本文最后更新于:2023年12月18日 早上
别人问你哪里丑态你再把他反手挂到自己的小 slub 里寻求认同
0x00.一切开始之前
因为这系列文章🕊🕊🕊太久了,内核的内存管理也发生了一定的变化,所以本文直接用最新的 6.2 版本的内核源码:)
在上一篇文章 中笔者简要介绍了 buddy system 的基本流程,但其为一个「页」这一级的 allocator,在日常生活中使用(?)难免有些浪费,因为内核中需要动态内存分配的场景虽然很多,但是我们通常并不需要使用一整页起步的内存,而往往是需要分配一些比较小的对象 ——因此 slab allocator 应运而生,其代替我们向 buddy system 请求内存页,并分割为多个小的 object,当我们每次需要时只需要取一个 object 即可
slab 又被称为内核的堆(heap)内存管理,因为其与用户态的内存“堆”(heap)类似,都是动态分配的内存
slab allocator 一共有三种版本:
slab(最初的版本,机制比较复杂,效率不高)
slob(用于嵌入式等场景的极为简化版本)
slub (优化后的版本,现在的通用版本 )
这三种内存分配器的顶层 API 是一致的,但内部实现是不一致的(例如 slab 和 slub 各自有一个对 kmem_cache 的不同定义)
本篇文章中我们主要介绍的是 slub ,也是现在内核中最为通用的小对象分配器
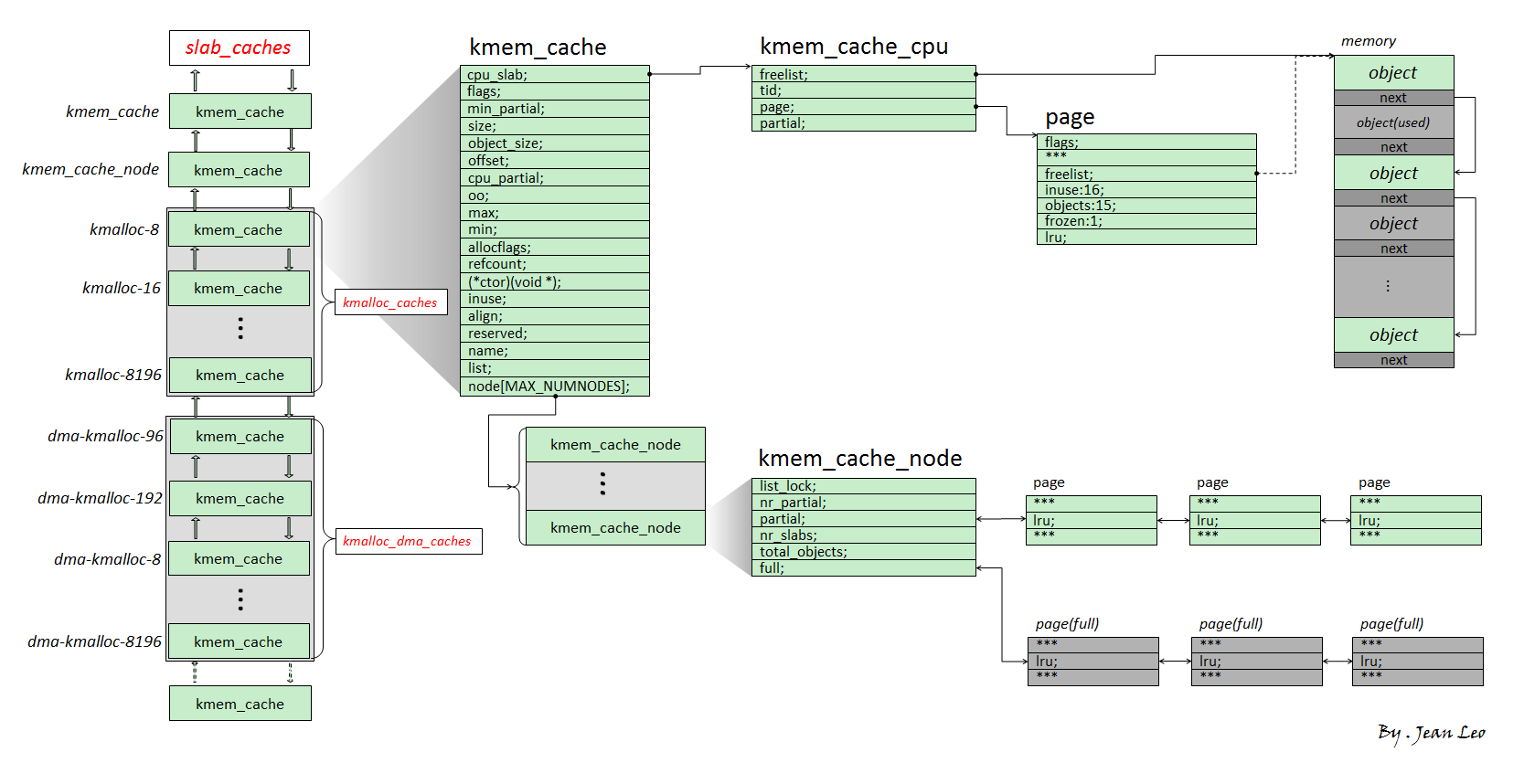
0x01. slub allocator 的基本结构 首先来一张 Overview:
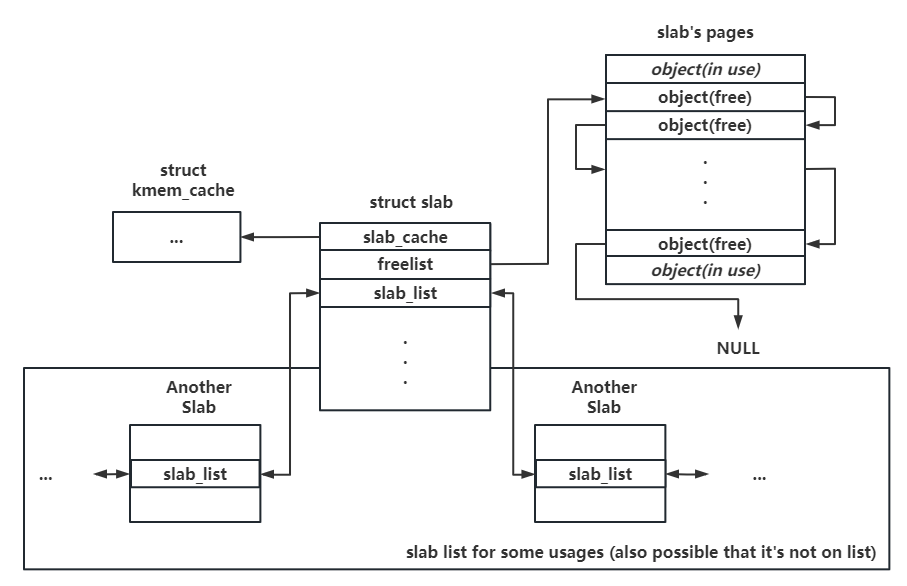
一、slab:单份 object 池 Linux kernel 中用以统筹所有内存的依然是 buddy system,slub allocator 也不例外,其负责向 buddy system 请求内存后分割给多个小 object 后再返还给上层调用者,单次向 buddy system 所请求的一份连续内存页便称之为一张 slab ,在内核中对应 slab 结构体,本质上是复用 page 结构体 :
这里我们仅关注 slub,所以笔者仅截取 slub 所需字段
老版本中 slab 是直接内嵌在 page 结构体中的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 struct slab {unsigned long __page_flags;#elif defined(CONFIG_SLUB) struct kmem_cache *slab_cache ;union {struct {union {struct list_head slab_list ;#ifdef CONFIG_SLUB_CPU_PARTIAL struct {struct slab *next ;int slabs; #endif void *freelist; union {unsigned long counters;struct {unsigned inuse:16 ;unsigned objects:15 ;unsigned frozen:1 ;struct rcu_head rcu_head ;unsigned int __unused;atomic_t __page_refcount;#ifdef CONFIG_MEMCG unsigned long memcg_data;#endif
slab_cache :该 slab 对应的内存池freelist :Slab 上的空闲对象组织为一个 NULL 结尾的单向链表 ,该指针指向第一个空闲对象,耗尽时为 NULLslab_list :按用途连接多个 slabs 的双向链表inuse :已被使用的对象数量objects:该 slab 上的对象总数frozen:是否被冻结,即已经归属于特定的 CPU
这里我们需要注意的是 counters 成员直接涵盖了 inuse & objects & frozen ,后面会有大量的直接通过 counters 成员进行赋值的操作,实际上就是赋值了 inuse & objects & frozen
正如一个 page 结构体直接对应一张内存页(或复合页),复用了 page 结构体的 slab 也直接对应一份 slab 内存页 ,借助 page_to_pfn() 等函数可以直接完成 slab 结构体到对应内存页虚拟地址的转换,反之亦然,即我们可以直接通过一个空闲对象的虚拟地址找到对应的 slab 结构体
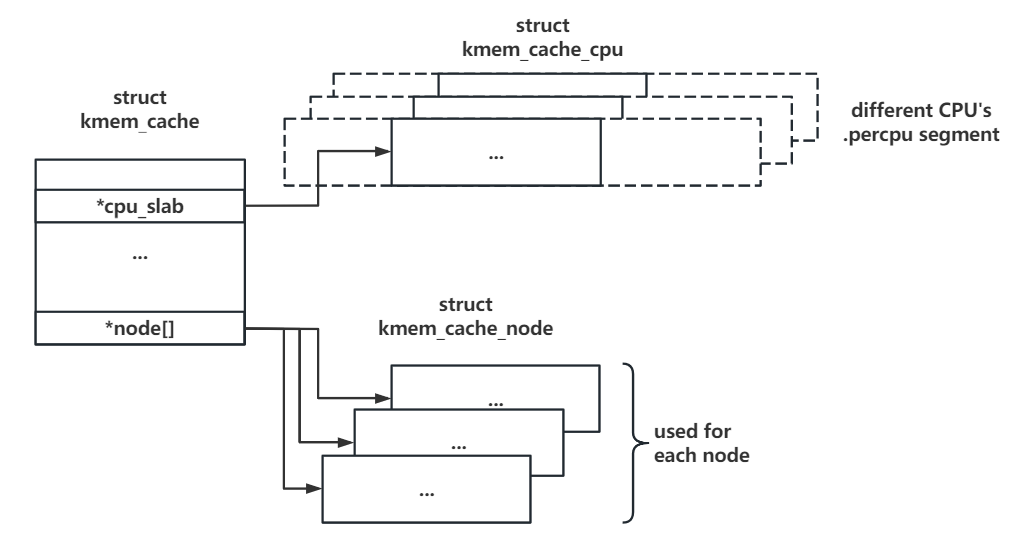
二、kmem_cache:特定大小&用途对象(堆块)的内存池 kmem_cache 为一个基本的 allocator 组件,可以理解为 用于分配某个特定大小(某种特定用途)的对象的内存池 ,所有的 kmem_cache 构成一个双向链表,并存在一个对应的通用 kmem_cache 数组 kmalloc_caches
1 2 3 4 struct kmem_cache *kmalloc_caches [NR_KMALLOC_TYPES ][KMALLOC_SHIFT_HIGH + 1] __ro_after_init =
老版本还有个 dma 专用数组 kmalloc_dma_caches ,在 这个 commit 给合并起来了
I. 基本结构 该结构体定义于 include/linux/slub_def.h 中,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 struct kmem_cache {#ifndef CONFIG_SLUB_TINY struct kmem_cache_cpu __percpu *cpu_slab ;#endif slab_flags_t flags;unsigned long min_partial;unsigned int size; unsigned int object_size;struct reciprocal_value reciprocal_size ;unsigned int offset; #ifdef CONFIG_SLUB_CPU_PARTIAL unsigned int cpu_partial;unsigned int cpu_partial_slabs;#endif struct kmem_cache_order_objects oo ;struct kmem_cache_order_objects min ;gfp_t allocflags; int refcount; void (*ctor)(void *);unsigned int inuse; unsigned int align; unsigned int red_left_pad; const char *name; struct list_head list ;#ifdef CONFIG_SYSFS struct kobject kobj ;#endif #ifdef CONFIG_SLAB_FREELIST_HARDENED unsigned long random; #endif #ifdef CONFIG_NUMA unsigned int remote_node_defrag_ratio;#endif #ifdef CONFIG_SLAB_FREELIST_RANDOM unsigned int *random_seq; #endif #ifdef CONFIG_KASAN struct kasan_cache kasan_info ;#endif #ifdef CONFIG_HARDENED_USERCOPY unsigned int useroffset; unsigned int usersize; #endif struct kmem_cache_node *node [MAX_NUMNODES ];
cpu_slab: percpu 变量 ,指向一个 kmem_cache_cpu 结构体,即当前 CPU 独占的内存池
flags:标志位
min_partial:node partial 链表上 slab 的最大数量 (👴也不知道为什么要叫min,但实际判定发挥的是max的作用)
cpu_partial_slabs:cpu partial 链表上 slab 的最大数量
cpu_partial:per cpu partial list 中最多的对象数量(但好象是没啥用)
size:一个对象的实际大小
object_size:一个对象所用数据的大小
例如 struct cred 大小为 176(object_size),实际分配的对象大小为 192 (size)
offset:slab 上空闲对象链表指针在对象上的偏移
oo : 其实就是一个 int
低 16 位:一张 slab 上的对象数量
高 16 位:一张 slab 的大小(2n 张内存页)
min:一张 slab 上最少的对象数量
allocflags:向 buddy system 请求页面时所用的 gfp flag
ctor:对象的构造函数,在分配对象后会调用该函数进行初始化
inuse:实际上就是 object_size
align:对象对齐的宽度
Randomed freelist 保护相关:
random_seq :用于在 slab 初始化时随机化 freelist 上空闲对象的连接顺序
Hardened Usercopy 保护相关
useroffset:用户空间能读写区域的起始偏移usersize:用户空间能读写区域的大小
node:一个 kmem_cache_node 数组,对应多个不同 node 的后备内存池
II. 类型 初始时一共有如下几种类型的 kmem_cache,在进行内存分配时若未指定内存池则会根据对应的 flag 从不同的 kmem_cache 中取:
KMALLOC_NORMAL :通用类型内存池,对应 kmalloc-*,对应分配 flag 为 GFP_KERNELKMALLOC_DMA:用于 DMA 的内存池,对应 kmalloc-dma-*KMALLOC_RECLAIM 可以被回收的内存池,对应 kmalloc-rcl-*KMALLOC_CGROUP :用于需要进行数量统计(accounted,主要用于 CGROUP 相关)的内存池,对应 kmalloc-cg-* ,对应分配 flag 为 GFP_KERNEL_ACCOUNT
若是未开启对应的编译选项,则默认合并入 KMALLOC_NORMAL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 enum kmalloc_cache_type {0 ,#ifndef CONFIG_ZONE_DMA #endif #ifndef CONFIG_MEMCG_KMEM #endif #ifdef CONFIG_SLUB_TINY #else #endif #ifdef CONFIG_ZONE_DMA #endif #ifdef CONFIG_MEMCG_KMEM #endif
III. slab alias(mergeability) slab alias 机制是一种对同等/相近大小 object 的 kmem_cache 进行复用 的一种机制:
当一个 kmem_cache 在创建时,若已经存在能分配相等/近似大小的 object 的 kmem_cache ,则不会创建新的 kmem_cache,而是为原有的 kmem_cache 起一个 alias,作为“新的” kmem_cache 返回
举个🌰,cred_jar 是专门用以分配 cred 结构体的 kmem_cache,在 Linux 4.4 之前的版本中,其为 kmalloc-192 的 alias,即 cred 结构体与其他的 192 大小的 object 都会从同一个 kmem_cache——kmalloc-192 中分配
对于初始化时设置了 SLAB_ACCOUNT 这一 flag 的 kmem_cache 而言,则会新建一个新的 kmem_cache 而非为原有的建立 alias,🌰如在新版的内核当中 cred_jar 与 kmalloc-192 便是两个独立的 kmem_cache,彼此之间互不干扰
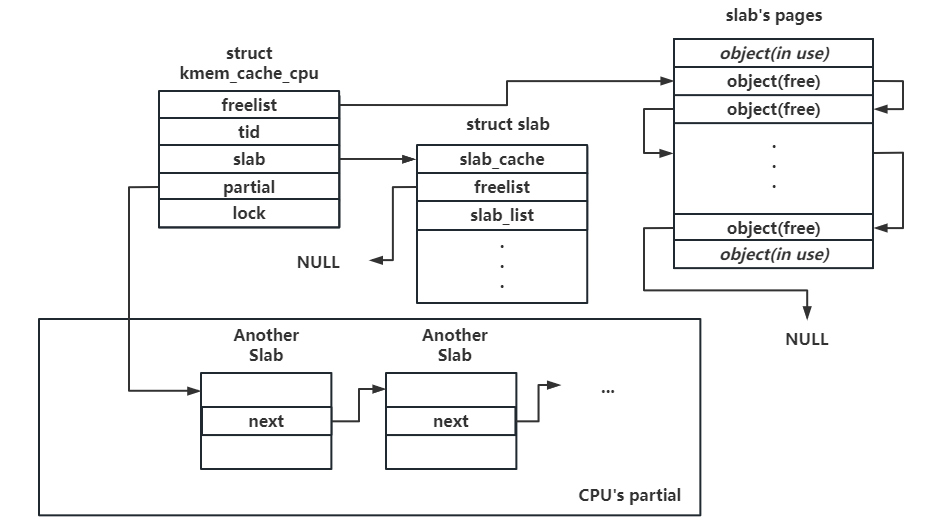
三、kmem_cache_cpu:各 CPU 独占内存池 当进程向 slab allocator 请求内存分配时,首先会尝试从当前 CPU 的独占内存池进行分配 ——kmem_cache_cpu 结构体表示每个 CPU 独占的内存池 ,其在 kmem_cache 中为一个 percpu 变量:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct kmem_cache_cpu {void **freelist; unsigned long tid; struct slab *slab ;#ifdef CONFIG_SLUB_CPU_PARTIAL struct slab *partial ;#endif local_lock_t lock; #ifdef CONFIG_SLUB_STATS unsigned stat[NR_SLUB_STAT_ITEMS];#endif
freelist:指向下一个空闲对象的指针slab:当前用以进行内存分配的 slabpartial:percpu partial slab 链表,链表上为仍有一定空闲对象的 slab
slab 的 freelist 仅当其在 partial 链表上时有用,当一张 slab 为当前 CPU 正在使用的 slab 时,其 freelist 为 NULL,由 kmem_cache_cpu.freelist 指向第一个空闲对象
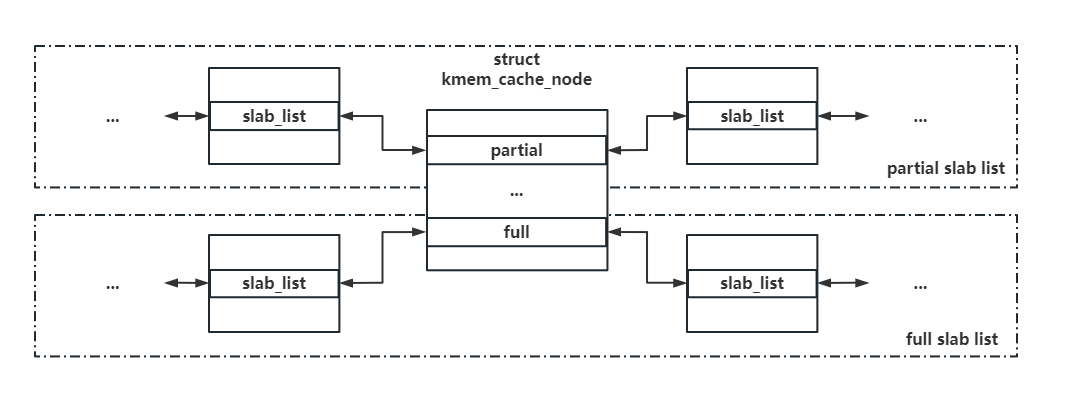
四、kmem_cache_node:各 node 后备内存池 每个 node 对应的后备内存池 ,当 percpu 的独占内存池耗尽后便会从对应 node 的后备内存池尝试分配
不过大部分计算机都仅有一个 node,所以通常情况下每个 kmem_cache 也就只有一个 kmem_cache_node 😄
因为本文主要讲 slub,所以仅截取 slub 相关字段:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #ifndef CONFIG_SLOB struct kmem_cache_node {#ifdef CONFIG_SLAB #endif #ifdef CONFIG_SLUB spinlock_t list_lock;unsigned long nr_partial;struct list_head partial ;#ifdef CONFIG_SLUB_DEBUG atomic_long_t nr_slabs;atomic_long_t total_objects;struct list_head full ;#endif #endif
list_lock:保护 partial 和 full 链表的锁partial:partial slab 链表,连接有着部分空闲对象剩余的 slab nr_partial:partial slab 的数量full:full slab 链表,连接空闲对象完全耗尽的 slab (注:该链表基本上不常用)nr_slabs:总的 slab 数量total_objects:总的对象数量
0x02. 对象的分配 ※ 一、slab_alloc_node():从指定的 kmem_cache 分配 object 在 slab allocator 中存在着多个不同的内存分配接口,其最后都会调用到 slab_alloc_node() 完成内存分配的工作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 static __fastpath_inline void *slab_alloc_node (struct kmem_cache *s, struct list_lru *lru, gfp_t gfpflags, int node, unsigned long addr, size_t orig_size) void *object;struct obj_cgroup *objcg =NULL ;bool init = false ;
该函数首先会调用 slab_pre_alloc_hook() 进行分配前的检查工作,不通过则返回 NULL,这一步主要是检查分配标志位是否合法等:
1 2 3 s = slab_pre_alloc_hook(s, lru, &objcg, 1 , gfpflags);if (!s)return NULL ;
接下来调用 kfence_alloc() 进行内存错误检测,不通过则直接跳转到 out,这里用到了 Kfence (Kernel Electric Fence) 内存纠错机制,主要是检查对 data page 的访问是否越界:
1 2 3 object = kfence_alloc(s, orig_size, gfpflags);if (unlikely(object))goto out;
接下来调用 __slab_alloc_node() 进行正式的内存分配,这一步便是真正的核心分配函数 :
1 object = __slab_alloc_node(s, gfpflags, node, addr, orig_size);
最后调用 maybe_wipe_obj_freeptr() 将 object 原本存放 next free object 指针的位置清零,之后调用 slab_want_init_on_alloc() 检查标志位是否有 __GFP_ZERO,若有则调用 slab_post_alloc_hook() 将 object 上数据清零
1 2 3 4 5 6 7 8 9 10 11 12 maybe_wipe_obj_freeptr(s, object);1 , &object, init, orig_size);return object;
接下来我们来看真正的核心分配函数 __slab_alloc_node()
I. __slab_alloc_node():从 percpu freelist 进行分配(fast path) 该函数首先会先获取 percpu 的 kmem_cache_cpu 上的 freelist 与 slab,若 slab 或 freelist 为空 / slab 与 node 不匹配,则调用 __slab_alloc() 分配一张新 slab 并从其中获取一个空闲对象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 static __always_inline void *__slab_alloc_node(struct kmem_cache *s,gfp_t gfpflags, int node, unsigned long addr, size_t orig_size)struct kmem_cache_cpu *c ;struct slab *slab ;unsigned long tid;void *object;if (!USE_LOCKLESS_FAST_PATH() ||
若有 freelist & slub,则调用 get_freepointer_safe() 获取当前空闲对象下一个空闲对象 ;接下来 this_cpu_cmpxchg_double() 会检查是否 freelist == object、cpu_slab->tid == tid,若是则将 freelist 设为 next_object 并获取设置下一 tid ,否则说明发生了抢占(我们已经不在原 cpu 上了),跳转回 redo 重新在当前 cpu 上进行分配:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 } else {void *next_object = get_freepointer_safe(s, object);if (unlikely(!this_cpu_cmpxchg_double("slab_alloc" , s, tid);goto redo;
最后对于直接从 cpu_slab 上分配的对象会通过 prefetch_freepointer() 调用 prefetchw 指令提前将已分配对象的地址载入缓存中,之后就是返回分配成功的空闲对象
1 2 3 4 5 6 prefetch_freepointer(s, next_object);return object;
II. ___slab_alloc():获取另一 slab 进行分配(slow path) __slab_alloc() 其实是在开启了抢占的情况下(默认开启)对 ___slab_alloc() 的一个简单的 wrapper,主要就是重新读取 kmem_cache_cpu 的指针:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 static void *__slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,unsigned long addr, struct kmem_cache_cpu *c, unsigned int orig_size)void *p;#ifdef CONFIG_PREEMPT_COUNT #endif #ifdef CONFIG_PREEMPT_COUNT #endif return p;
接下来我们来看 ___slab_alloc(),该函数便是慢速分配路径的核心函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,unsigned long addr, struct kmem_cache_cpu *c, unsigned int orig_size)void *freelist;struct slab *slab ;unsigned long flags;struct partial_context pc ;
接下来笔者按照代码标签顺序进行分析
① reread_slab:读取 percpu slab 首先读取 percpu 的 slab,若没有 slab 则判断分配节点,并跳转到 new_slab 分配新的 slab,注意这一块代码对应 reread_slab 标签:
1 2 3 4 5 6 7 8 9 10 11 12 reread_slab:if (!slab) {if (unlikely(node != NUMA_NO_NODE &&goto new_slab;
② redo:获取 percpu slab->freelist 接下来这块代码对应 redo 标签:
若 percpu slab 不为空,判断 slab 是否属于指定的节点且与分配标志位匹配,若否,则跳转到 deactivate_slab 标签
接下来检查 slab 是否仍为原来的 cpu slab(因为我们可能被抢占),若否,则跳转回 reread_slab
接下来获取 per-cpu 的 freelist,若不为空,则跳转到 load_freelist,否则调用 get_freelist() 获取 slab 的 freelist
若 slab 的 freelist 仍为空,将 per-cpu freelist 设为 NULL,获取下一个 tid,并跳转到 new_slab 分配新的 slab
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 redo:if (unlikely(!node_match(slab, node))) {if (!node_isset(node, slab_nodes)) {else {goto deactivate_slab;if (unlikely(!pfmemalloc_match(slab, gfpflags)))goto deactivate_slab;if (unlikely(slab != c->slab)) {goto reread_slab;if (freelist)goto load_freelist;if (!freelist) {NULL ;goto new_slab;
get_freelist() 函数主要就是获取 slab->freelist 后将 slab->freelist 设为 NULL 并返回原来的 freelist
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 static inline void *get_freelist (struct kmem_cache *s, struct slab *slab) struct slab new ;unsigned long counters;void *freelist;do {NULL ;while (!__cmpxchg_double_slab(s, slab,NULL , new.counters,"get_freelist" ));return freelist;
③ load_freelist:从 freelist 分配对象 继续返回 ___slab_alloc() 中,接下来这块代码对应 load_freelist 标签,主要就是调用 get_freepointer() 将 percpu freelist 指向第二个空闲对象,并获取下一个 tid 后返回前面获取的 freelist(也就是第一个空闲对象):
1 2 3 4 5 6 7 8 9 10 11 12 13 load_freelist:return freelist;
这里注意在 get_freepointer() 里套了两层,最后会调用到 freelist_ptr() 获取到第二个空闲对象的指针,这里需要注意的是当开启了 Hardened freelist 保护后在 next 指针的位置存放的是 第一个空闲对象地址 ^ 第二个空闲对象地址 ^ 一个随机值 (kmem_cache->random):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 static inline void *freelist_ptr (const struct kmem_cache *s, void *ptr, unsigned long ptr_addr) #ifdef CONFIG_SLAB_FREELIST_HARDENED return (void *)((unsigned long )ptr ^ s->random ^unsigned long )kasan_reset_tag((void *)ptr_addr)));#else return ptr;#endif
从这里我们也可以看出 slab->freelist 是没有加密的,但链表上的后续指针都是加密了的
④ deactivate_slab:deactivate percpu slab 继续返回 ___slab_alloc() 中,接下来这块代码对应 deactivate_slab 标签,首先还是惯例地检查是否被抢占调度到了别的 CPU,若是则跳转回 reread_slab;之后就是简单地将 percpu 的 slab 和 freelist 设为 NULL 并获取下一个 tid,之后调用 deactivate_slab() 将这张 slab 给 deactivate 了:
1 2 3 4 5 6 7 8 9 10 11 12 13 deactivate_slab:if (slab != c->slab) {goto reread_slab;NULL ;NULL ;
deactivate_slab() 的逻辑如下:
遍历 freelist 检查是否被破坏,放弃被破坏的部分
将 slab->freelist 设为原 kmem_cache_cpu->freelist,若 slab 上原有 freelist 不为 NULL 则再接到后面
设置 slab 的 counters,其中将 frozen 设为 0
若 slab 上的对象全部空闲**且 node 的 partial slab 数量大于 kmem_cache->min_partial**,调用 discard_slab() 将 slab 释放
若 slab 上存在空闲对象,调用 add_partial() 将其加入 node 的 partial 链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 static void deactivate_slab (struct kmem_cache *s, struct slab *slab, void *freelist) enum slab_modes {struct kmem_cache_node *n =int free_delta = 0 ;enum slab_modes mode =void *nextfree, *freelist_iter, *freelist_tail;int tail = DEACTIVATE_TO_HEAD;unsigned long flags = 0 ;struct slab new ;struct slab old ;if (slab->freelist) {NULL ;while (freelist_iter) {if (freelist_corrupted(s, slab, &freelist_iter, nextfree))break ;if (freelist_tail) {else 0 ;if (!new.inuse && n->nr_partial >= s->min_partial) {else if (new.freelist) {else {if (!cmpxchg_double_slab(s, slab,"unfreezing slab" )) {if (mode == M_PARTIAL)goto redo;if (mode == M_PARTIAL) {else if (mode == M_FREE) {else if (mode == M_FULL_NOLIST) {
④ new_slab:获取 percpu partial slab 接下来是 new_slab 标签,主要就是检查若有 percpu partial slab 则从 percpu partial 链表上获取一个 slab 将其设为 percpu slab 后 再跳转回 redo 标签:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 new_slab:if (slub_percpu_partial(c)) {if (unlikely(c->slab)) {goto reread_slab;if (unlikely(!slub_percpu_partial(c))) {goto new_objects;goto redo;
⑤ new_objects:获取 node pertial slab 或向 buddy 请求新 slab 进行分配 若 percpu partial 链表也为空,那么便来到接下来的 new_objects 标签分配一个新的 slab,首先会设置 partial_context,调用 get_partial() 尝试从 kmem_cache_node 的 partial 链表分配一个 slab,若分配成功则直接跳转到 check_new_slab
1 2 3 4 5 6 7 8 9 new_objects:if (freelist)goto check_new_slab;
get_partial() 首先会调用 get_partial_node() 从当前 node 的 kmem_cache_node 的 partial 链表分配 slab,若成功了则直接返回,如果失败了但是指定了分配的 node 为 NUMA_NO_NODE,则调用 get_any_partial() 从其他的 kmem_cache_node 的 partial 链表尝试分配:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 static void *get_partial (struct kmem_cache *s, int node, struct partial_context *pc) void *object;int searchnode = node;if (node == NUMA_NO_NODE)if (object || node != NUMA_NO_NODE)return object;return get_any_partial(s, pc);
若 get_partial() 没法获取到 slab,则调用 new_slab() 向 buddy system 请求一份新的 slab,若失败了则直接返回:
1 2 3 4 5 6 7 8 9 10 slub_put_cpu_ptr(s->cpu_slab);if (unlikely(!slab)) {return NULL ;
new_slab() 最后会调用到 allocate_slab():
首先检查页面分配标志位,之后调用 alloc_slab_page() 在指定 node 上进行分配
若 node == NUMA_NO_NODE,则该函数会调用 alloc_pages(),否则会调用 __alloc_pages_node()
若失败了则再次调用 alloc_slab_page() 尝试进行最小内存分配(kmem_cache->min),仍失败则直接返回 NULL
初始化 slab 各成员,并调用 shuffle_freelist() 为空闲对象构造随机化链表,若未开启随机化则将空闲对象按顺序连接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 static struct slab *allocate_slab (struct kmem_cache *s, gfp_t flags, int node) struct slab *slab ;struct kmem_cache_order_objects oo =gfp_t alloc_gfp;void *start, *p, *next;int idx;bool shuffle;if ((alloc_gfp & __GFP_DIRECT_RECLAIM) && oo_order(oo) > oo_order(s->min))if (unlikely(!slab)) {if (unlikely(!slab))return NULL ;0 ;0 ;if (!shuffle) {for (idx = 0 , p = start; idx < slab->objects - 1 ; idx++) {NULL );return slab;
这里用了一个函数 set_freepointer(),主要就是用 freelist_ptr() 向 object + s->offset 的位置写入用 freelist_ptr() 加密后的 fp 指针:
1 2 3 4 5 6 7 8 9 10 11 static inline void set_freepointer (struct kmem_cache *s, void *object, void *fp) unsigned long freeptr_addr = (unsigned long )object + s->offset;#ifdef CONFIG_SLAB_FREELIST_HARDENED #endif unsigned long )kasan_reset_tag((void *)freeptr_addr);void **)freeptr_addr = freelist_ptr(s, fp, freeptr_addr);
返回 ___slab_alloc(),如果该 kmem_cache 设置了 SLAB_DEBUG_FLAGS 标志位 ,则接下来会调用 alloc_single_from_new_slab() 从新获取到的 slab 上分配一个对象后将 slab 重新挂回 partial/full 链表 ,若分配失败则跳转回 new_objects,成功则直接返回
1 2 3 4 5 6 7 8 9 10 11 if (kmem_cache_debug(s)) {if (unlikely(!freelist))goto new_objects;if (s->flags & SLAB_STORE_USER)return freelist;
如果没有设置 SLAB_DEBUG_FLAGS 标志位,则接下来获取 slab 的 freelist,并调用 inc_slabs_node() 增加 node 上的计数
1 2 3 4 5 6 7 8 9 10 NULL ;1 ;
⑥ check_new_slab:检查 slab 接下来对新获取的 slab 进行检查,若该 kmem_cache 设置了 SLAB_DEBUG_FLAGS 标志位,检查是否设置了 SLAB_STORE_USER 标志位,之后直接返回 freelist
接下来调用 pfmemalloc_match() 检查 slab 与分配标志位是否不匹配,若是则调用 deactivate_slab() 使其不再活动并返回 freelist
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 check_new_slab:if (kmem_cache_debug(s)) {if (s->flags & SLAB_STORE_USER)return freelist;if (unlikely(!pfmemalloc_match(slab, gfpflags))) {return freelist;
⑦ retry_load_slab: 最后就是尝试加载新获得的 slab,如果 percpu slab 不为 NULL 则使其不再活动,并设置 percpu slab & freelist 为 NULL,并获取下一个 tid
最后就是将 percpu slab 设为新获取的 slab 并跳转回 load_freelist 分配对象并返回
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 retry_load_slab:if (unlikely(c->slab)) {void *flush_freelist = c->freelist;struct slab *flush_slab =NULL ;NULL ;goto retry_load_slab;goto load_freelist;
至此, slub 分配算法的核心逻辑分析结束
二、kmalloc: NUMA_NO_NODE 的通用上层分配接口 我们日常生活中(?)最常用的其实还是 kmalloc(),其会根据分配的大小与标志位帮我们完成 kmem_cache 的选取并进行对象分配
函数整体逻辑比较简单:
若分配的大小在编译期已知(__builtin_constant_p())则判断大小:
若大小大于 KMALLOC_MAX_CACHE_SIZE 则使用 kmalloc_large() 进行分配
通过 kmalloc_index() 与 kmalloc_type() 获取 kmalloc_caches 中对应的数组下标并调用 kmalloc_trace 进行对象分配
若大小是动态传入的,调用 __kmalloc() 进行分配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 #ifndef CONFIG_SLOB static __always_inline __alloc_size(1 ) void *kmalloc (size_t size, gfp_t flags) if (__builtin_constant_p(size) && size) {unsigned int index;if (size > KMALLOC_MAX_CACHE_SIZE)return kmalloc_large(size, flags);return kmalloc_trace(return __kmalloc(size, flags);
I. kmalloc_large():直接向 buddy system 请求内存 对于请求大小大于 KMALLOC_MAX_CACHE_SIZE 的内存分配请求而言, kmalloc() 会直接调用 kmalloc_large() 完成内存分配,最后实际上会在 __kmalloc_large_node() 调用 alloc_pages() 向 buddy system 请求内存:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 static void *__kmalloc_large_node(size_t size, gfp_t flags, int node)struct page *page ;void *ptr = NULL ;unsigned int order = get_order(size);if (unlikely(flags & GFP_SLAB_BUG_MASK))if (page) {1 , flags);return ptr;void *kmalloc_large (size_t size, gfp_t flags) void *ret = __kmalloc_large_node(size, flags, NUMA_NO_NODE);return ret;
II. __kmalloc_index():获取size对应下标 kmalloc_index() 其实就是 __kmalloc_index(),根据请求的大小返回对应的下标,整体逻辑非常简单粗暴:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 static __always_inline unsigned int __kmalloc_index(size_t size,bool size_is_constant)if (!size)return 0 ;if (size <= KMALLOC_MIN_SIZE)return KMALLOC_SHIFT_LOW;if (KMALLOC_MIN_SIZE <= 32 && size > 64 && size <= 96 )return 1 ;if (KMALLOC_MIN_SIZE <= 64 && size > 128 && size <= 192 )return 2 ;if (size <= 8 ) return 3 ;if (size <= 16 ) return 4 ;if (size <= 32 ) return 5 ;if (size <= 64 ) return 6 ;if (size <= 128 ) return 7 ;if (size <= 256 ) return 8 ;if (size <= 512 ) return 9 ;if (size <= 1024 ) return 10 ;if (size <= 2 * 1024 ) return 11 ;if (size <= 4 * 1024 ) return 12 ;if (size <= 8 * 1024 ) return 13 ;if (size <= 16 * 1024 ) return 14 ;if (size <= 32 * 1024 ) return 15 ;if (size <= 64 * 1024 ) return 16 ;if (size <= 128 * 1024 ) return 17 ;if (size <= 256 * 1024 ) return 18 ;if (size <= 512 * 1024 ) return 19 ;if (size <= 1024 * 1024 ) return 20 ;if (size <= 2 * 1024 * 1024 ) return 21 ;if (!IS_ENABLED(CONFIG_PROFILE_ALL_BRANCHES) && size_is_constant)1 , "unexpected size in kmalloc_index()" );else return -1 ;
III. kmalloc_types():获取标志位对应类型 kmalloc_type() 其实主要就是根据标志位返回类型,除了指定了 __GFP_DMA/__GFP_RECLAIMABLE/__GFP_ACCOUNT 以外就都是 KMALLOC_NORMAL:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 static __always_inline enum kmalloc_cache_type kmalloc_type (gfp_t flags) if (likely((flags & KMALLOC_NOT_NORMAL_BITS) == 0 ))return KMALLOC_NORMAL;if (IS_ENABLED(CONFIG_ZONE_DMA) && (flags & __GFP_DMA))return KMALLOC_DMA;if (!IS_ENABLED(CONFIG_MEMCG_KMEM) || (flags & __GFP_RECLAIMABLE))return KMALLOC_RECLAIM;else return KMALLOC_CGROUP;
IV. kmalloc_trace():常规大小的 NUMA_NO_NODE 对象分配 kmalloc_trace() 主要是对 __kmem_cache_alloc_node() 的 wrapper,加上 tracepoint 和 kasan 的相关设置,需要注意的是这里会指定 node 为 NUMA_NO_NODE:
不知道什么是 kernel trace point 的可以参见 这里
1 2 3 4 5 6 7 8 9 10 11 void *kmalloc_trace (struct kmem_cache *s, gfp_t gfpflags, size_t size) void *ret = __kmem_cache_alloc_node(s, gfpflags, NUMA_NO_NODE,return ret;
__kmem_cache_alloc_node() 其实就是 slab_alloc_node() 的 wrapper:
1 2 3 4 5 6 7 void *__kmem_cache_alloc_node(struct kmem_cache *s, gfp_t gfpflags,int node, size_t orig_size,unsigned long caller)return slab_alloc_node(s, NULL , gfpflags, node,
V. __kmalloc():常规大小的 NUMA_NO_NODE 对象分配 __kmalloc() 其实就是指定 node 为 NUMA_NO_NODE 的 __do_kmalloc_node() :
1 2 3 4 5 void *__kmalloc(size_t size, gfp_t flags)return __do_kmalloc_node(size, flags, NUMA_NO_NODE, _RET_IP_);
VI. __do_kmalloc_node():判断所需 kmem_cache 并进行对象分配 该函数的主要逻辑为:
若 size > KMALLOC_MAX_CACHE_SIZE ,则调用 __kmalloc_large_node() 进行分配,并进行 tracepoint 与 kasan 相关设置
对于常规 size:
首先调用 kmalloc_slab() 获取对应的 kmem_cache
接下来调用 __kmem_cache_alloc_node() 进行内存分配
最后进行 tracepoint 与 kasan 相关设置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 static __always_inlinevoid *__do_kmalloc_node(size_t size, gfp_t flags, int node, unsigned long caller)struct kmem_cache *s ;void *ret;if (unlikely(size > KMALLOC_MAX_CACHE_SIZE)) {return ret;if (unlikely(ZERO_OR_NULL_PTR(s)))return s;return ret;
kmalloc_slab() 中寻找 kmem_cache 的过程和 kmalloc 类似,不过寻找下标用的是 size_index[size_index_elem(size)] 和 fls() :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 struct kmem_cache *kmalloc_slab (size_t size, gfp_t flags) unsigned int index;if (size <= 192 ) {if (!size)return ZERO_SIZE_PTR;else {if (WARN_ON_ONCE(size > KMALLOC_MAX_CACHE_SIZE))return NULL ;1 );return kmalloc_caches[kmalloc_type(flags)][index];
size_index 和 size_index_elem() 的定义都非常简单粗暴:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 static u8 size_index[24 ] __ro_after_init = {3 , 4 , 5 , 5 , 6 , 6 , 6 , 6 , 1 , 1 , 1 , 1 , 7 , 7 , 7 , 7 , 2 , 2 , 2 , 2 , 2 , 2 , 2 , 2 static inline unsigned int size_index_elem (unsigned int bytes) return (bytes - 1 ) / 8 ;
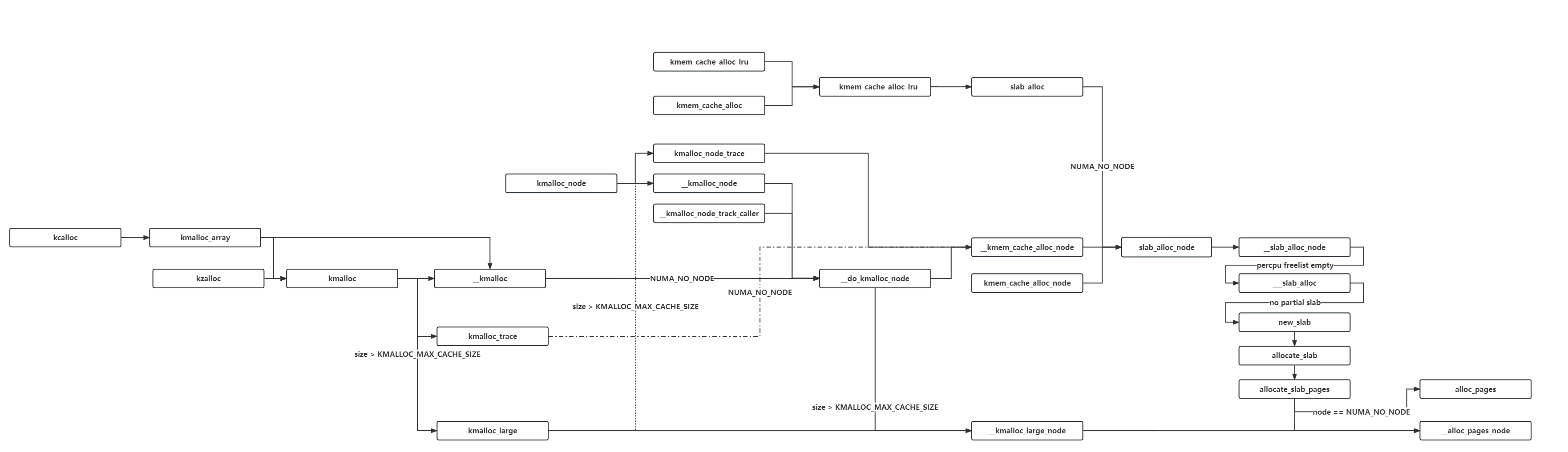
三、上层调用接口关系图 因为很多比如说 __kmem_cache_alloc_lru() 一类的函数其实最后都是对 slab_alloc_node() 的套娃,这里笔者直接给出一个简易的调用关系图:
只截取了笔者认为比较主要的那些,因为作图作到后面实在蚌埠住了
0x03. 对象的释放 ※ 一、do_slab_free():向指定的 kmem_cache 释放对象(链) 在 slab allocator 中存在着多个不同的内存释放接口,其最后都会调用到 do_slab_free() 完成内存释放的工作,需要注意的是该函数 允许释放已经连接成一条 freelist 且已经加密好的多个对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 static __always_inline void do_slab_free (struct kmem_cache *s, struct slab *slab, void *head, void *tail, int cnt, unsigned long addr) void *tail_obj = tail ? : head;struct kmem_cache_cpu *c ;unsigned long tid;void **freelist;
与分配类似,释放同样分为快速路径与慢速路径
I. 直接释放回 percpu slab(fast path) 快速路径比较简单,主要就是对比待释放对象所属 slab 是否为 percpu slab,若是则直接挂回去即可,遵循 LIFO 机制 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 redo:if (unlikely(slab != c->slab)) {return ;if (USE_LOCKLESS_FAST_PATH()) {if (unlikely(!this_cpu_cmpxchg_double("slab_free" , s, tid);goto redo;else {if (unlikely(slab != c->slab)) {goto redo;
II. __slab_free():释放回对应的 slab(slow path) 如果待释放对象不属于 percpu clab,则调用 __slab_free() 进行释放:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 static void __slab_free(struct kmem_cache *s, struct slab *slab,void *head, void *tail, int cnt,unsigned long addr)void *prior;int was_frozen;struct slab new ;unsigned long counters;struct kmem_cache_node *n =NULL ;unsigned long flags;
首先还是 kfence 和 debug 相关,如果该 kmem_cache 设置了 SLAB_DEBUG_FLAGS 标志位则直接调用 free_to_partial_list() 后返回即可:
1 2 3 4 5 6 7 if (kfence_free(head))return ;if (IS_ENABLED(CONFIG_SLUB_TINY) || kmem_cache_debug(s)) {return ;
之后是一个 do while 循环,首先会将 待释放 freelist 所属 slab 的 freelist待释放 freelist 的 tail objectnew 是一个栈上的临时 slab 结构体:
1 2 3 4 5 6 7 8 9 10 11 do {if (unlikely(n)) {NULL ;
接下来检查是否 (所有的对象都*将*为空闲对象 || 原 slab 上无空闲对象) && slab 未被冻结
检查是否有 percpu partial slab 且原 slab 上无空闲对象(即 slab->freelist(也就是代码中的 prior)为 NULL):
若是,则设置 slab 将被冻结(new.frozen=1)
若否,则获取 slab 所对应的 kmem_cache_node
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 if ((!new.inuse || !prior) && !was_frozen) {if (kmem_cache_has_cpu_partial(s) && !prior) {1 ;else {
循环的终止条件用了一个 cmpxchg_double_slab() 函数,套娃套得👴头昏眼花,主要逻辑为:
对比 slab->freelist == prior && slab->counters == counters,若是,则将 slab->freelist 设为 head 且将 slab->counters 设为 new.counters ,该操作成功则返回 true,条件不符则返回 false
成功了循环将会直接跳出:)
1 2 3 4 } while (!cmpxchg_double_slab(s, slab,"__slab_free" ));
接下来检查该 slab 是否需要从一个 kmem_cache_node 的链表上取下,若否, 则:
若 slab 已经被冻结,stat() 一下(基本上等于啥都不做)
若 slab 需要被冻结 (new.frozen 为 true),调用 put_cpu_partial() 直接将 slab 放到 percpu partial 链表
释放工作完成,返回
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 if (likely(!n)) {if (likely(was_frozen)) {else if (new.frozen) {1 );return ;
如果 slab 上所有对象都被释放,且 node 上的 partial slab 数量已经超过 kmem_cache->min_partial ,这意味着这是一张完全空闲的 slab ,接下来跳转到 slab_empty 标签,该标签对应代码块主要是:
若 slab 上原来有空闲对象(位于 node partial 链表),则从 partial 链表移除
若 slab 上原来无空闲对象(位于 node full 链表),则从 full 链表移除
最后调用 discard_slab() 释放这一张 slab
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 if (unlikely(!new.inuse && n->nr_partial >= s->min_partial))goto slab_empty;if (prior) {else {
若不满足上面的条件,则检查是否没有 percpu partial slab 且 slab 上原 freelist 为 NULL(即位于 node full 链表),若是则从 full 链表移除并添加到 node partial 链表
1 2 3 4 5 6 7 8 9 10 11 if (!kmem_cache_has_cpu_partial(s) && unlikely(!prior)) {return ;
至此, slub 算法的释放逻辑分析完毕
二、kfree:通用的上层释放接口 正如同 kmalloc() 是最为通用的内核对象分配函数,与之相对应的释放函数便是 kfree() 了,这个函数其实主要就是 __kmem_cache_free() 的 wrapper,对于较大的对象则会用 free_large_kmalloc() 进行释放,如果 object 为 NULL 则直接返回:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 void kfree (const void *object) struct folio *folio ;struct slab *slab ;struct kmem_cache *s ;if (unlikely(ZERO_OR_NULL_PTR(object)))return ;if (unlikely(!folio_test_slab(folio))) {void *)object);return ;void *)object, _RET_IP_);
I. folio 结构:一段物理、虚拟、逻辑上都连续的内存 注意到这里用了一个名为 folio 的结构体,其表示了一块物理、虚拟、逻辑上都连续的内存 , 其实本质上还是复用了 page 结构体,只不过这一次是将 page 转为 folio ,定义比较长这里就不贴代码了
virt_to_folio() 首先会用 virt_to_page() 找到待释放对象虚拟地址对应的 page 结构体,之后用 page_folio() 将其转换为 folio 结构体——其实就是对于复合页而言会找到第一张页面,由此如果是复合页的话那说明是大 slab 所以会调用 free_large_kmalloc(),不是复合页说明是小 slab 所以会调用 __kmem_cache_free():
1 2 3 4 5 6 7 8 9 10 11 12 static inline struct folio *virt_to_folio (const void *x) struct page *page =return page_folio(page);#define page_folio(p) (_Generic((p), \ const struct page *: (const struct folio *)_compound_head(p), \ struct page *: (struct folio *)_compound_head(p)))
然后 folio_test_slab() 其实是 include/linux/page-flags.h 里的拼接宏,这里就不深入展开了:
1 2 static __always_inline bool folio_test_##lname(struct folio *folio) \ { return test_bit(PG_##lname, folio_flags(folio, FOLIO_##policy)); } \
II. free_large_kmalloc():直接将页面释放回 buddy system 正如对于大对象的分配 kmalloc_large() 会直接从 buddy system 请求内存一般,相对应的 free_large_kmalloc() 也会直接将页面释放回 buddy system:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void free_large_kmalloc (struct folio *folio, void *object) unsigned int order = folio_order(folio);if (WARN_ON_ONCE(order == 0 ))"object pointer: 0x%p\n" , object);0 ), NR_SLAB_UNRECLAIMABLE_B,0 ), order);
III. __kmem_cache_free():常规的释放函数 __kmem_cache_free() 主要就是对 slab_free() 的 wrapper,不过会指定 tail 为 NULL:
1 2 3 4 void __kmem_cache_free(struct kmem_cache *s, void *x, unsigned long caller)NULL , &x, 1 , caller);
而 slab_free() 则会最终调用到 do_slab_free():
1 2 3 4 5 6 7 8 9 10 11 12 static __fastpath_inline void slab_free (struct kmem_cache *s, struct slab *slab, void *head, void *tail, void **p, int cnt, unsigned long addr) if (slab_free_freelist_hook(s, &head, &tail, &cnt))
这里用到了一个函数 slab_free_freelist_hook(),主要的作用是遍历待释放的 freelist:
如果设置了 free hook( slab_free_hook() == true ),则仅减少计数以推迟释放
否则重新建立一遍 freelist 后返回
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 static inline bool slab_free_freelist_hook (struct kmem_cache *s, void **head, void **tail, int *cnt) void *object;void *next = *head;void *old_tail = *tail ? *tail : *head;if (is_kfence_address(next)) {false );return true ;NULL ;NULL ;do {if (!slab_free_hook(s, object, slab_want_init_on_free(s))) {if (!*tail)else {while (object != old_tail);if (*head == *tail)NULL ;return *head != NULL ;
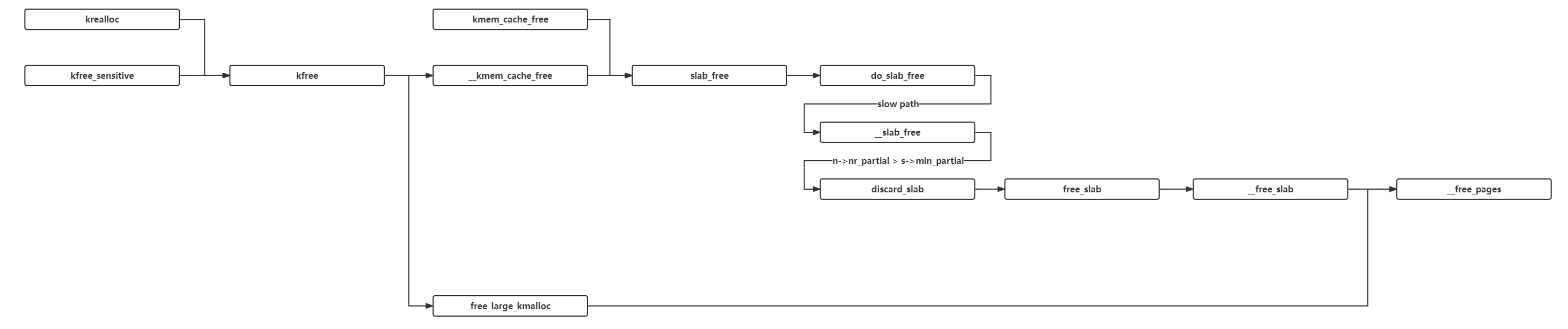
三、上层调用接口关系图 涉及到内存释放的函数相较于内存分配其实少很多,常用的主要就是 kfree()、kfree_sensitive()、kmem_cache_free() 这三大函数: