本文最后更新于:2024年8月19日 下午
HEY DUDE!
0x00.一切开始之前 在上一篇文章 中笔者简要阐述了 Linux 内核当中内存的基本组织架构:页、区、节点,在本篇文章当中笔者将阐述内核中最基础 的内存分配器——Buddy Systen (伙伴系统)
通过读取 /proc/buddyinfo 可以获取当前系统中 buddy system 的详细信息
笔者的💻配置比较🚮,所以只有一个 node,非常抱歉…
这篇文章其实很早就写了个框架了,但是后面一直没有来得及进行补完…(其实就是懒而已吧(恼))
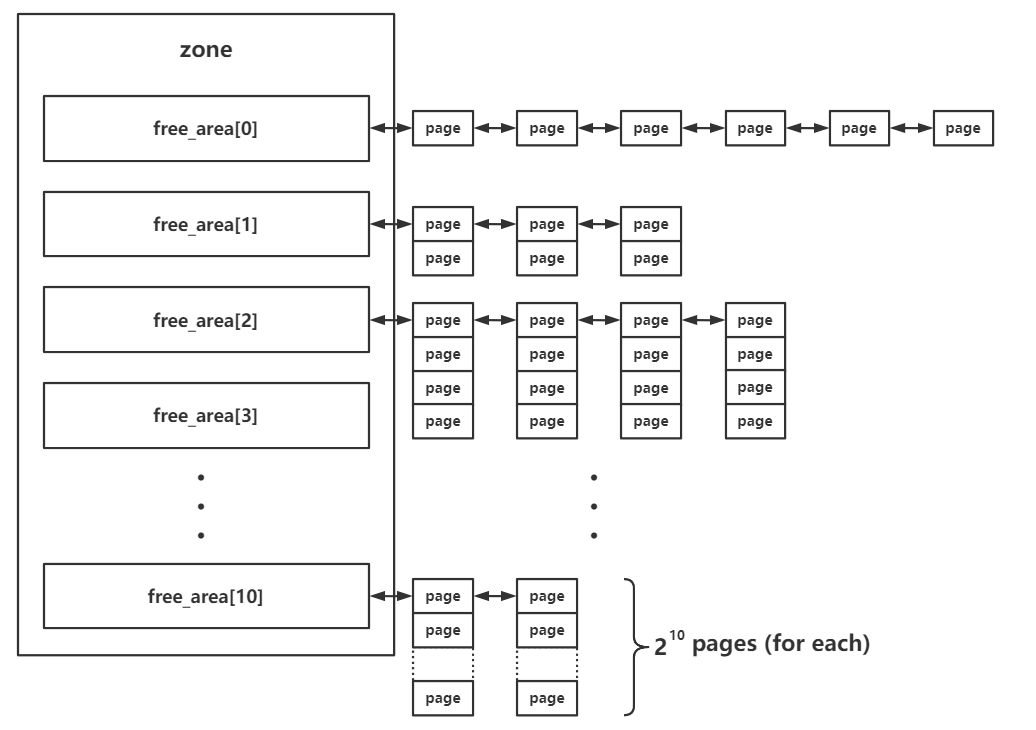
0x01.buddy system 中的内存组织形式 zone 中的 free_area 结构体数组 前文中我们讲到,每个 zone 结构体中都有一个 free_area 结构体数组,用以存储 buddy system 按照 order 管理的页面
1 2 3 4 struct zone {struct free_area free_area [MAX_ORDER ];
其中的 MAX_ORDER 为一个常量,值为 11
在 buddy system 中按照空闲页面的连续大小进行分阶管理,这里的 order 的实际含义为连续的空闲页面的大小 ,不过单位不是页面数,而是阶,即对于每个下标而言,其中所存储的页面大小为:
下面我们来解析 free_area 的具体结构,该结构体定义如下:
1 2 3 4 struct free_area {struct list_head free_list [MIGRATE_TYPES ];unsigned long nr_free;
free_list:空闲页面双向链表 我们不难看出:free_area 的 free_list 字段便是用以存放指向空闲页面的指针,其通过 page 结构体的 lru 字段将 page 结构体连接成双向链表
1 2 3 4 5 6 7 8 9 10 11 struct page {union {struct {struct list_head lru ;
page 结构体中的 lru 这一字段的类型为 struct list_head,这是内核编程中通用的双向链表结构,free_list 与 lru 链表都使用该字段 将页结构体组织为_双向链表_,即_一个页是不可能同时出现在 lru 链表与 buddy system 中的_
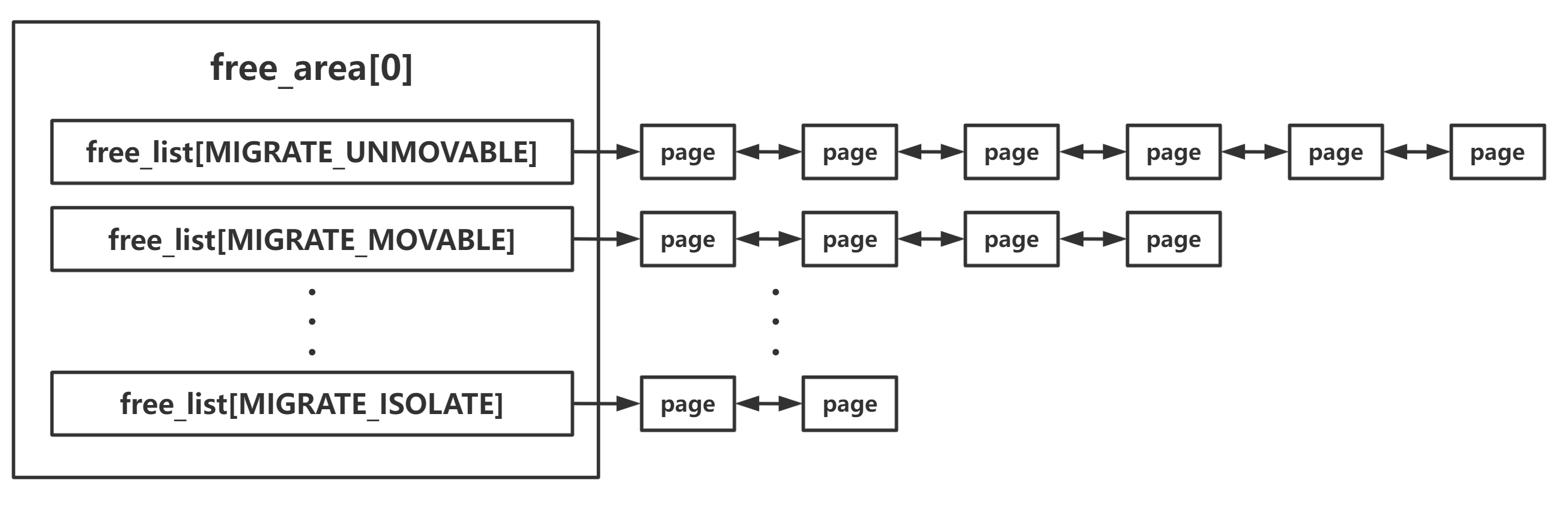
迁移类型分链表 在这里我们注意到free_area 中并非只有一个双向链表 ,而是按照不同的“迁移类型”(migrate type)进行分开存放,这是由于_页面迁移_机制的存在
页面迁移主要用以解决内核空间中的碎片问题 ,在长期的运行之后内存当中空闲页面的分布可能是零散的,这便导致了内核有可能无法映射到足够大的连续内存 ,因此需要进行_页面迁移_——将旧的页面迁移到新的位置
但并非所有的页面都是能够随意迁移的 ,因此我们在 buddy system 当中还需要将页面按照迁移类型进行分类
迁移类型由一个枚举类型定义,定义于 /include/linux/mmzone.h 中,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 enum migratetype {#ifdef CONFIG_CMA #endif #ifdef CONFIG_MEMORY_ISOLATION #endif
MIGRATE_UNMOVABLE :这类型页面在内存当中有着固定的位置,不能移动 MIGRATE_MOVABLE :这类页面可以随意移动 ,例如用户空间的页面,我们只需要复制数据后改变页表映射即可MIGRATE_RECLAIMABLE :这类页面不能直接移动,但是可以删除 ,例如映射自文件的页MIGRATE_PCPTYPES :per_cpu_pageset,即每 CPU 页帧缓存,其迁移仅限于同一节点内 MIGRATE_CMA :Contiguous Memory Allocator,即连续的物理内存 MIGRATE_ISOLATE :不能从该链表分配页面 ,该链表用于跨 NUMA 节点进行页面移动,将页面移动到使用该页面最为频繁的 CPU 所处节点MIGRATE_TYPES_:表示迁移类型的数目,_并不存在这一链表
以 free_list[0] 作为例子,我们可以得到如下 overview:
nr_free:空闲页面(块)计数 该字段记录了在当前 free_area 中的空闲页面块的数量,对于 free_area[0] 以外的 free_area 而言其单位并非是单个页框,而是以_内存块_为单位
0x02.页的分配 buddy system 提供了一组用以进行页面分配的接口,接下来笔者将以自底向上的方式进行源码分析
一、GFP(get free page)标志位
GFP标志位这一节基本上搬运自这篇文章
在 kernel memory allocation 中我们经常能见到 gfp_t 类型,其表示分配时的标志位,定义在 include/linux/gfp.h 中,大概有如下这些可用标志位:
内存管理区修饰符 (zone modifiers)
内存管理区修饰符主要描述从哪些内存管理区来分配内存
flag
description
__GFP_DMA
从ZONE_DMA区中分配内存
__GFP_HIGNMEM
从ZONE_HIGHMEM区中分配内存
__GFP_DMA32
从ZONE_DMA32区中分配内存
__GFP_MOVABLE
内存规整时可以迁移或回收页面
移动和替换修饰符(mobility and placement modifiers)
移动和替换修饰符主要表示分配出来的页面具有的迁移属性
flag
description
__GFP_RECLAIMABLE
分配的内存页面可以回收
__GFP_WRITE
申请的页面会被弄成脏页
__GFP_HARDWALL
强制使用cpuset内存分配策略
__GFP_THISNODE
在指定的节点上分配内存
__GFP_ACCOUNT
kmemcg会记录分配过程
水位修饰符 (watermark modifiers)
与水位线相关的标志位
flag
description
__GFP_ATOMIC
高优先级分配内存,分配器可以分配最低警戒水位线下的预留内存
__GFP_HIGH
分配内存的过程中不可以睡眠或执行页面回收动作
__GFP_MEMALLOC
允许访问所有的内存
__GFP_NOMEMALLOC
不允许访问最低警戒水位线下的系统预留内存
页面回收修饰符(reclaim modifiers)
与页面回收相关的标志位
flag
description
__GFP_IO
启动物理I/O传输
__GFP_FS
允许调用底层FS文件系统。可避免分配器递归到可能已经持有锁的文件系统中, 避免死锁
__GFP_DIRECT_RECLAIM
分配内存过程中可以使用直接内存回收
__GFP_KSWAPD_RECLAIM
内存到达低水位时唤醒kswapd线程异步回收内存
__GFP_RECLAIM
表示是否可以直接内存回收或者使用kswapd线程进行回收
__GFP_RETRY_MAYFAIL
分配内存可以可能会失败,但是在申请过程中会回收一些不必要的内存,是整个系统受益
__GFP_NOFAIL
内存分配失败后无限制的重复尝试,知道分配成功
__GFP_NORETRY
直接页面回收或者内存规整后还是无法分配内存时,不启用retry反复尝试分配内存,直接返回NULL
与分配时的行为相关的标志位
flag
description
__GFP_NOWARN
关闭内存分配过程中的WARNING
__GFP_COMP
分配的内存页面将被组合成复合页compound page
__GFP_ZERO
返回一个全部填充为0的页面
组合类型标志(Useful GFP flag combinations)
前面描述的修饰符种过于繁多,因此linux定义了一些组合的类型标志,供开发者使用。
flag
element
description
GFP_ATOMIC
__GFP_HIGH |__GFP_ATOMIC |__GFP_KSWAPD_RECLAIM
分配过程不能休眠,分配具有高优先级,可以访问系统预留内存
GFP_KERNEL
__GFP_RECLAIM |__GFP_IO |__GFP_FS
分配内存时可以被阻塞(即休眠)
GFP_KERNEL_ACCOUNT
GFP_KERNEL |__GFP_ACCOUNT
和GFP_KERNEL作用一样,但是分配的过程会被kmemcg记录
GFP_NOWAIT
__GFP_KSWAPD_RECLAIM
分配过程中不允许因直接内存回收而导致停顿
GFP_NOIO
__GFP_RECLAIM
不需要启动任何的I/O操作
GFP_NOFS
__GFP_RECLAIM |__GFP_IO
不会有访问任何文件系统的操作
GFP_USER
__GFP_RECLAIM |__GFP_IO |__GFP_FS |__GFP_HARDWALL
用户空间的进程分配内存
GFP_DMA
__GFP_DMA
从ZONE_DMA区分配内存
GFP_DMA32
__GFP_DMA32
从ZONE_DMA32区分配内存
GFP_HIGHUSER
GFP_USER | __GFP_HIGHMEM
用户进程分配内存,优先使用ZONE_HIGHMEM, 且这些页面不允许迁移
GFP_HIGHUSER_MOVABLE
GFP_HIGHUSER | __GFP_MOVABLE
和GFP_HIGHUSER类似,但是页面可以迁移
GFP_TRANSHUGE_LIGHT
GFP_HIGHUSER_MOVABLE | __GFP_COMP | __GFP_NOMEMALLOC | __GFP_NOWARN) & ~__GFP_RECLAIM
透明大页的内存分配, light表示不进行内存压缩和回收
GFP_TRANSHUGE
GFP_TRANSHUGE_LIGHT | __GFP_DIRECT_RECLAIM
和GFP_TRANSHUGE_LIGHT类似,通常khugepaged使用该标志
二、alloc_context 结构体:分配的上下文 这是一个分配过程中非常重要的结构体,用来表示我们单次内存分配的上下文信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 struct alloc_context {struct zonelist *zonelist ;nodemask_t *nodemask;struct zoneref *preferred_zoneref ;int migratetype;enum zone_type highest_zoneidx ;bool spread_dirty_pages;
我们主要关注如下成员:
该成员表示在这一次的分配上下文 中,我们将要操作的 zone 的列表 ,其为一个 zonelist 类型的结构体数组 ,该结构体定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct zonelist {struct zoneref _zonerefs [MAX_ZONES_PER_ZONELIST + 1];
可以看到的是其为一个 zoneref 类型的结构体数组,该结构体定义如下,包含了一个 zone 的指针以及一个 index:
1 2 3 4 5 6 7 8 struct zoneref {struct zone *zone ;int zone_idx;
该成员为一个 zoneref 类型的结构体,表示优先用来进行分配的 zone
布尔值,表示此次分配是否可能产生脏页 (需要进行写回),通常分配需要写入的页会出现
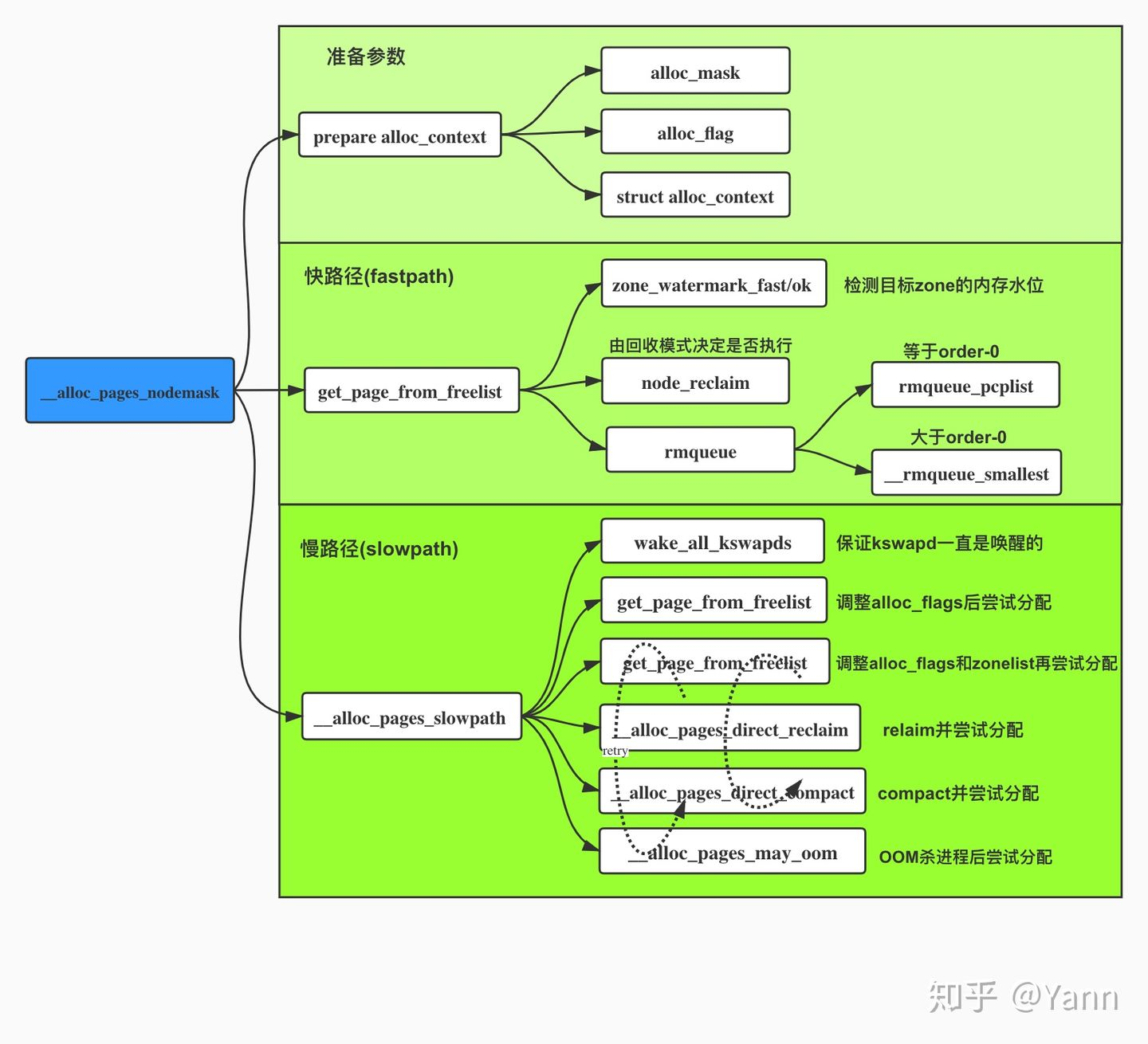
三、__alloc_pages_nodemask():分配页面的「核心函数」,返回 page 结构体 该函数是 buddy system 中用以进行页面分配的核心函数 ,所有的页面分配 API 都是基于该函数的封装,其需要传入的四个参数为:
gfp_mask:分配行为参数(可以参见 这里 )order:分配的连续物理页框的阶preferred_nid 选取的节点的 idnodemask:
返回值为分配的连续物理页 中的第一张物理页的 page 结构体
如果你已经不记得 page 结构体与物理页的页框号间的转换公式了,可以回去看上一篇文章
当然,笔者比较好心(笑),这里直接给出计算公式,mem_section 结构体中的 section_mem_map 成员存储了其起始地址减掉其起始地址对应的物理页框的页框号的差值,该成员与 page 结构体间做指针差值运算 便能获得 page 结构体对应的物理页框号:
这是一张_Overview_
该函数定义于 /mm/page_alloc.c 中,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 struct page *__alloc_pages_nodemask (gfp_t gfp_mask , unsigned int order , int preferred_nid , nodemask_t *nodemask ) { struct page *page ;unsigned int alloc_flags = ALLOC_WMARK_LOW;gfp_t alloc_mask; struct alloc_context ac =if (unlikely(order >= MAX_ORDER)) {return NULL ;if (!prepare_alloc_pages(gfp_mask, order, preferred_nid, nodemask, &ac, &alloc_mask, &alloc_flags))return NULL ;if (likely(page))goto out;false ;if (memcg_kmem_enabled() && (gfp_mask & __GFP_ACCOUNT) && page &&0 )) {NULL ;return page;
这个函数的具体步骤主要分为三步:
检查参数合法性,并做分配前准备工作
进行快速分配 ,成功则直接返回结果
若快速分配失败,则进行慢速分配
接下来我们来深入快速分配与慢速分配的内部细节
I. prepare_alloc_pages():分配前的准备工作 这个函数比较简单,主要是做分配前的一些准备的工作,包括初始化 alloc_context 结构体、获取 zone 数组等:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 static inline bool prepare_alloc_pages (gfp_t gfp_mask, unsigned int order, int preferred_nid, nodemask_t *nodemask, struct alloc_context *ac, gfp_t *alloc_mask, unsigned int *alloc_flags) if (cpusets_enabled()) {if (!in_interrupt() && !ac->nodemask)else if (should_fail_alloc_page(gfp_mask, order))return false ;return true ;
首先调用 node_zonelist() 从 preferred_nid 参数所指定的 node 中获取一个 zonelist,其实就是取 pglist_data->node_zonelists[gfp_zonelist(flags)]
进行 cpuset 相关判断与标志位设置,若是在中断上下文则直接将 nodemask 设为 cpuset_current_mems_allowed
最后调用 first_zones_zonelist() 设置 preferred zone,大概是在 zonelist 中→nodemask 所包含的 zone 中→ highest_zoneidx 以下的第一个 zone
反正源码注释是这么写的hhh
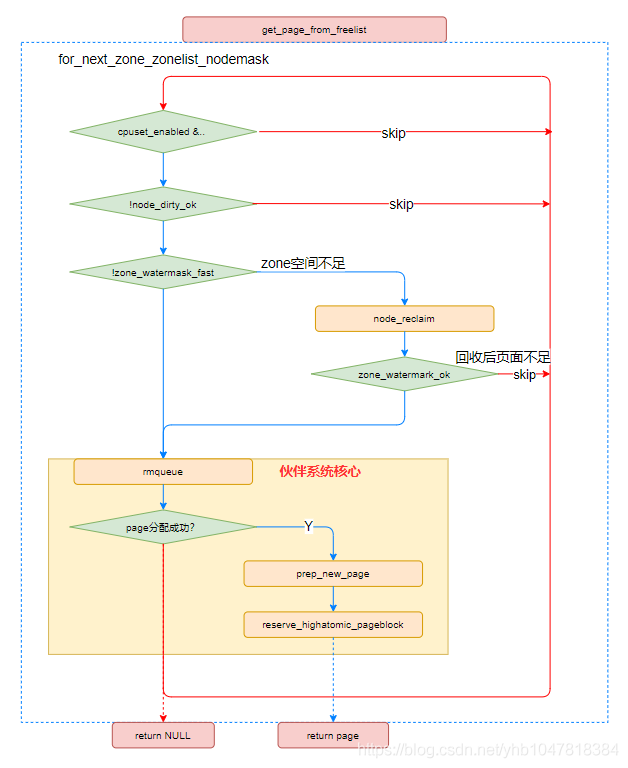
II. get_page_from_freelist():快速分配路径(核心分配函数) 该函数定义于 /mm/page_alloc.c 中,主要是遍历分配上下文对应的 zonelist 中的 zone 进行内存分配,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 static struct page *get_page_from_freelist (gfp_t gfp_mask, unsigned int order, int alloc_flags, const struct alloc_context *ac) struct zoneref *z ;struct zone *zone ;struct pglist_data *last_pgdat_dirty_limit =NULL ;bool no_fallback;struct page *page ;unsigned long mark;if (cpusets_enabled() &&continue ;if (ac->spread_dirty_pages) {if (last_pgdat_dirty_limit == zone->zone_pgdat)continue ;if (!node_dirty_ok(zone->zone_pgdat)) {continue ;if (no_fallback && nr_online_nodes > 1 &&int local_nid;if (zone_to_nid(zone) != local_nid) {goto retry;if (!zone_watermark_fast(zone, order, mark,int ret;#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT if (static_branch_unlikely(&deferred_pages)) {if (_deferred_grow_zone(zone, order))goto try_this_zone;#endif if (alloc_flags & ALLOC_NO_WATERMARKS)goto try_this_zone;if (node_reclaim_mode == 0 ||continue ;switch (ret) {case NODE_RECLAIM_NOSCAN:continue ;case NODE_RECLAIM_FULL:continue ;default :if (zone_watermark_ok(zone, order, mark,goto try_this_zone;continue ;if (page) {if (unlikely(order && (alloc_flags & ALLOC_HARDER)))return page; else { #ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT if (static_branch_unlikely(&deferred_pages)) {if (_deferred_grow_zone(zone, order))goto try_this_zone;#endif if (no_fallback) {goto retry;return NULL ;
该函数流程总结如下:
rmqueue():从给定的 page 中进行页面分配 该函数定义于 /mm/page_alloc.c 中,主要是从给定 zone 中进行内存分配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 static inline struct page *rmqueue (struct zone *preferred_zone, struct zone *zone, unsigned int order, gfp_t gfp_flags, unsigned int alloc_flags, int migratetype) unsigned long flags;struct page *page ;if (likely(order == 0 )) {if (!IS_ENABLED(CONFIG_CMA) || alloc_flags & ALLOC_CMA ||goto out;1 ));do {NULL ;if (order > 0 && alloc_flags & ALLOC_HARDER) {if (page)if (!page)while (page && check_new_pages(page, order)); if (!page)goto failed;1 << order),1 << order);if (test_bit(ZONE_BOOSTED_WATERMARK, &zone->flags)) {0 , 0 , zone_idx(zone));return page;return NULL ;
分析函数流程前我们先回顾一下这个概念——per-cpu pageset ,这是 zone 上的一个 per-cpu 的页面集,在分配时会优先从这里进行分配
该函数其实还是对分配的核心逻辑的封装,主要是以下流程:
分配的 order 为 0,若没有开启 CMA | 设置了 ALLOC_CMA | 迁移类型非 MIGRATE_MOVABLE,则尝试从 per-cpu pageset 中分配并返回
order > 0,调用 __rmqueue_smallest() 进行页面分配
之前未分配成功,调用 __rmqueue() 进行页面分配
结果检查,其中循环内是用 check_new_pages(),未通过则重新循环(回到第二步)
① rmqueue_pcplist():从 per-cpu pageset 上做 order-0 的分配 主要是关中断→页面分配→开中断三步走,最后分配调用到的是 __rmqueue_pcplist()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 static struct page *rmqueue_pcplist (struct zone *preferred_zone, struct zone *zone, gfp_t gfp_flags, int migratetype, unsigned int alloc_flags) struct per_cpu_pages *pcp ;struct list_head *list ;struct page *page ;unsigned long flags;list = &pcp->lists[migratetype]; list ); if (page) {1 );return page;
__rmqueue_pcplist() 主要就是一个大循环,若 pcplist 为空则调用 rmqueue_bulk() 先从 zone 上拿 pages,之后就是简单的链表脱链,分配结果使用 check_new_page() 进行检查:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 static struct page *__rmqueue_pcplist (struct zone *zone , int migratetype , unsigned int alloc_flags , struct per_cpu_pages *pcp , struct list_head *list ) { struct page *page ;do {if (list_empty(list )) { 0 ,list ,if (unlikely(list_empty(list )))return NULL ;list , struct page, lru);while (check_new_pcp(page));return page;
rmqueue_bulk() 则最终会调用到 __rmqueue() 为 pcplist 进行 pcp->batch 次的 order-0 的页面分配,并建立链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 static int rmqueue_bulk (struct zone *zone, unsigned int order, unsigned long count, struct list_head *list , int migratetype, unsigned int alloc_flags) int i, alloced = 0 ;for (i = 0 ; i < count; ++i) {struct page *page =if (unlikely(page == NULL ))break ;if (unlikely(check_pcp_refill(page)))continue ;list );if (is_migrate_cma(get_pcppage_migratetype(page)))1 << order));return alloced;
② __rmqueue_smallest():遍历指定 migrationtype 链表的 buddy 算法(核心中的核心) 我们重新来回顾一下 free_area 的结构,在其中根据迁移类型分成了多个链表:
而一个 zone 是由多个 free_area 组成的,一个 free_area 对应一个 order,那么对于该函数而言其只会遍历特定的 order,那么就成了下面的模型:
现在我们可以以来看这个函数了:从待分配 order 所对应的 free_area 的指定的 migration type 链表上分配,若不够则一直向更高 order 进行分配后对半向下拆到低 order,这里向更高 order 分配是通过简单的循环 + 链表脱链操作完成的,而拆高阶 page 的操作则是通过 expand() 完成的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 static __always_inlinestruct page *__rmqueue_smallest (struct zone *zone , unsigned int order , int migratetype ) { unsigned int current_order;struct free_area *area ;struct page *page ;for (current_order = order; current_order < MAX_ORDER; ++current_order) {if (!page)continue ;return page;return NULL ;
expand() 的逻辑就比较简单,从高阶 order 一直循环到待分配的 order:
首先高阶 order–,之后页面拆两半,把后半部分挂到链表上,前半部分留到下次循环继续拆
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 static inline void expand (struct zone *zone, struct page *page, int low, int high, int migratetype) unsigned long size = 1 << high;while (high > low) {1 ;if (set_page_guard(zone, &page[size], high, migratetype))continue ;
③ __rmqueue():分配封装函数 这个函数其实主要是对其他分配函数的封装,最终的核心函数其实都还是 __rmqueue_smallest():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 static __always_inline struct page *__rmqueue (struct zone *zone , unsigned int order , int migratetype , unsigned int alloc_flags ) { struct page *page ;if (IS_ENABLED(CONFIG_CMA)) {if (alloc_flags & ALLOC_CMA &&2 ) {if (page)goto out;if (unlikely(!page)) {if (alloc_flags & ALLOC_CMA)if (!page && __rmqueue_fallback(zone, order, migratetype,goto retry;if (page)return page;
流程如下:
若开启了 CMA,比对常规区域与 CMA 区域的空闲页面数量,若 CMA 的多则调用 __rmqueue_cma_fallback() 从 CMA 区域分配(其实就是调用 __rmqueue_smallest() 从迁移类型为 MIGRATE_CMA 的链表上分配),成功则直接返回
调用 __rmqueue_smallest() 从指定迁移类型链表进行分配,若未成功:
若设置了 ALLOC_CMA 的分配 flag,调用 __rmqueue_cma_fallback() 从 CMA 区域进行分配
若上一步失败则调用 __rmqueue_fallback() 尝试从其他迁移类型链表获取页面,若还是失败则重试这一个大步骤
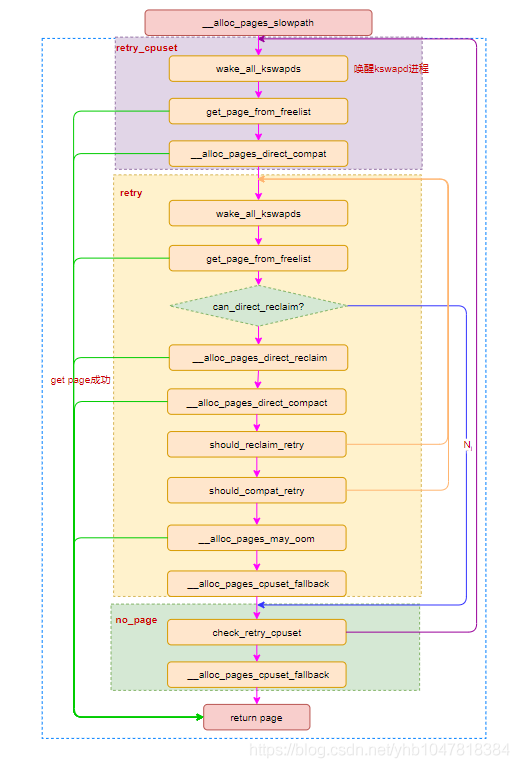
III. __alloc_pages_slowpath():慢速分配路径 当快速路径的分配不成功时,说明系统当前可能已经没有足够的连续的空闲页面,这时我们就要进入到慢速路径的分配,进行内存碎片整理与内存回收 ,之后再进行分配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 static inline struct page *__alloc_pages_slowpath (gfp_t gfp_mask , unsigned int order , struct alloc_context *ac ) { bool can_direct_reclaim = gfp_mask & __GFP_DIRECT_RECLAIM;const bool costly_order = order > PAGE_ALLOC_COSTLY_ORDER;struct page *page =NULL ;unsigned int alloc_flags;unsigned long did_some_progress;enum compact_priority compact_priority ;enum compact_result compact_result ;int compaction_retries;int no_progress_loops;unsigned int cpuset_mems_cookie;int reserve_flags;if (WARN_ON_ONCE((gfp_mask & (__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)) ==0 ;0 ;if (!ac->preferred_zoneref->zone)goto nopage;if (alloc_flags & ALLOC_KSWAPD)if (page)goto got_pg;if (can_direct_reclaim &&0 && ac->migratetype != MIGRATE_MOVABLE))if (page)goto got_pg;if (costly_order && (gfp_mask & __GFP_NORETRY)) {if (compact_result == COMPACT_SKIPPED ||goto nopage;if (alloc_flags & ALLOC_KSWAPD)if (reserve_flags)if (!(alloc_flags & ALLOC_CPUSET) || reserve_flags) {NULL ;if (page)goto got_pg;if (!can_direct_reclaim)goto nopage;if (current->flags & PF_MEMALLOC)goto nopage;if (page)goto got_pg;if (page)goto got_pg;if (gfp_mask & __GFP_NORETRY)goto nopage;if (costly_order && !(gfp_mask & __GFP_RETRY_MAYFAIL))goto nopage;if (should_reclaim_retry(gfp_mask, order, ac, alloc_flags,0 , &no_progress_loops))goto retry;if (did_some_progress > 0 &&goto retry;if (check_retry_cpuset(cpuset_mems_cookie, ac))goto retry_cpuset;if (page)goto got_pg;if (tsk_is_oom_victim(current) &&goto nopage;if (did_some_progress) {0 ;goto retry;if (check_retry_cpuset(cpuset_mems_cookie, ac))goto retry_cpuset;if (gfp_mask & __GFP_NOFAIL) {if (WARN_ON_ONCE(!can_direct_reclaim))goto fail;if (page)goto got_pg;goto retry;"page allocation failure: order:%u" , order);return page;
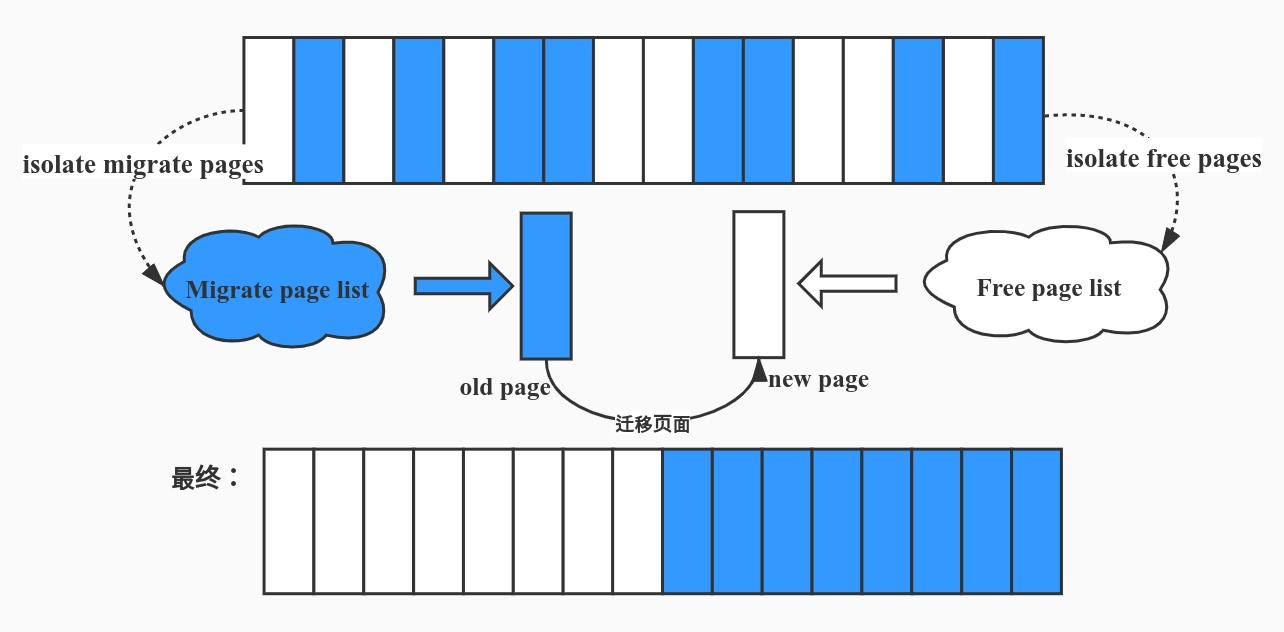
这里我们先补充一个概念——Memory compaction 机制,其实就是整理内存碎片,对零散的内存页进行迁移,从而将零散的空闲内存页变成大块的空闲内存,不过这里只整理可以移动的碎片:
现在我们来看慢速分配的整个流程:
使用原有的 gfp_flag 重新设置 alloc_flag,并重新计算 preferred zone,若设置了 ALLOC_KSWAPD 则调用 wake_all_kswapds() 唤醒 kswapd 线程进行内存回收
之后重新尝试快速路径的分配,若成功则直接返回
接下来调用 __alloc_pages_direct_compact() 进行 compaction,该函数内部在整理完后会重新尝试快速路径的分配,若成功则直接返回
(retry)接下来调用 wake_all_kswapds() 唤醒 kswapd 线程进行内存回收
调整 zonelist 与 alloc_flag,之后再次尝试快速路径分配,若成功则直接返回
若 gfp_flag 中没有 __GFP_DIRECT_RECLAIM 或是进程 PCB 的 flag 中有 PF_MEMALLOC,直接跳转到 (nopage)
调用 __alloc_pages_direct_reclaim() 进行内存回收(内部调用 __perform_reclaim())与快速路径分配,若成功则直接返回
调用 __alloc_pages_direct_compact() 进行 compaction 与快速路径分配,若成功则直接返回
如果设置了 __GFP_NORETRY ,或是该次内存分配开销较高(order > PAGE_ALLOC_COSTLY_ORDER)且未设置 __GFP_RETRY_MAYFAIL,直接跳到 (nopage)
调用 should_reclaim_retry() 判断是否需要重新回收,若是则跳回(retry)
调用 should_compact_retry() 判断是否需要重新进行 compaction,若是则跳回(retry)
调用 check_retry_cpuset() 检查 cpuset 是否发生变化,若是则跳转回开头
调用 __alloc_pages_may_oom() 尝试 kill 一些进程来释放内存,该函数内首先还是会先进行一次快速分配,之后才是调用 out_of_memory() 来杀掉最适合的进程以释放内存,最后若设置了 __GFP_NOFAIL 则调用 __alloc_pages_cpuset_fallback() 再次尝试内存分配,在该函数中会两次走快速路径进行分配(第一次会额外附加上 ALLOC_CPUSET 的 flag)
如果把当前进程杀掉了,跳到(nopage);如果杀进程取得了成效,跳回(retry)
(nopage)调用 check_retry_cpuset() 检查 cpuset 是否发生变化,若是则跳转回开头
若设置了 __GFP_NOFAIL 则进行一系列的警告,并调用 __alloc_pages_cpuset_fallback() 再次尝试内存分配,若未成功则跳回(retry)
返回结果
四、上层封装分配函数 在 __alloc_pages_nodemask() 上层主要有三个页面分配函数,其调用路径如下:
1 2 3 4 5 6 7 8 9 10 11 12 __alloc_pages_node __alloc_pages __alloc_pages_nodemask __alloc_pages_nodemask __get_free_pages __alloc_pages_nodemask
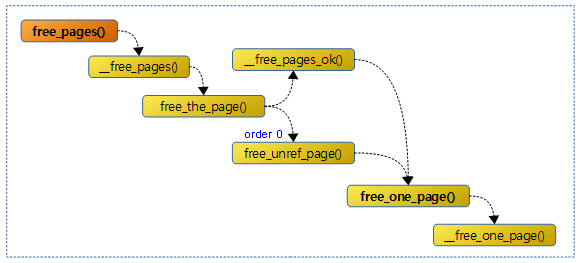
0x03.页的释放 前面我们讲了页面是如何分配的,现在我们来看页面是如何释放的
一、__free_one_page():释放页面的核心函数 该函数是 buddy system 中用以进行页面释放的核心函数 ,所有的页面释放 API 都是基于该函数的封装
该函数定义于 /mm/page_alloc.c 中,主要作用是将特定页面释放到特定 zone 上,需要注意的是这里的 one page 不是一张页框而是一块连续内存(可能有多张页)
还需要注意的是这是一个释放页面的基本函数 ,故我们需要提供待释放页面的页结构体(struct page)、页框号、页面块的阶(order)、目标 zone、迁移类型等信息——这些信息通常由上层封装函数提供,这个函数所做的只是简单地将页挂回对应链表并检查合并的操作
如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 static inline void __free_one_page(struct page *page,unsigned long pfn,struct zone *zone, unsigned int order,int migratetype, fpi_t fpi_flags)struct capture_control *capc =unsigned long buddy_pfn;unsigned long combined_pfn;unsigned int max_order;struct page *buddy ;bool to_tail;min_t (unsigned int , MAX_ORDER - 1 , pageblock_order);-1 );if (likely(!is_migrate_isolate(migratetype)))1 << order, migratetype);1 << order) - 1 ), page);while (order < max_order) {if (compaction_capture(capc, page, order, migratetype)) {1 << order),return ;if (!pfn_valid_within(buddy_pfn)) goto done_merging;if (!page_is_buddy(page, buddy, order)) goto done_merging;if (page_is_guard(buddy))else if (order < MAX_ORDER - 1 ) {if (unlikely(has_isolate_pageblock(zone))) {int buddy_mt;if (migratetype != buddy_mtgoto done_merging;1 ;goto continue_merging;if (fpi_flags & FPI_TO_TAIL)true ;else if (is_shuffle_order(order))else if (to_tail)else if (!(fpi_flags & FPI_SKIP_REPORT_NOTIFY))
我们将与待释放页面凑成一对的内存块称为 buddy,所谓凑成一对便是这两个内存块在物理上连续,且能凑成一个更高一阶的大内存块 ,由此称之为一对 buddies
该函数主要流程如下:
(continue_merging,循环开头)调用 __find_buddy_pfn() 计算待释放页面的 buddy 的第一张物理页的页框号,算法比较暴力:page_pfn ^ (1 << order)
调用 page_is_buddy() 检查 buddy 与 待释放页面是否是一对 buddies,若否,则跳到(done_merging),这里的检查需要满足四个要素:
buddy 不在空洞中
buddy 在 buddy system 中(即 buddy 也是空闲内存块)
待释放页面与其 buddy 在同一个 zone 中
待释放页面与其 buddy 有着同样的阶(order)
若 buddy 为 guard page,则调用 clear_page_guard() 清楚这个属性让其变成空闲页面,这里清除的操作是通过将 page 结构体的 private 字段置 0 实现的;若否,则说明是常规的空闲页面,调用 del_page_from_free_list() 将其脱链
此时我们的新的高阶内存块就完成合成了,接下来我们回到循环开头重新寻找这个合成的新内存块的 buddy,这个循环一直持续到 max_order (一般是10),作为下一次循环的页框号的计算方式是 buddy_pfn & pfn,之后做指针运算 page + (combined_pfn - pfn) 找到对应的 page 结构体
若退出循环时的 order 满足 order < MAX_ORDER - 1 ,则调用 has_isolate_pageblock() 检查 zone 中是否有 isolate block,若是则进行相关操作(这块代码还没看懂),最后跳转回(continue_merging);这一步主要是防止 isolate pageblock 与常规的 pageblock 发生合并
(done_merging)这一步主要是调用 set_buddy_order() 在 page 结构体的 private 字段存放该内存块的 order
若是设置了 FPI_TO_TAIL flag,则将 to_tail 置为 true;否则,若内存块的 order >= SHUFFLE_ORDER(MAX_ORDER - 1),则将 to_tail 置为随机结果(shuffle_pick_tail());否则置为调用 buddy_merge_likely() 的结果,该函数会检查是否下一个最高阶的 buddy 是否空闲,若是,则可能正在释放的页面块将很快被合并,此时我们应当将其添加到链表的尾部,这样就不大可能又被别的进程很快就分配走了,而是可能被合并为高阶页面
若 to_tail 为真,则调用 add_to_free_list_tail() 将该空闲页添加到链表末尾,否则调用 add_to_free_list() 添加到链表开头
二、上层封装函数 所有页面释放的函数其实都是对 __free_one_page() 的封装,最终都会调用到这个函数,路径如下: