本文最后更新于:2023年8月13日 晚上
宁就是👴の Manager 🐎
0x00.一切开始之前 syzkaller 是一个非常经典的 kernel fuzzer,虽然笔者之前曾经用过(不过笔者太菜了啥都没挖出来)也曾粗略读过源码,但是没有太过于仔细分析就抛在脑后了(悲)
为了深入学习 fuzzing theory,笔者决定先从这个典中典的 syzkaller 源码进行分析学习 :)
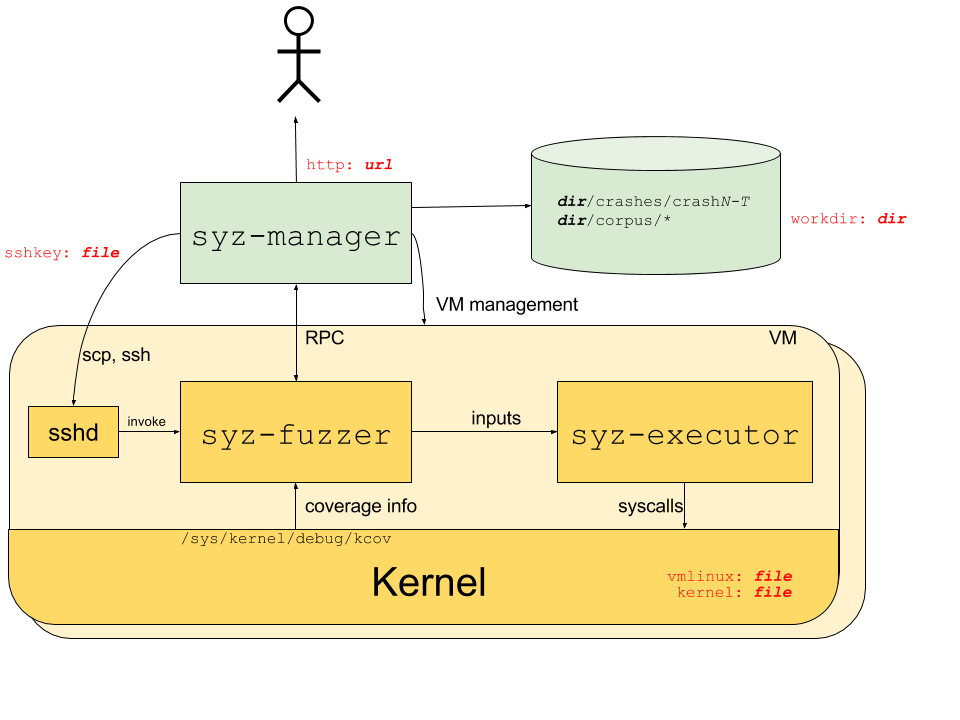
PRE.工作原理 对于 syzkaller 的架构,官方给出了这样的一张 Overview
syzkaller 整体上为一个双机调试结构 :由一台机器负责管控整个 fuzzing 流程(本文称为 Host),在另一台机器上进行 fuzzing(本文称为 Guest),Guest 通常为虚拟机,从而能让 Host 更好地管控整个流程
syzkaller 分为三大组件:
位于 Host:
syz-manager :syzkaller 的控制中枢,其会启动多个 VM 实例(如图所示的一个黄色卡片就是一个实例)并进行监视,同时通过 RPC 来启动 syz-fuzzer
位于 Guest:
syz-fuzzer :负责引导整个 fuzz 的过程:
生成 input
启动 syz-executor 进程进行 fuzz
从被 fuzz 的 kernel 的 /sys/kernel/debug/kcov 获得覆盖(coverage)的相关信息
通过 RPC 将新的覆盖回送到 syz-manager
syz-executor:负责执行单个输入 ——从 syz-fuzzer 处接受 input 并执行,最后回送结果
syz-manager 为 syzkaller 的控制中枢,其会启动多个 VM 实例并进行监视,同时通过 RPC 来启动 syz-fuzzer,我们通常启动 fuzzing 时便是以 syz-manager 作为程序启动的入口点,因此笔者也先从此处开始分析
0x01. 基本结构体 相比于直接开始分析源码,笔者认为有必要在此之前先列出一些基本的结构体,你也可以把这一节当成一个表来查 :)
VM 管控相关 Host 需要去感知与管控 Guest VMs,因而在 syz-manager 当中有着一套相应的表示与管理 Guest VM 的结构体
1. Instance:VM 实例 syz-manager 中的 VM 实际上是使用一个名为 Instance 的结构体来表示的,定义于 vm/vm.go 中:
1 2 3 4 5 6 7 type Instance struct {string int func ()
类似地,其需要实现 Interface 接口,定义于 vm/vmimpl/vmimpl.go 中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 type Instance interface {string ) (string , error )int ) (string , error )chan bool , command string ) (outc <-chan []byte , errc <-chan error , err error )byte , wait bool )
Copy():将一个来自宿主机的文件拷贝至虚拟机中,返回虚拟机中的文件名.Forward():设置从虚拟机内到主机上给定 tcp 端口的转发,并返回要在虚拟机中使用的地址Run():在虚拟机内执行命令Diagnose():在虚拟机上检索额外的调试信息Close():停止并销毁虚拟机
需要注意的是不同类型的 Guest VM 所实现的 Interface 接口是不同的
以 QEMU 为例,其实现主要位于 vm/qemu/qemu.go 中
2.Pool:VM 池 类似于线程池的概念,在 syz-manager 中使用一个 VM 池 —— Pool 结构体来管控 Guest VM,该结构体定义于 vm/vm.go 中:
1 2 3 4 5 6 7 type Pool struct {string string int32
该结构体实现了 Pool 接口,定义于 vm/vmimpl/vmimpl.go 中:
1 2 3 4 5 6 7 8 type Pool interface {int string , index int ) (Instance, error )
Count():返回池中所有 VM 的数量Create():新建并启动一个 VM实例 ,返回新建的实例对象
QEMU VM 浅析 以 QEMU 为例的 Pool 接口实现如下,对于 Count() 而言会直接返回配置文件中的计数:
1 2 3 func (pool *Pool) int {return pool.cfg.Count
Create() 则会首先检查文件系统镜像是否为 9p 格式,若是则会生成一个 ssh key 存放到 key 文件中并生成一个 init.sh 文件;接下来就是调用 ctor() 函数创建虚拟机:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 func (pool *Pool) string , index int ) (vmimpl.Instance, error ) {if pool.env.Image == "9p" {"key" )"root" if _, err := osutil.RunCmd(10 *time.Minute, "" , "ssh-keygen" , "-t" , "rsa" , "-b" , "2048" ,"-N" , "" , "-C" , "" , "-f" , sshkey); err != nil {return nil , err"init.sh" )if err := osutil.WriteExecFile(initFile, []byte (strings.Replace(initScript, "{{KEY}}" , sshkey, -1 ))); err != nil {return nil , fmt.Errorf("failed to create init file: %v" , err)for i := 0 ; ; i++ {if err == nil {return inst, nil if i < 1000 && strings.Contains(err.Error(), "ould not set up host forwarding rule" ) {continue if i < 1000 && strings.Contains(err.Error(), "Device or resource busy" ) {continue return nil , err
