,我们应当 禁用 C++ 的异常处理机制 ,因为这个特性在内核上下文不好实现,同时会引入很多额外的开销,我们通过在编译时添加 -fno-exceptions 以关闭该特性
new/delete 运算符的重载 new/delete 运算符重载的方式比较简单,我们只需要在某个文件中实现这些运算符重载,在其中调用内存分配的 API 即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <closureos/cpp_base.hpp> #include <closureos/errno.h> import kernel.lib;import kernel.mm;void * operator new (size_t sz) return mm::GloblKHeapPool->Malloc (sz);void * operator new [](size_t sz)return mm::GloblKHeapPool->Malloc (sz);void operator delete (void *p) noexcept Free (p);void operator delete [](void *p) noexcept Free (p);void operator delete (void *p, unsigned long sz) noexcept Free (p);void operator delete [](void *p, unsigned long sz) noexcept Free (p);
之后对于所有的 C++ 代码,在链接时编译器会自动寻找到这些运算符定义
global constructor 的调用 在用户态程序中对于全局初始化器(例如全局对象的构造函数,或是 constructor attribute 修饰的函数)的调用通常在 main() 函数前完成(这里我们仅考虑 GCC 编译器),编译器会生成对应的 调用构造器与析构器的函数 (通常每个文件一个,函数名中带有 static_initialization_and_destruction ),并将这些函数的地址单独存放到一个 .init_array 段,在运行 main() 函数前的 __libc_start_main() 会调用这些函数指针
因此对于我们的 kernel 环境而言,若要初始化这些全局对象, 我们只需要手动调用这些函数指针即可 ,这里笔者将 .init_array 段放在了 .data 段中,并使用一个外部符号标识其位置:
1 2 3 4 5 .data ALIGN (4096) : AT (__kernel_text_sz + __boot_end )data )
之后我们直接引入该符号并调用对应的函数指针即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 extern "C" {extern int (*__init_array) (void ) extern int (*__init_array_end) (void ) auto global_constructor_caller (void ) -> int int (**init_array)(void ) = &__init_array;int (**init_array_end)(void ) = &__init_array_end;int error;for (base::size_t i = 0 ; init_array[i] && ((init_array + i) < init_array_end); i++) {if (error) {return error;return 0 ;
global destructor 的调用 全局析构器的实现则比构造器相对复杂一些,对每个存在全局构造器/析构器的文件的 *_static_initialization_and_destruction_*() 函数,其除了调用构造器以外,还会 进行析构器信息的装填 ,这通过 int __cxa_atexit(void (*destructor) (void *), void *arg, void *__dso_handle) 函数完成,其三个参数分别为:析构函数指针、待析构对象、一个特殊的标记值(对我们来说可以不用管)
因此我们只需要自行实现一个 __cxa_at_exit 函数来记录析构器信息即可,为了实现动态的析构器数据记录,我们动态分配 dtor_info 结构体来记录待析构对象的信息,并将其链接为单向链表:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 struct dtor_info {struct dtor_info *next;void (*destructor) (void *);void *arg;void *__dso_handle;struct dtor_info *global_dtors = nullptr ;int __cxa_atexit(void (*destructor) (void *), void *arg, void *__dso_handle)struct dtor_info *new_info;new struct dtor_info;if (new_info == nullptr ) {return -ENOMEM;return 0 ;
此外,我们还需要定义一个 __dso_handle 变量,并导出到我们的 cpp_base.hpp 中:
1 void * __dso_handle __attribute__((visibility ("hidden" )));
接下来是对析构器的调用,在 C++ ABI 规范中,对这些析构器的调用应当由 void __cxa_finalize ( void *__dso_handle) 函数完成,其应当将析构器条目的 __dso_handle 与其参数进行对比,相等则调用析构器(若传参为空则应当调用所有析构器)并将对应的条目无效化,因此在我们的 ClosureOS 内核中也应当实现一个 __cxa_finalize() 函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 lib::atomic::SpinLock dtor_exit_lock;void __cxa_finalize(void * dso_handle)struct dtor_info **pdtor = &global_dtors;Lock ();while (*pdtor) {struct dtor_info *dtor = *pdtor;if (!dso_handle || dtor->__dso_handle == dso_handle) {destructor (dtor->arg);delete dtor;else {UnLock ();
需要注意的是 这个函数应当在程序退出时进行手动调用 ,由于我们尚未编写电源管理模块,因此本章所涉及的代码不会调用该函数
纯虚函数 虚函数是 C++ 的一个特性,简而言之其中的纯虚函数是一个类似占位符的存在,当程序调用纯虚函数时程序会报错,在内核环境中我们并没有各种库因此我们需要实现相应的 error handler
对于 GCC 而言,这个 error handler 应当为 __cxa_pure_virtual() 函数,因此我们只需要在我们的内核中实现该函数即可, 目前我们暂且留空 ,在后续完成内核输出功能后再添加上类似 printk() 的报错信息输出:
1 2 3 4 5 6 extern "C" void __cxa_pure_virtual()
0xFF. Reference 【OS.0x03】Linux内核内存管理II - Buddy System
【OS.0x04】Linux 内核内存管理浅析 III - Slub Allocator
Linux SLUB Allocator Internals and Debugging, Part 1 of 4
C++ - OS Dev
Calling Global Constructors - OS Dev
Itanium C++ ABI
Linux Foundation - Executable and Linking Format (ELF) Specification
AMD64 Architecture Programmer’s Manual Volume 2