ctor() 的实现比较简单,主要就是创建一个带着 ssh key 及一些配置信息与一个 channel 的 instance 实例,初始化实例内的管道并调用 boot() 函数进行正式的创建:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 func (pool *Pool) string , index int ) (vmimpl.Instance, error ) {make (chan bool , 1 ),if st, err := os.Stat(inst.image); err != nil && st.Size() == 0 {"" defer func () if closeInst != nil {var err error if err != nil {return nil , errif err := inst.boot(); err != nil {return nil , errnil return inst, nil
boot() 函数主要就是各种参数判断,之后把 QEMU 起了以后 ssh 连上去 ,这里就不摘抄代码了:)
3. Env:单个 VM Pool 的环境变量 Env 结构体为用于一个 VM Pool 的环境变量,定义于 vm/vmimpl/vmimpl.go 中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 type Env struct {string string string string string string string bool byte string
4. Type:VM 类型 一个 VM Pool 中只能有一种类型的 VM,因而不同类型的 VM 的 Pool 应当要有不同的构造函数,在 syz-manager 中使用 Type 结构体表示一种 VM 的类型信息,定义于 vm/vmimpl/vmimpl.go 中:
1 2 3 4 5 6 type Type struct {bool type ctorFunc func (env *Env) error )
ctorFunc 为构造函数类型,其接受一个 Env 类型的结构体指针(储存了全局的一些基本信息),并返回一个 VM Pool 实例
由一个全局的 string→Type 映射表存储了不同类型 VM 的信息,在正式启动之前程序会通过 Register() 函数将不同类型的 VM 信息注册到该表中,定义于 vm/vmimpl/vmimpl.go 中:
1 2 3 4 5 6 7 8 9 10 11 12 13 func Register (typ string , ctor ctorFunc, allowsOvercommit bool ) var (make (map [string ]Type)
以 QEMU 为例,其在包被导入时注册构造函数,主要是调用 LoadData() 解析配置文件后进行检查,这里不再赘叙:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 func init () var _ vmimpl.Infoer = (*instance)(nil )"qemu" , ctor, true )func ctor (env *vmimpl.Env) error ) {"/" +env.Arch]1 ,1 ,1024 ,"hda" ,true ,if err := config.LoadData(env.Config, cfg); err != nil {return nil , fmt.Errorf("failed to parse qemu vm config: %v" , err)if cfg.Count < 1 || cfg.Count > 128 {return nil , fmt.Errorf("invalid config param count: %v, want [1, 128]" , cfg.Count)if env.Debug && cfg.Count > 1 {0 , "limiting number of VMs from %v to 1 in debug mode" , cfg.Count)1 if _, err := exec.LookPath(cfg.Qemu); err != nil {return nil , errif env.Image == "9p" {if env.OS != targets.Linux {return nil , fmt.Errorf("9p image is supported for linux only" )if cfg.Kernel == "" {return nil , fmt.Errorf("9p image requires kernel" )else {if !osutil.IsExist(env.Image) {return nil , fmt.Errorf("image file '%v' does not exist" , env.Image)if cfg.CPU <= 0 || cfg.CPU > 1024 {return nil , fmt.Errorf("bad qemu cpu: %v, want [1-1024]" , cfg.CPU)if cfg.Mem < 128 || cfg.Mem > 1048576 {return nil , fmt.Errorf("bad qemu mem: %v, want [128-1048576]" , cfg.Mem)"" , cfg.Qemu, "--version" )if err != nil {return nil , errstring (bytes.Split(output, []byte {'\n' })[0 ])return pool, nil
5. ResourcePool:VM 资源池队列 Guest VM 的资源调配主要是通过ResourcePool 这一结构来完成的,这实际上是一个 存放空闲 VM の idx 的单向队列,决定了 VM 的调度顺序 :
1 2 3 4 5 type ResourcePool struct {int chan interface {}
主要定义了这些方法来操纵资源池队列:
Put() :向队列末尾添加空闲 VM の idxLen() :获取队列长度Take():从队列首部取出 cnt 个成员TakeOne() :从队列首部取出单个成员
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 func (pool *ResourcePool) int ) {defer pool.mu.Unlock()append (pool.ids, ids...)select {case pool.Freed <- true :default :func (pool *ResourcePool) int {defer pool.mu.RUnlock()return len (pool.ids)func (pool *ResourcePool) int ) []int {defer pool.mu.Unlock()len (pool.ids)if totalItems < cnt {return nil append ([]int {}, pool.ids[totalItems-cnt:]...)return retfunc (pool *ResourcePool) int {1 )if ret == nil {return nil return &ret[0 ]
同时有一个 SequentialResourcePool() 函数用以初始化资源池:
1 2 3 4 5 6 7 8 9 10 func SequentialResourcePool (count int , delay time.Duration) make (chan interface {}, 1 )}go func () for i := 0 ; i < count; i++ {return ret
全局管控相关 1. Manager:基本信息 Manager 结构体用于表示一个 syz-manager 的基本信息 ,定义于 syz-manager/manager.go 中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 type Manager struct {string map [string ]bool chan bool bool uint32 uint32 int map [*prog.Syscall]bool map [string ]struct {}map [string ]CorpusItembyte byte int map [string ]bool map [string ]bool map [string ]bool chan chan bool chan *Crashchan chan map [string ]bool map [string ]time.Timemap [uint32 ]uint32 byte bool
这里只说明比较关键的几个字段:
cfg:基本设置信息,对应存放在一个 json 文件中vmPool :所用的 VM Poolreporter:用以报告 crashserv :RPC Server,用以与 Guest 间通信corpusDB:存放语料的数据库targetEnabledSyscalls:测试用例所允许使用的系统调用candidates:待执行测试用例corpus:语料库seeds:用来对语料库变异的种子
2. fuzzing phase syz-manager 中将 fuzzing 流程分为如下的不同阶段:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 const (iota
Fuzzing 结果相关 1. Crash:记录 crash 信息 manager.go 中定义了Crash 结构体用以记录产生 crash 的 VM、机器信息等,真正的 crash 信息主要存放在一个 Report 结构体中 :
1 2 3 4 5 6 type Crash struct {int bool byte
2. Report:单次执行结果报告 pkg/report/rteport.go 中的 Report 结构体用以表示单次执行的结果,包括是否产生了 crash、Oops 的信息等等:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 type Report struct {string string string byte byte int int int bool bool string string int bool
0x02. main():加载配置文件,启动 manager syz-manager 的 main() 函数其实比较简单,主要就是载入配置文件信息并调用 RunManager() :
1 2 3 4 5 6 7 8 9 10 11 12 func main () if prog.GitRevision == "" {"bad syz-manager build: build with make, run bin/syz-manager" )1000 , 1 <<20 )if err != nil {"%v" , err)
👴寻思好像没什么好说的
0x03. RunManager():进行初始化工作 Step 1. 初始化 VM Pool 首先是初始化 VM Pool,这里调用了 vm/vm.go 中的 Create() 来完成 VM pool 的创建
1 2 3 4 5 6 7 8 9 10 var vmPool *vm.Poolif cfg.Type != "none" {var err error if err != nil {"%v" , err)
该函数主要就是获取 VM 类型、封装一个 Env 结构体、调用对应类型 VM Pool 的构造函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 func Create (cfg *mgrconfig.Config, debug bool ) error ) {if !ok {return nil , fmt.Errorf("unknown instance type '%v'" , cfg.Type)if err != nil {return nil , errreturn &Pool{nil
Step 2. 初始化 Manager,载入语料库,建立通信服务器 随后会创建用于存储 crash 的文件夹与一个新的 Reporter 实例:
1 2 3 4 5 6 7 crashdir := filepath.Join(cfg.Workdir, "crashes" )if err != nil {"%v" , err)
接下来创建一个基本的 Manager 实例,然后是四步走:
preloadCorpus():检查 corpus.db 文件是否存在(若不存在则创建)并载入 sys/要fuzz的OS/test 目录下的测试用模板
语料库载入的模板本身类似于 syzlang 文件,例如 sys/linux/pipe:
1 2 3 pipe2(&(0x7f0000000000)={<r0=>0x0, <r1=>0x0}, 0x0)
initStats():注册一个 prometheus 监视器(一个开源的监视&预警工具包)
initHTTP():创建一个 HTTP 服务器并注册一系列的目录(用以供使用者访问)
collectUsedFiles():检查所需文件是否存在
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 mgr := &Manager{"" },make (map [string ]bool ),make (map [string ]CorpusItem),make (map [string ]struct {}),make (map [string ]bool ),make (map [string ]bool ),true ,make (chan bool ),make (chan *Crash, 10 ),make (chan chan bool ),make (chan chan map [string ]bool ),make (map [string ]time.Time),make (map [string ]bool ),
之后创建一个 RPC Server,用以在 Host 与 Guest VMs 之间进行通信:
1 2 3 4 5 if err != nil {"failed to create rpc server: %v" , err)
Step 3. 初始化 dashboard 相关 1 2 3 4 5 6 7 8 9 10 11 12 13 if cfg.DashboardAddr != "" {if err != nil {"failed to create dashapi connection: %v" , err)if !cfg.AssetStorage.IsEmpty() {if err != nil {"failed to init asset storage: %v" , err)
Step 4. 创建【日志输出】协程 接下来会新起一个协程进行数据记录的工作,内部其实就是一个每 10s 进行一次进度采集并输出日志的无限循环 ,主要是采集执行信息、语料覆盖率、crashes 信息等:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 go func () for lastTime := time.Now(); ; {10 * time.Second)if mgr.firstConnect.IsZero() {continue 0 , "VMs %v, executed %v, cover %v, signal %v/%v, crashes %v, repro %v" ,
Step 5. 创建 bench 协程(每隔一分钟最小化语料库并将 bench data 写入 bench 文件) 这里会判断命令行传入参数是否有 bench=,若是则调用 initBench():
1 2 3 if *flagBench != "" {
这里的 flagBench 是一个全局的 flag 变量,golang 提供了一个 flag 包用以处理命令行参数:
1 2 3 4 5 var ("config" , "" , "configuration file" )"debug" , false , "dump all VM output to console" )"bench" , "" , "write execution statistics into this file periodically" )
initBench() 会启动一个协程,主要就是一个每隔一分钟运行一次的循环:
调用 minimizeCorpus() 将语料库进行最小化
向 bench 参数指定的文件当中写入 语料库长度、启动时间、fuzzing 时间\n
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 func (mgr *Manager) if err != nil {"failed to open bench file: %v" , err)go func () for {if mgr.firstConnect.IsZero() {continue "corpus" ] = uint64 (len (mgr.corpus))"uptime" ] = uint64 (time.Since(mgr.firstConnect)) / 1e9 "fuzzing" ] = uint64 (mgr.fuzzingTime) / 1e9 "" , " " )if err != nil {"failed to serialize bench data" )if _, err := f.Write(append (data, '\n' )); err != nil {"failed to write bench data" )
Step 6. 启动 dashboard 协程,进入下一阶段 接下来会启动一个新的协程,主要是 每隔一分钟上报一次 syz-manager 的状态,这里不再展开 :
1 2 3 if mgr.dash != nil {go mgr.dashboardReporter()
最后会简单检查一下 VM Pool ,随后调用 vmLoop() 进入下一阶段:
1 2 3 4 5 6 7 8 9 10 osutil.HandleInterrupts(vm.Shutdown)if mgr.vmPool == nil {0 , "no VMs started (type=none)" )0 , "you are supposed to start syz-fuzzer manually as:" )0 , "syz-fuzzer -manager=manager.ip:%v [other flags as necessary]" , mgr.serv.port)return
0x04. vmLoop():启动 fuzzing,管控整体流程 一、VM 分组,初始化资源池等变量 一开始首先会将所有的 VM 分为两组:一组负责 fuzzing,一组负责复现 crash (maxReproVMs):
1 2 3 4 5 6 7 8 9 10 11 func (mgr *Manager) 0 , "booting test machines..." )0 , "wait for the connection from test machine..." )4 if instancesPerRepro > maxReproVMs && maxReproVMs > 0 {
随后会调用 SequentialResourcePool() 新建一个 ResourcePool 队列,主要负责对空闲 VM 使用顺序 的调控 :
1 instances := SequentialResourcePool(vmCount, 10 *time.Second*mgr.cfg.Timeouts.Scale)
接下来会初始化一系列的变量:
runDone:保存 fuzzing 结果为 crash 的 Crash 队列 pendingRepro:标识待复现的 Crash reproducing:标识某个类型 Crash 是否准备被复现reproQueue:Crash 的复现队列reproDone:Crash 的复现结果stopPending:等待停止标志位shutdown:工作终止标志位
1 2 3 4 5 6 7 runDone := make (chan *RunResult, 1 )make (map [*Crash]bool )make (map [string ]bool )var reproQueue []*Crashmake (chan *ReproResult, 1 )false
最后进入到一个大循环中,这个大循环才是真正的 fuzzing 调控流程
二、外层大循环:调配空闲 VM 进行 fuzz & crash repro,等待处理不同 channel 数据 大循环的终止条件为 shutdown == nil 或是 ResourcePool 中的 VM 数量与总数量不相等,进入循环后首先会获取当前所在阶段:
1 2 3 4 for shutdown != nil || instances.Len() != vmCount {
Step 1. 内层小循环:获取待复现 crash 加入复现队列 小循环会遍历 pendingRepro 中的 crash:
若未被复现则从 pendingRepro 中删除
调用 needRepro() 检查是否需要复现
标记该标题的 crash 已在复现,并加入复现队列中
这里的 crash.Title 其实是 Oops 的第一行文本, 即同一时刻仅会复现同类 crash 中的一个 :
1 2 3 4 5 6 7 8 9 10 11 12 for crash := range pendingRepro {if reproducing[crash.Title] {continue delete (pendingRepro, crash)if !mgr.needRepro(crash) {continue 1 , "loop: add to repro queue '%v'" , crash.Title)true append (reproQueue, crash)
Step 2. 判断是否可以对 crash 进行复现并调控 VM 接下来会输出一行日志,之后定义一个闭包函数 canRepro,用来判断当前是否可以进行 crash 复现 ,主要判断以下三个条件是否满足:
当前阶段是否超过 phaseTriagedHub
待复现队列 reproQueue 是否不为空
加上该 crash 后所有用来复现 crash 的 VM 数量是否小于 maxReproVMs
1 2 3 4 5 6 7 8 log.Logf(1 , "loop: phase=%v shutdown=%v instances=%v/%v %+v repro: pending=%v reproducing=%v queued=%v" ,nil , instances.Len(), vmCount, instances.Snapshot(),len (pendingRepro), len (reproducing), len (reproQueue))func () bool {return phase >= phaseTriagedHub && len (reproQueue) != 0 &&int (atomic.LoadUint32(&mgr.numReproducing))+1 )*instancesPerRepro <= maxReproVMs
接下来是两个小循环:
① 循环启动协程调度 VM 进行 crash 复现 第一个小循环会循环判断是否可以进行 crash 复现:
若可以复现则从资源池队列中取出一个 VM idx,若资源池为空则直接跳出
从 reproQueue 中取出一个 crash,更新 manager 的 numReproducing 计数
启动一个新的协程调用 runRepro() 对该 crash 进行复现,结果输出至 reproDone 队列中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 if shutdown != nil {for canRepro() {if vmIndexes == nil {break len (reproQueue) - 1 nil 1 )1 , "loop: starting repro of '%v' on instances %+v" , crash.Title, vmIndexes)go func ()
而 runRepro() 其实就是 repro.Run() 的 wrapper + 一些错误检查后将 VM idx 放回资源池,这里就不展开了:
1 2 3 4 func (mgr *Manager) int , putInstances func (...int )
Run() 一开始主要是一些检查,之后根据 crash 类型的不同设置不同的复现时间上限:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 func Run (crashLog []byte , cfg *mgrconfig.Config, features *host.Features, reporter *report.Reporter, vmPool *vm.Pool, vmIndexes []int ) error ) {if len (vmIndexes) == 0 {return nil , nil , fmt.Errorf("no VMs provided" )if len (entries) == 0 {return nil , nil , fmt.Errorf("crash log does not contain any programs" )len (crashLog)"" , report.Unknownif rep := reporter.Parse(crashLog); rep != nil {3 * cfg.Timeouts.Program, 20 * cfg.Timeouts.Program,switch {case crashTitle == "" :"no output/lost connection" 0 ], testTimeouts[2 ]}case crashType == report.MemoryLeak:1 :]case crashType == report.Hang:2 :]
接下来会将崩溃信息存储到一个 context 结构体中,并新建一个 WaitGroup:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ctx := &context{make (chan *reproInstance, len (vmIndexes)),make (chan int , len (vmIndexes)),new (Stats),0 , "%v programs, %v VMs, timeouts %v" , len (entries), len (vmIndexes), testTimeouts)var wg sync.WaitGrouplen (vmIndexes))
随后循环获取用以复现的 VM idx 并依次启动新协程调用 CreateExecProgInstance() 创建 VM 并拷贝 crash 程序 ,若失败则休眠 10s 后重试,最多会尝试 maxTry 次;成功的结果会输出到 ctx.instances 中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 for _, vmIndex := range vmIndexes {go func () defer wg.Done()for vmIndex := range ctx.bootRequests {var inst *instance.ExecProgInstance3 for try := 0 ; try < maxTry; try++ {select {case <-vm.Shutdown:continue default :var err error if err != nil {0 , "failed to init instance: %v" , err)10 * time.Second)continue break if inst == nil {break go func () close (ctx.instances)defer func () close (ctx.bootRequests)for inst := range ctx.instances {
CreateExecProgInstance() 主要就是调用 vmPool.Create() 启动虚拟机后调用 SetupExecProg() 拷贝要执行的二进制文件,这里就不展开了:
1 2 3 4 5 6 7 8 9 10 11 12 13 func CreateExecProgInstance (vmPool *vm.Pool, vmIndex int , mgrCfg *mgrconfig.Config, reporter *report.Reporter, opt *OptionalConfig) error ) {if err != nil {return nil , fmt.Errorf("failed to create VM: %v" , err)if err != nil {return nil , errreturn ret, nil
回到 Run() 中,其最后会调用 context.repro() 正式开始复现 crash 的工作 ,检查结果后返回:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 res, err := ctx.repro(entries, crashStart)if err != nil {return nil , nil , errif res != nil {3 , "repro crashed as (corrupted=%v):\n%s" ,for attempts := 0 ; ctx.report.Corrupted && attempts < 3 ; attempts++ {3 , "report is corrupted, running repro again" )if res.CRepro {else {if err != nil {return nil , nil , err3 , "final repro crashed as (corrupted=%v):\n%s" ,return res, ctx.stats, nil
repro() 函数主要分两部分:
extractProg() 的逻辑比较简单:
逆序后调用 context.extractProgSingle() 逐个运行单个程序 ,若某一程序触发了 crash 则直接返回
若单一程序无法触发 crash,则调用 context.extractProgBisect() 使用二分法找出触发 crash 的程序集合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 func (ctx *context) error ) {2 , "extracting reproducer from %v programs" , len (entries))defer func () make (map [int ]int )for i, ent := range entries {var indices []int for _, idx := range procs {append (indices, idx)var lastEntries []*prog.LogEntryfor i := len (indices) - 1 ; i >= 0 ; i-- {append (lastEntries, entries[indices[i]])for _, timeout := range ctx.testTimeouts {if err != nil {return nil , errif res != nil {3 , "found reproducer with %d syscalls" , len (res.Prog.Calls))return res, nil if len (entries) == 1 {continue if err != nil {return nil , errif res != nil {3 , "found reproducer with %d syscalls" , len (res.Prog.Calls))return res, nil 0 , "failed to extract reproducer" )return nil , nil
这两个函数主要就是通过如下调用链来在 VM 中执行程序,这里就不展开了:
1 2 3 4 5 6 context.testProg ().testProgs ().testWithInstance ().RunSyzProg ().RunSyzProgFile ().runCommand ()
② 循环启动协程进行 fuzzing 此时已经不满足可以进行 crash 复现的条件了,因而会有第二个小循环启动新协程将资源池中剩余 VM 调度去 fuzzing , 并将结果输出到 runDone 中:
1 2 3 4 5 6 7 8 9 10 11 12 for !canRepro() {if idx == nil {break 1 , "loop: starting instance %v" , *idx)go func ()
runInstance() 函数实际上会调用 runInstanceInner(),该函数仅当产生了 Crash 时返回的结果才不为 nil,即 runRepro 队列实际上为 Crash 队列:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 func (mgr *Manager) int ) (*Crash, error ) {"vm-%d" , index)if len (vmInfo) != 0 {append (append (vmInfo, '\n' ), machineInfo...)if err != nil {return nil , errif rep == nil {return nil , nil false ,return crash, nil
runInstanceInner() 的核心部分主要是:
调用 vmPool.Create() 创建 VM,调用 inst.Forward() 进行 TCP 转发,拷贝 syz-fuzzer 与 syz-executor 到 VM 文件系统中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 func (mgr *Manager) int , instanceName string ) (*report.Report, []byte , error ) {if err != nil {return nil , nil , fmt.Errorf("failed to create instance: %v" , err)defer inst.Close()if err != nil {return nil , nil , fmt.Errorf("failed to setup port forwarding: %v" , err)if err != nil {return nil , nil , fmt.Errorf("failed to copy binary: %v" , err)if executorBin == "" {if err != nil {return nil , nil , fmt.Errorf("failed to copy binary: %v" , err)0 if *flagDebug {100 1
调用 instance.FuzzerCmd() 生成命令行后调用 inst.Run() 启动 syz-fuzzer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 1 )defer atomic.AddUint32(&mgr.numFuzzing, ^uint32 (0 ))false ,false ,if err != nil {return nil , nil , fmt.Errorf("failed to run fuzzer: %v" , err)
调用 inst.MonitorExecution() 监控 VM 运行,该函数主要是通过获取 kernel oops 来判断是否触发了 crash (KASAN 不会造成 kernel panic,从而使得一个 VM 实例长期运行,不过 dmesg 中仍有 oops)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 var vmInfo []byte if rep == nil {0 , "%s: running for %v, restarting" , instanceName, time.Since(start))else {if err != nil {byte (fmt.Sprintf("error getting VM info: %v\n" , err))return rep, vmInfo, nil
Step 3. 等待处理不同 channel 数据 vmLoop() 的最后主要就是一个大的 select,等待某个 channel 中有数据后进行处理,之后重新跳回等待处理或是开始下一轮循环:
1 2 3 4 5 6 7 var stopRequest chan bool if !stopPending && canRepro() {select {
首先是资源池的 Freed channel,在 Put() 中会将空闲 VM idx 放回资源池后向该 channel 送入一个 true,而这里什么都没有做,笔者估计会在后续版本中更新:
1 2 case <-instances.Freed:
stopRequest 其实是 Manager.vmStop ,这个 channel 会在 VM instance 所实现的 Run() 方法中被使用:
1 2 3 case stopRequest <- true :1 , "loop: issued stop request" )true
当 runDone 中有数据时说明fuzz 产生了 crash ,此时会将产生 crash 的 VM 释放回资源池,将 crash 写入 pendingRepro 表中等待下一轮循环进行处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 case res := <-runDone:1 , "loop: instance %v finished, crash=%v" , res.idx, res.crash != nil )if res.err != nil && shutdown != nil {0 , "%v" , res.err)false if shutdown != nil && res.crash != nil {if needRepro {1 , "loop: add pending repro for '%v'" , res.crash.Title)true
reproDone 中为 crash 的复现结果,这里会保存复现结果并将对应的 crash 从 reproducing 表中删除
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 case res := <-reproDone:uint32 (0 ))false "" if res.repro != nil {1 , "loop: repro on %+v finished '%v', repro=%v crepro=%v desc='%v'" ,nil , crepro, title)if res.err != nil {0 , "repro failed: %v" , res.err)delete (reproducing, res.report0.Title)if res.repro == nil {if !res.hub {else {
shutdown 中有数据则表示收到了终止信号,此时会将 shutdown 置为 nil,终止循环:
1 2 3 case <-shutdown:1 , "loop: shutting down..." )nil
hubReproQueue 上也可能传来 crash,此处将其送入 pendingRepro 表中等待在后续循环中复现:
1 2 3 case crash := <-mgr.hubReproQueue:1 , "loop: get repro from hub" )true
needMoreRepros 是一个传输 channel 的 channel,这里会将一个条件判断结果传入传来的 channel 中并重新跳回等待:
1 2 3 4 case reply := <-mgr.needMoreRepros:len (reproQueue)+len (pendingRepro)+len (reproducing) == 0 goto wait
最后是 reproRequest,该 channel 意为主动进行复现的请求 ,这里会拷贝 reproducing 位图后将其传入传来的 channel 中:
1 2 3 4 5 6 7 8 9 10 case reply := <-mgr.reproRequest:make (map [string ]bool )for title := range reproducing {true goto wait
至此,syz-manager 的基本运行逻辑分析完毕