【PAPER.0x02】论文笔记:Virtual Wall: Filtering Rootkit Attacks To Protect Linux Kernel Functions
本文最后更新于:2023年10月20日 下午
任何 rootkit,终将绳之以法!
0x00. 一切开始之前
笔者的毕业设计完成的要求之一便是需要完整翻译一篇与该领域相关的论文,刚好笔者做的是反病毒相关的,因此就选了《Virtual Wall: Filtering Rootkit Attacks To Protect Linux Kernel Functions》这篇论文
本篇博客说是论文笔记,其实就是一篇完整的论文翻译:)
不过在笔者翻译完之后才发现作者似乎是华人,
感觉有点亏了,毕竟主要是出于翻译的目的,但是却没能体会到原汁原味的 native speaker 的论文
Abstract
如今 Linux 服务器已被在几乎所有的云、数据中心与超级电脑上使用。Linux 内核功能正面临着一种称之为 rootkits 的带有 root 访问权限的恶意软件攻击。rootkits 在如今的 Linux 服务器上以 可装载内核模块 (Loadable Kernel Modules,LKM)的形式出现。这些模块隐藏于其他的内核对象之间,且可以通过篡改内核服务函数所需的元数据来重定向内核控制流。内核 rootkits 在载入后对用户是不可见的,这可能绕过大部分的安全防护。rootkits 在时间与空间上的表现都是分散的,这使其变得难以被发现或移除。为了解决 rootkit 的威胁,我们提出了一种通用的 虚拟墙 (Virtual Wall,VTW)方案以通过跟踪所带来的内核活动来过滤出嵌入了 rootkit 的 LKMs。这种 VTW 本质上是一个带有 rootkit 检测与时间追踪能力的轻量级 hypervisor。通常情况下 Linux 在 Guest 模式下运行,当一个 LKM 的执行损害了 VTW 所设置的安全策略时,OS 控制权将转换到 Host 模式,在 Host 模式的 VTW 及时地启用检测并跟踪 rootkit 事件。换言之,潜在的 rootkit 攻击会被检测、被追踪并被分类以做出有意义的过滤决策。整个检测与追踪过程基于内存访问控制与事件注入机制。实验性质的结果展示了 VTW 防护系统在及时检测与防御内核 rootkit 上是高效的,且执行 VTW 的 CPU 开销小于 2%。相较于其他的防护机制(如 DIKernel 等),我们的 vs 更容易以低性能开销应用于 Linux 服务器。我们还会将我们的系统与七个其他的 rootkit 防御系统进行对比。
Index Terms——访问控制,数据完整性,操作系统安全,内核保护与系统架构。
1 Introduction
由于内核 rootkit 的高权限与因此特性,其被广泛应用于 Linux 服务器的内核攻击中。如今已知的内核 rootkits 大都以 可装载内核模块 (Loadable Kernel Modules,LKM)的形式出现,这些模块可以重定义内核内容函数、隐藏自身并隐藏目标对象。
可隐藏的特性允许内核 rootkit 通过 “基于 host 的” 架构绕过安全工具。自从这些工具更低的权限限制了他们的检测范围,更糟糕的是他们基于 目标操作系统 (target operating system,TOS)环境,这导致检测结果的可靠性必须基于 TOS 的完全安全。不幸的是,内核 rootkit 可以偷偷篡改 TOS 环境以破坏其安全。
为了实现他们的功能,内核 rootkit 需要篡改内核对象。内核 rootkit 的操作对象包括多种数据,例如控制数据、非控制数据、静态数据与动态数据。理论而言,内核安全可以通过限制所有对指定内核数据的窜改来确保。
然而,不同的数据通常在内核空间中分散存储,带有不同特性的数据可能会存放在同一张内存页中。因此,基于页的保护机制无法在不影响其他内核数据的情况下保护目标数据。
在攻击中,内核 rootkit 需要篡改的内核数据通常仅有几字节。同时,最小的内存权限管理粒度为一张页,其通常占用 4KB。也就是说,为了保护数个字节,我们需要限制所有可执行实体对目标数据所在页的写操作。
在数据大小与保护粒度间的不匹配破坏了其他内核对象的原始属性,这影响了相关的执行实体的功能与表现。例如,内核数据结构中的 VFS 函数指针条目通常为内核 rootkit 要篡改的目标数据。尽管该条目并不会被动态更新,与其共址的状态描述条目可能会在执行实体运行时被更新。若对状态描述的写权限被限制,则关联的执行条目将被影响。
内核 rootkit 有着所有的 LKM 特性,他们可以调用自定义函数或装载 rootkit 的导出函数以篡改内核数据。他们可以在装载时或是在他们生命周期的任何时刻启动一次攻击。因此,内核 rootkit 可以是任何将被或已被装载的 LKM,参与到一次攻击的内核 rootkits 便可能是一个或多个 LKMs。
从时间层面,内核 rootkit 的攻击时间是随机的;从空间层面,在一次攻击中的参与者是分散的。这两种特性使得内核 rootkit 的攻击事件难以预测、攻击的参与者难以追踪,这极大地影响了系统安全。
攻击开始时间的随机性使得基于单个或周期性的检测仅能达到时候检测的效果。当这些方法被执行时,内核 rootkits 的攻击可能已经完成了,甚至所有的 rootkits 都可能被移除了。结果便是,他们的检测与防护效果将被极大地影响。内核 rootkits 间的依赖关系使得攻击的形式更加多样化。
透过依赖关系,内核 rootkit 可以连接多个 LKMs 以用作内核攻击。现有的安全方案仅能检测当前攻击的直接发起者,但无法识别在整个攻击过程中的其他参与者。未被检测的攻击者将一直潜伏于操作系统中,等待条件成熟时再次发起攻击。
我们提出了一种内核 rootkit 过滤方法 VTW 以保护内核功能,例如系统调用表、内核只读对象、LKM 状态描述符、"proc" 文件函数指针、网络文件指针等。这种方法使用 Intel VMX 技术以将操作系统分为两种模式:“host” 与 “guest”。
跨过两种执行模式,我们为压紧内核 rootkits 创建了检测、预防、跟踪策略。本论文的主要贡献总结于如下四个技术层面:
1) 建立了一个轻量级的 hypervisor。其使用 Intel VMX 技术来重构系统执行模式,使得对内核资源的访问更能被检测到。
2) 建立了一个资源访问控制机制。其可以感知对目标内存访问的感知、限制、操控,且支持我们在 “guest” 模式下监控与控制执行路径。
3) 建立一个控制流跟踪机制。该机制支持跟踪不同 LKMs 的控制流跳转与返回。
4) 创建了一个检测、防护、跟踪内核 rootkits 的安全框架。通过上述架构与机制,内核 rootkits 攻击可以被检测与防护。这是第一次有一种跟踪单次攻击中所有参与的内核 rootkits 的方法被开发。
2 Related Previous Work
由于其良好的抗干扰能力,基于虚拟化的内核保护方法已经受到了额外的关注。尤其是对内核 rootkits 而言,这些方法展示了出色的优点。他们可以被分为两种:入侵式方法与非入侵式方法,前者需要向 目标虚拟机 (target virtual machine,VTW)注入额外的内容以获取所需信息而后者不需要。
侵入式方法 (Intrusive Methods)。由 Sebastion 最先提出的 X-TIER 将一个内核模块插入到目标虚拟机,接下来其通过模块来读取 TVM 数据结构以获取其状态信息。在这之后 X-TIER 通过 hypercall 将所需信息传递给 hypervisor。
SYRINGE 使用函数调用注入技术来在 TVM 外启用对 TVM 函数的调用,与此同时局部牧羊技术被用于检测控制流完整性。
Virtuoso 继续从控制逻辑的角度获取 TVM 状态信息。其在 TVM 中多次运行程序并提取相关指令与相关执行路径,之后生成内省代码所需的路径被翻译,最后 Virtuoso 将所有的信息翻译成可以在 TVM 外进行语义重构的代码。
X-TIER、SYRINGE、Virtuoso 通过分析物理内存并以其作为真实视角而获得语义视角。他们可以通过对比真实的语义视角与 TVM 的内部视角来找到隐藏的对象,如进程与文件。若存在一个隐藏对象,则他们断定 TVM 已经被破坏而一个内核 rootkit 可能存在于 TVM 中。VMST 在 rootkit 检测上使用同样的方法。
非入侵式方法 (Non-Intrusive Methods)。VMwatch 的第一步是获取 TVM 的内存,之后使用 TVM 的内核数据结构作为模板来理解内存所表示的操作性状态。
与 VMwatcher 不同,RTKDSM 为一个实时系统,其可以被分为两部分:内省代理与监控代理,前者放置在一个安全的虚拟机中,后者则放置在 hypervisor 中。RTKDSM 可以通过交叉对比来对数据结构进行实时监控。
上述方法可以被用以检测被内核 rootkits 隐藏的对象,然而这些方法基于如 Xen 的巨型虚拟化平台,且需要克服虚拟机内省的语义缺陷。结果便是,他们向操作系统引入了一个显著的性能开销。
例如,RTKDSM降低了一些应用 110% 的执行速度。SYRING 在系统调用上延迟到 51ms,这对系统调用而言是一个显著的性能开销。除了 RTKDSM,没有任何的上述方法可以实时监控与检测操作系统。
3 Virtual Wall Architecture
VTW 是一个带有内核 rootkit 防护功能的轻量级 hypervisor。本节我们将介绍其总体架构。
3.1 Assumptions and Notational Definition
我们假设攻击者可以将一个 LKM 注入到 TOS 中。现实中,攻击者可以通过应用漏洞提高权限并通过后门来控制 TOS,之后一个 LKM 可以被注入到内核。我们同样假设 TOS 与非恶意执行实体不会非法篡改内核数据与内核控制流。此外,本论文所用定义展示于表 1 中。
3.2 Design Objectives
VTW 被设计为带有如下指定的三个技术需求:
1) 实时检测 (Real-time Detection)。内核 rootkits 可能在模块加载阶段启动一次攻击,或是在模块位于内存中的时间中的任何时间。若检测在 LKM 被载入后或被移除后完成,则检测结果可能不精确,浙江影响后续的检测与追踪。因此,VTW 需要在模块载入完成前或在其生命周期中检测 rootkits 的有害操作以保护内核数据的完整性。
2) 高效防护 (Effective Defence)。rootkits 操作的内核对象包括静态与动态的内核数据。对于静态内核数据,VTW 需要确认他们未被篡改。对于动态内核数据,VTW 需要确保他们在被篡改后可以被恢复。
3) 综合可追踪性 (Comprehensive Traceability)。攻击代码可能在 rootkit 所属内存空间中,也可能在 rootkit 所依赖的其他模块的代码空间中。VTW 需要定位所有与当前有害操作相关的 LKMs。
3.3 System Architecture of Virtual Wall
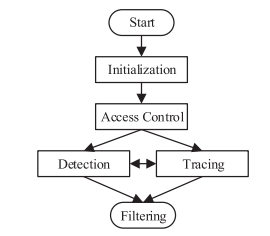
VTW 的防护过程如 图.1 所示。防御模式需要通过初始化来建立,之后应用访问控制方案,最后同时连带完成检测与跟踪以在 rootkit 过滤中进行高速决定。
VTW 的架构如 图.2 所示。VTW 由 ModeHandler、MemHandler、ControlHandler、SPE(Security Policy Engine,安全策略引擎)组成。ModeHandler 的任务是确保在 “guest” 与 “host” 模式之间的正常模式切换。
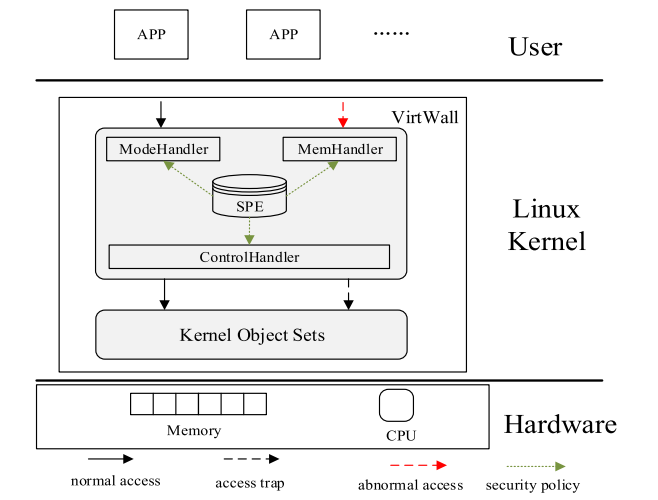
MemHandle 的任务是通过建立一组独立的地址页表来从 “guest” 上隔离安全内容物。此外,其借用 EPT (译注:Extend Page Table,扩展页表)来实现 VTW 的自我防护与透明部署。ControlHandler 完成 rootkit 的检测、预防、分析。
SPE 为每个内容物提供安全策略,例如为静态内核数据提供权限设置、为动态内核数据提供合法性约束、为控制流提供追踪路径。所有对 SPE 的损坏都将导致操作系统从 “guest” 陷入 “host”。
3.3.1 Resetting of OS’s Privilege Mode
ModeHandler 使用 Intel VMX Non-Root 与 Intel VMX Root 来将原生操作系统分为 “guest” 与 “host” 模式。这两种模式将 ring0 分为两个特权级,称为完全型 ring0 与限制型 ring0。在 “host” 模式下,VTW 位于完全型 ring0 级,可以完全接管内核控制流。在 “guest” 模式下,内核位于限制型 ring0 级,任何损坏 SPE 的行为都将造成操作系统陷入到 “host” 模式。
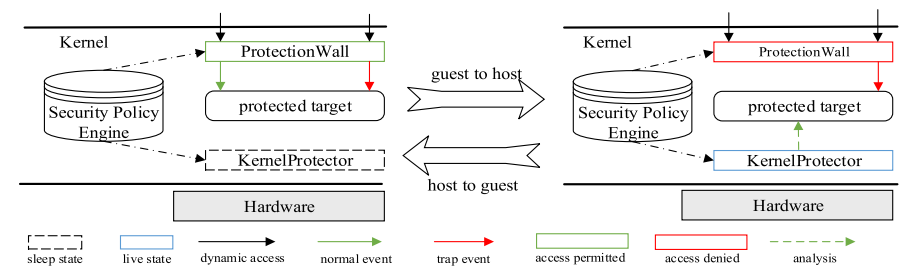
在 图.3 中,ProtectionWall为 ModeHandler 与 MemHandler 的功能属性的抽象,KernelProtector 为 ControlHandler 的功能属性的抽象。
若 guest 模式下的一条指令会损坏安全策略,则其将造成操作系统切换到 host 模式。ProtectionWall 将拒绝所有在 guest 模式下的操作并唤醒 KernelProtector 使用 SPE 处理该攻击。
3.3.2 Creating Private Page Tables
MemHandler 为 host 创建一组私有页表以分割两种模式的地址空间,私有页表的创建条件如 表2 所示。
存储与内核数据段中的内核数据 $swapper_pg_dir$ 指向内核地址空间的页目录,所有执行实体的内核地址空间基于 $swapper_pg_dir$ 构建。在 表2 中,所有私有页表组成一个元组 $\rho$ ,且所有由 $swapper_pg_dir$ 指向的页表组成一个元组 $\varepsilon$ (①~②)。
当 MemHandler 被初始化,其会根据 $\varepsilon$ 创建页目录表($h_pml4e$)、页顶级目录($h_pdpte$)、页中间目录($h_pde$)、页表($h_pe$)。
我们首先基于页表集 $\rho$ (③)的内存 $V_{22}$ 创建一份等量的内存 $V_{1}$ ,接下来我们使用每个 $h_pdpte$ 的物理内存填充 $h_pml4e$ 的条目、使用每个 $h_pde$ 的物理内存填充 $h_pdpte$ 的条目、使用每个 $h_pe$ 的物理内存填充 $h_pde$ 的条目。
最后,MemHandler 拷贝 $\varepsilon$ 的最后的页表中所有的页条目至 $h_pe$ 。当 “host” 中出现一个页表错误时,VTW 根据 $\varepsilon$ 更新错误的页表。
为了确保 VTW 的透明性,MenHandler 建立了一种 EPT 重定向方法,该方法使得 VTW 的内容对 “guest” 而言是不可见的。其根据 VTW 的每个内容物的物理内存重定向 EPT 的页表项至一个被设为可读、可写、可执行(⑧~⑩)的空页。当 “guest” 中的实体想要访问 VTW 的物理内存时,被访问的内存为一个 “$伪页$” (pseudo page)。
由于整个内核共享一个相同的地址空间,每个执行实体可以映射包括 VTW 在内的所有内核内容。因此,VTW 不需要任何过程便能被检测与分析。若我们仅仅删除了寻址 VTW 的 EPT 条目,则当一个实体探索内核地址空间时,操作系统将不断地陷入 “host”。
一方面,频繁的陷入将影响执行效率;另一方面,异常的内存访问时间与空间将使得攻击者推断出 VTW 的存在。将 VTW 的所有地址空间重定向至伪物理页面可以排除由内存探测造成的时间与空间异常,这增强了 VTW 的透明性。
4 Resource Access Control
VTW 通过 MemHandler 控制内存访问。MenHandler 使用 EPT 来控制 “guest” 模式中的内存访问。通过 EPT 提供的内存权限管理,我们可以感知、跟踪、控制 “guest” 对所有内存页面的访问。MenHandler 可以非常简便地通过设置 EPT 最后一级的权限位来部署。
为了达成对内核更细粒度的访问控制,ControlHandler 建立了一个包括设置断点、注入通用保护异常、执行单步调试的事件注入机制。我们将在本节描述这些,并展示于 表3 与 “资源访问控制过程”(Resource Access Control Procedure)。
4.1 Conditioning for Resource Access Control
表3 为设置资源访问控制的条件。①⑨用于设置断点,断点的类型可以依据目标对象分为指令与数据断点。ControlHandler 使用 Dr0Dr3(断点地址寄存器于集合 $DeReg$ 中)与 DR6DR7 (断点管理寄存器,于集合 $DeCon$ 中)来设置不同类型的断点(①②)。
在设置一个指令断点时,首先通过函数 $SetDeReg$ 将指令地址( $Iaddr$ )写入到断点地址寄存器(③),接下来 Dr7 对应的 R/W 位被设置为 01(数据写中断),对应的 LEN 位被设置为 10 (数据大小为 8 字节),如 ⑦⑧所示。在完成断点设置之后,ControlHandler 同样需要清除 Dr6 (⑨)的 B0B2 (位 2:0)。
为了控制 “guest” 的执行,ControlHandler 为操作系统设置单步执行调试。ControlHandler 首先读取 VMCS 中 guest 状态域中的 EFLAGS 的内容,记录目标信息(⑬)。接下来其将 EFLAGS.TF (陷阱标志位)设置为1(⑭),这将处理器设为单步执行模式。最后,ControlHandler 将修改后的内容再次写入 EFLAGS。最后 Dr6 的 BS(位 14)被设为 0。
4.2 Resource Access Control Procedure
该程序用以控制指令执行与数据访问。步骤 14用以获得断点,步骤 56 用以堵塞 “guest” 中的目标指令,步骤 7~8 用以在执行目标指令后获取操作系统的状态。

当一个执行实体像一个断点位置写入数据(步骤12)或是在 “guest” 模式下执行一个断点指令(步骤 34),其会触发到 “host” 模式的模式切换($SysMod$)。Dr6 中的 B0 ~ B2 被用以区分断点的位置。通过设置断点,VTW 实现了字节级别的资源访问。
当一个通用保护被设置,运行在 “guest” 模式下的操作系统将生成一个 #GP 异常,由此当前操作将会被阻塞(步骤 5~6)。当单步调试启用,操作系统将在 “guest” 下执行任意指令后触发一个调试异常并陷入到 “host” (步骤 7 ~ 8 )。通过设置单步调试,我们可以为操作系统实现指令粒度的资源访问控制,并通过 $get_status$ 获得由每条指令所造成的对操作系统状态的改变。
5 Rootkit Defense Strategies
我们依据攻击时间将内核 rootkits 的攻击分为三类。第一类中 rootkits 在加载时攻击内核,其会通过 $module_init()$ 调用特定函数以实现他们的攻击。
内核 rootkits 的有害行为可能在以上三类攻击中的其一或数个中出现,同时与当前攻击所关联的 rootkit(s) 可能会是正在被加载的 LKM、已加载的 LKM,抑或两者都是。
VTW 决定一个 LKM 是否为一个内核 rootkit。对于内核 rootkits,VTW 通过阻塞他们的破坏行为并恢复被破坏的数据来对抗他们。rootkit 检测方法如 “Rootkit 攻击检测” 所示,条件设置展示于 表4 中。该方法可以被用以预检测静态与动态的内核对象。
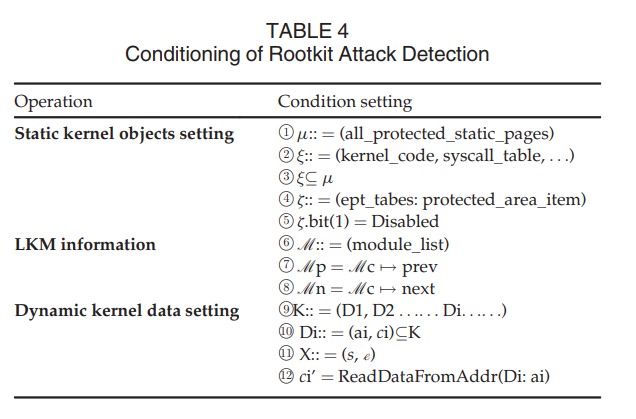
Rootkit 攻击检测 (Detection of Rootkit Attacks)。其被用以检测内核 rootkit 并保护内核不被摧毁。步骤 1 ~ 5 用于静态内核对象保护,步骤 6 ~ 8 用于隐藏检测,步骤 9 ~ 11 用于动态内核对象保护。

5.1 Static Kernel Object Protection
静态内核对象($\mu$ 与 $\xi$)在操作系统中保持不被改变。特定的内核控制流执行路径与一些重要的数据被存放于静态内核对象中。内核 rootkits 可以通过破坏静态内核对象的完整性来达成他们的恶意目的。
为了保护静态内核对象(如操作系统代码段、数据段、系统调用表等),VTW 通过分析文件 $”System.map”$ 或从内核代码段提取以获得他们的线性地址,并将其翻译为物理地址。
之后,VTW 设置标识这些物理地址的 EPT 条目($\zeta$)的写权限为 “不可写”(表4 中的 ④ ~ ⑤)。在 “guest” 模式中,对静态内核对象的写操作($WriteTo$)将触发 “EPT violation” 造成操作系统陷入到 “host” (“Rootkit 攻击检测” 中的 步骤 1)。接下来,VTW 注入一个 #GP 异常($InjectGP$) 到 “guest” 中以预防 LKM 摧毁内核数据(步骤 2)。
需要注意的是最小的内存保护粒度为一张 “页”。然而并非所有的静态内核对象都占用完数个页,因此当一个 “EPT 损坏” 异常被抛出,VTW 首先确认异常地址是否属于被保护对象的地址范围。
若是,则当前操作会被阻塞,若否,则 VTW 将设置 “guest” 为单步执行模式(步骤4 中的 $SingleStep$ )。接下来其将页设置为 “可写的” (步骤 5)。最后 VTW 将操作系统切换回 “guest” 模式以完成后续的写入。在这之后,操作系统重新陷入 “host”,VTW 通过函数 $OpenWrite$ 将页恢复到 “不可写” 。
5.2 Dynamic Kernel Object Protection
内核 rootkits 可以通过篡改动态内核数据来达成如劫持控制流的恶意目的。被篡改的内核数据包括控制数据与非控制数据,前者指的是指向内核控制流的指针。
这些指针通常被用于构造语义视角,例如存储于 $”proc”$ 文件系统中的函数指针。后者则指某些状态描述符中的一些条目,如 $”struct module”$ 中的条目 $”prev”$ 与 $”next”$。
实时更新的内核数据与被 rootkits 篡改的目标数据可能会存放在同一张页中,因此我们无法通过限制内存页的写权限来预防内核 rootkits 篡改内核数据。
此外,攻击时间的随机性使得实时检测篡改操作变得困难。面对这些问题,VTW 跟踪 LKMs 的执行,并在 LKM 追踪中检测动态内核数据。
5.2.1 Hidden Kernel Detection
自我隐藏是内核 rootkit 的基本特性,隐藏行为可以被作为判断一个 LKM 是否为一个 rootkit 的标准。通常情况下,内核 rootkits 在初始化时实现自我隐藏。
因此,VTW 需要在其初始化完成之前检测其是否被隐藏。为了追踪模块初始化,我们在 $sys_init_module()$ 设置了一个指令断点并监控 LKM 的状态改变。当状态被切换到 $MODULE_STATE_LIVE$ 时,VTW 会检查模块是否被隐藏。内核 rootkits 通过从链表上移除他们的状态描述符来破坏与其他对象的逻辑连接以进行隐藏,LKMs 之间的逻辑连接可以被用来确认模块是否被隐藏。
$\mathscr{M}$c 为 LKM 正在被装载,$\mathscr{M}$p 为被$\mathscr{M}$c 中的条目 $prev$ 指向的模块,$\mathscr{M}$n 为被 $\mathscr{M}$c 中条目 $next$ 所指向的模块(表4 中的 ⑦~⑧)。若模块 $\mathscr{M}$c 与其相邻节点并不存在链表连接关系(“Rootkit 攻击检测” 中的步骤 6 ),或连接关系不完整(步骤 7 ~ 8),则我们判断 模块 $\mathscr{M}$c 被隐藏了。
5.2.2 Dynamic Kernel Data Detection
除了状态描述符外,内核 rootkits 还会篡改带有控制属性的内核数据以进行内核控制流重定向。在重定向前这类内核数据又指向内核代码段的指针组成,内核 rootkits 重写指针以重定向到他们的自定义代码。
被重定向的对象主要包括多种用于构建操作系统语义视角的操作函数。$”proc”$ 文件系统中的函数指针(例如 $lookup$)对内核 rootkits 而言为最脆弱的对象,因此有必要保护这些函数指针不被篡改。
为了隐藏网络连接(例如网络端口),内核 rootkits 还会攻击 $”/proc/net/tcp”$、$”/proc/net/tcp6”$ 、$”/proc/net/udp”$ 、$”/proc/net/udp6”$ 中的数据,因此这些文件描述符中的函数指针同样需要被保护。
除了上述内核对象,VTW 还要将如 $”root”$ 与 $”log”$ 这样关键文件的函数指针作为保护对象。所有的函数指针与他们的存储地址可以在 VTW 初始化中通过特定的数据结构(如 $f_dentry->d_inode->i_op->lookup$)从内存中提取。
所有被提取的数据形成一个集合 $k$ ,$k$ 中所有的动态内核数据指向固定的内核函数且不需要被更新。仅当我们发现一个新的内核 rootkit 修改一个不在 $k$ 中的某些内核数据时我们才扩展 $k$。此外,VTW 通过 EPT 将 $k$ 设置为读写保护,并禁止 “guest” 中的执行实体访问 $k$ 以保护他。
现在 $k$ 占用大概 64KB 的内存且包含 4000 份内核数据,其将根据新 rootkits 的突发情况而增长。在实战中,现有的内核 rootkits 通常修改不超过 500 份内核数据。我们将范围扩大以进行更好的保护。
$k$ 中的每个元素 $D$ 对应一个独特的内核对象(表 4 中的 ⑨)。元素 $D$i 作为二元数据对 ($a$i,$c$i)存在,$a$i 表示被保护的数据的地址,$c$i 则表示数据内容(⑩)。X 为内核代码范围$s \sim _\mathscr{e}$ (⑪)的范围。
在 LKM 的执行中,VTW 会检测地址 $a$i 上的内核数据 $c$i$’$ 是否指向内核代码段(⑫)。若存在 $c$i 并不指向内核代码段,则其可以确认内核控制流被重定向了(“Rootkit 攻击检测” 中的 10)。在检测到被篡改的内核数据 $c$i$’$ 后,VTW 读取在 $D$i 中保存的 $c$i 并将其写入到 $D$i.$a$i (步骤 11)。之后被篡改的内核数据恢复到了其初始值。
与内核 rootkits 不同,合法的 LKMs 不会修改状态描述符以进行自我隐藏,也不会修改带有系统函数指向特性的扩展数据以进行控制流重定向。
此外,我们保护动态内核数据的方法为在 LKM 执行的特定阶段检查被保护数据的完整性(例如调度与跳转),而非限制所有执行实体对属于内核数据的数据结构的访问。结果便是 VTW 可以从所有的 LKMs 中识别出 rootkits 且不会影响到其他 LKMs 的执行。
5.3 Bypassing Resistance of VTW Effects
以 VTW 的加载时间作为分界点,LKMs 可以被分为已被装载的 LKMs 与未被装载的 LKMs。当 VTW 被成功加载后,其可以及时监控并控制所有未被装载的 LKMs 的装载与执行,使其无法绕过检测。
对于在 VTW 载入前被装载的 LKMs,VTW 无法在 “host” 模式下常规地检测与跟踪,因为这会提高绕过 VTW 的风险。
有两个解决该问题的方法。其一是将 VTW 设为开机时启动,这样绝大部分的 LKMs 都会被包含在监控范围内,然而这种办法对于那些同样在开机时启动的 LKMs 而言仍是无效的。
第二种方法便是使用内核完整性检查的办法来定位有害的 LKM。被重定向的控制流属于 rootkits,可以通过将 LKM 列表中的控制流地址($mal_addr$)与每个代码段($module->core,module->core+module->core_size$)进行配对以确定 rootkit 是否已被隐藏。若是,$mal_addr$ 将被作为定位隐藏 LKM 的起始点。过程如 图.4 所示。
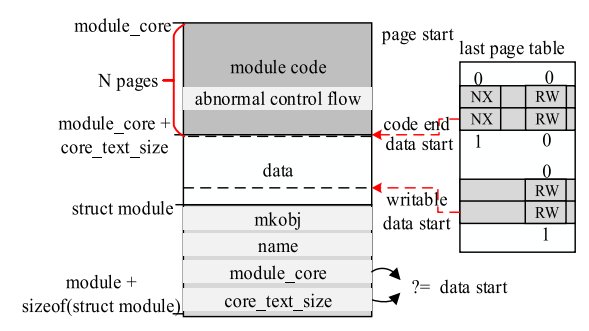
LKM 的代码段与数据段在虚拟空间中是连续的,他们的最后一级页表项是相邻的。因此,通过使用他们之间不同的可执行性(最后一级页表项的 NX 位),代码段的末尾地址($code_end$)与数据段的起始地址($data_start$)可以被识别。
在这之后,我们使用数据段的读写权限(最后一级页表项的 RW 位)来获得可写数据段的起始地址($writable_data_start$)。LKM 的状态描述符($struct\ module$)便存放在可写数据段中。
根据 LKM 代码段按页对齐的特性,代码段的起始地址为 $data_start$-$N * page_size$ ,其值为 $module->module_core$。从 $writable_data_start$ 开始,我们假设每个字节的起始地址便是 LKM 代码的第一个地址。
接下来我们基于 $module->module_core$ 与 $module->core_text_size$ 间的相对位移计算 $module->core_text_size$ 的地址,对 $module->module_core$ 与 $module->core_text_size$ 的正确表示为最后 12 位都为0、两者总和位 $data_start$。
之后我们以一个单字节作为步长检查所有在 $writable_data_start$ 之后的内存,直到我们获得合适的 $module->module_core$ 与 $module->core_text_size$ 。最后,module 结构体的第一个地址使用与 $struct\ module$ 相关的 $module->module_core$ 的偏移进行计算。相比于第一种方法,这种方法有着更大的范围,但实现过程相对更加复杂。 VTW 同时使用两种方法来达成最佳的防护效果。
6 Rootkit Tracing Process
内核 rootkit 可能在 LKM 正在加载时或已被加载后发动攻击,单次攻击的参与者可能是单个或多个模块。
我们将修改内核数据的直接发起者作为行为载体,攻击的最初发起者称为动作载体,其代码替换了原始内核函数的 LKM 称为函数载体。
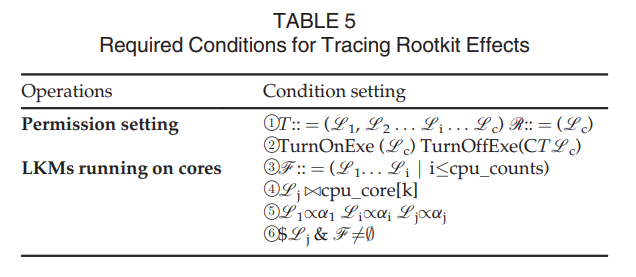
为了追踪所有参与了一次攻击的内核 rootkits,VTW 带来了两种新的方法:“跟踪此前与此后的 rootkit 攻击” 与 “攻击回放程序”,这些方法所需的条件如 表5 所示。
其他参与了攻击的 LKMs 被称为过程载体。这些载体之间可能存在重叠,例如正在被装载的 LKM 可以重定向内核控制流到导出函数,在这次攻击设想中,LKM 同时属于动作载体与行为载体,被装载的 LKM 属于函数载体,不存在过程载体。
所有被监控的 LKMs 形成了元组 $T$ ,所有参与了同一事件的 LKMs 形成了元组 $\mathscr{R}$ (表5 中的①)。当一个 LKM 正在运行,我们开启其执行权限,同时除了在其他 CPU 核心上正在运行的 LKMs 以外,其他所有 LKMs 的执行权限都被关闭(②)。所有运行在不同核心上的 LKMs 形成一个元组 $\mathscr{F}$ (表5 中的 ③)。要被调度以执行的 LKM ($\mathscr{F}$j)与第 k 个 CPU 核心关联(④),LKM 所属的内存被记录为 $\alpha$ (⑤)。
6.1 Trace LKM Execution Events
有三种执行 rootkit 的方式,第一种为 LKM 在模块加载时调用其初始化函数,在这种情况下攻击可能在加载完成前被启动。
第二种为 LKM 在完成载入之后其导出函数被其他模块调用,被加载的 LKM 可以被调用以修改内核数据,或是被用作函数载体来替换内核的原始函数。
第三种为 LKM 被通过创建一个内核线程而执行,攻击可以在线程生命周期的任意时间被触发。
一个完整的攻击可能包括一种或多种上述的执行。为了监控 LKM 的执行,VTW 设置了目标已被装载 LKMs 为不可执行。
然而由于大量的内存设置操作,这种办法是低效的。以一个有着 4MB 代码段的 LKM 为例,VTW 必须要操作 EPT 页表多余 2000 次以完成一次执行权限的开启与关闭。为了减少页表设置操作的数量,VTW 建立了一种机制来管理 LKM 的执行权限,如 图.5 所示。
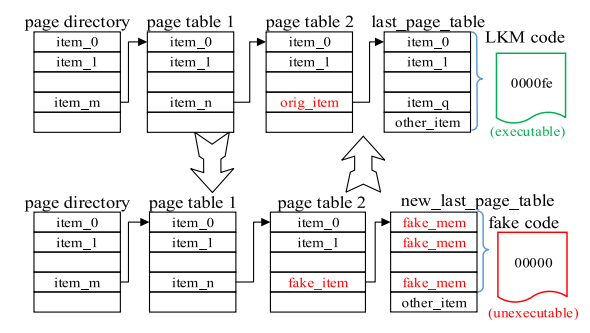
VTW 首先通过 $”struct \ module”$ 获得 LKM 代码段的地址范围,接下来其计算最后一级可以查找整个 LKM 代码地址范围的页表($last_page_table$)。在其上层页表保存了 $last_page_table$ 地址的页表入口 ($orig_item$ )将会被记录。
在这之后,VTW 创建一个新的页表 ($new_last_page_table$) 并通过 EPT 将其设为 “不可写”。其会使用 $new_last_page_table$ 的地址覆写 $orig_item$。接下来 VTW 将 $last_page_table$ 的所有内容拷贝到 $new_last_page_table$ 中。与此同时其会为每个目标 LKM 创建一份内存页并通过 EPT 将其设为 “不可执行”,该内存页被称之为 $fake_code$,其地址则为 $fake_mem$。
最后, LKM 的代码段 在 $new_last_page_table$ 中对应的的所有条目都被填充为 $fake_mem$,若我们尝试打开 LKM 的执行,则 $orig_item$ 将被用 $fake_mem$ 重写。由此,控制流将会被重定向到 $fake_code$ 上。 EPT 异常地址($fake_item$)将说明哪一个 LKM 将要被执行。
在 LKM 执行中,第一个被执行的 LKM 称之为第一个模块,发出了模块间调用请求的 LKM 被称为活动模块,被调用的 LKM 被称为被调用模块。
在第一个 LKM 被执行前,VTW 读取调用函数储存在内核栈上的返回地址并在此处设置一个执行断点,接下来 VTW 启用 LKM 的执行权限。当控制流在 LKMs 之间切换时,我们追踪控制流流过的所有 LKMs。追踪方案如下所示。
6.2 Forward Versus Backward of Rootkit Attack
rootkits 攻击在如下所示的 11 个步骤的前向与后向阶段中被实施。该方法用以监控 LKM 控制流的跳转与返回。步骤 1 ~ 6 监控跳转,步骤 7 ~ 11监控返回过程。

由于对 LKM 的权限设置,在该过程中任何在 LKMs($ConFlowTrans$)间的控制流的跳转都将触发操作系统陷入到 “host” (步骤 1)。VTW 通过所流过的控制流记录每一个 LKM (步骤 2),并检查每个跳转的内核数据的合法性。若数据合法(步骤 3),VTW 将开启被调用模块的执行权限($TurnOffExe$)并关闭活跃 LKM 的执行权限 ($TurnOnExe$,步骤 4)。否则,VTW 通过函数 $HandleException$ 处理非法的 LKM(步骤 5 ~ 6),并处理包括数据恢复($RecoverData$)与 #GP 注入($InjectGP$)的操作。
当 LKM 的控制流返回时($ControlFlowRet$),VTW 跟踪返回动作(步骤 7 ~ 11),当返回到设置在第一个 LKM 的返回地址的断点时,意味着当前的执行完成了。
当活动的 LKM 提交了一个在 LKMs 间的调用请求或是控制流返回到之前的 LKM,VTW 将检测是否当前的内核数据已经被活动的 LKM 篡改了。对于动态内核数据,VTW 使用 “Rootkit 攻击检测” 方法进行检测。
对于有着写保护的静态内核数据,任何的篡改都将导致操作系统陷入到 “host”,之后 VTW 将操作系统设置到单步调试并启用对内核数据的写权限。由此,在 LKM 完成对静态内核数据的篡改后,其会再次陷入到 “host”。最后 VTW 读取被篡改的数据并使用备份数据中的初始值进行恢复。
通过上述操作,VTW 可以获得篡改的数据,将篡改的数据与所有 LKMs 的代码段范围进行对比,我们可以得知重定向控制流所属的 LKM。
若检测到内核数据被篡改了,当前运行的内核模块将被认为是攻击的行为载体,第一个模块将成为动作载体,重定向控制流所属的模块则成为函数载体。
其他的 LKMs 将成为过程载体。为了预防更多的伤害,VTW 向当前控制流注入一个通用保护异常。最后,被篡改的内核数据将被复原,当前的有害操作将被终止。
6.3 Task Switching in Multicore Execution
当 LKM 执行时发生了任务切换,LKM 的 CPU 资源将被收回。若 LKM 不再被调度,其将永远不会产生模块间调用请求,我们在返回地址设置的执行断点将永远不会被执行。由于缺乏触发条件,VTW 将在最后一次检测后忽略掉 LKM 在内核上的影响。
不同的 LKMs 可能被在多个核心上并行执行,这可能影响对行为载体的识别,例如两个 LKMs 可能同时在不同的 CPU 核心中运行。若动态内核对象被检测到在其运行时被篡改,我们无法算出这两个 LKMs 中的哪一个进行了有害操作。
为了确保精确的可追踪性,VTW 引入一个动作回放方法,在 “攻击回放程序”(Attack Playback Procedure)中展示。当一个 LKM 被调度以执行且在其他核心上有一个或更多 LKMs 正在被执行,则该方法会被启动。
6.4 Attack Playback Procedure
当多个 LKMs 同时跑在多个核心上时,该方法用以辨别哪一个 LKM 为内核 rootkit。攻击回放程序如下所示,步骤 1 ~ 5 为所需内容,步骤 6 ~ 9 进行回放。当 LKM $\mathscr{L}j$ 被载入在一个核心上运行时($LoadOnCore$),该执行必须触发操作系统陷入到 host 模式(“攻击回放程序” 中的 步骤 1)。在这之后, $\mathscr{L}j$ 将被记录到元组 $\mathscr{F}$ 中(步骤 2)。
VTW 首先通过函数 $CheckKernel$ 检查当前的内核数据完整性是否被破坏,若未被破坏(步骤 3),其会拷贝当前的 CPU 上下文信息、内核栈、LKM 代码段(所有这些称作回放上下文)。

若有多于一个 LKM 运行在不同的 CPU 核心上,所有运行中的 LKMs 都已被备份,由此我们只需要备份要被执行的 LKM(步骤 4 )。若仅有一个运行中的 LKM,正在被执行的 LKM 与将要被执行的 LKM 都需要要被备份(步骤 5)。在完成备份后,VTW 将操作系统再次切换回 “guest” 模式以继续运行。
为了算出哪一个 LKM 为内核 rootkit,所有的动作都会被通过 $ForEach$ 与 $ExeBack$ 函数为所有在其他核心上运行的 LKMs 逐一进行回放。回放步骤如 图.6 所示,回放过程为如下所示的五个步骤:
1) 使用之前备份的内容重写当前内核栈与 LKM 的数据。
2) 使用备份的 CPU 上下文填充 VMCS 的 “guest filed” 并恢复被破坏的内核数据。
3) 将操作系统切换到 “guest” 模式以开始 LKM 执行。
4) 在内核数据被摧毁的指令位置停止执行。
5)检测是否一个被破坏的数据将触发二次破坏。当前的 LKM 为行为载体。若该内核数据保持完整,则切换到步骤 (1) 恢复回放。
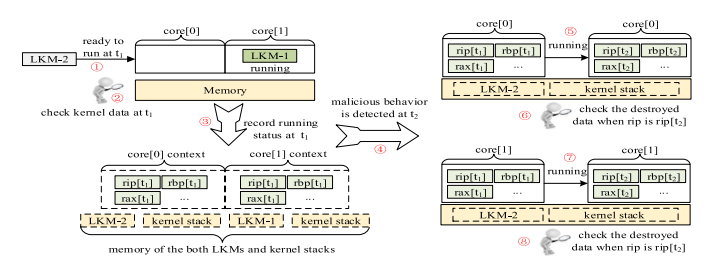
通过该方法,每个 LKM 都将会从内核数据未被摧毁的位置开始执行,并停止在内核数据被摧毁的位置。若被回放的 LKM 破坏了内核数据的完整性,其将被识别为 rootkit(步骤 9)。
在追踪完成之后,VTW 将为剩余的 LKMs 恢复执行,并让他们从内核数据完整性被破坏的位置继续执行。
在动作回放过程中,被恢复的内核数据包括被篡改的内核数据与回放上下文,对前者的恢复将维持内核的完整性,后者则仅与被回放的 LKM 相关。由此,被恢复的内核数据并不会影响其他 LKMs 的执行。
我们分析了 23 个内核 rootkits 并发现除了回放上下文以外,他们不会修改其他内核数据。在对 72 个在 Linux 中被频繁使用的普通 LKMs (例如 $nf_nat,ib_cm,snd_seg$ 等)的监控过程当中,我们发现普通的 LKMs 将不会修改被保护的内核数据,也不会修改在回放上下文以外的任何东西。
由此,在进行动作回放时我们并不需要恢复除了被篡改的内核数据与回放上下文以外的内核数据,这并不会影响其他 LKMs 的正确性。
7 Experiments And Performance Analysis
我们使用几个内核 rootkit 与基准测试来测试 VTw 的防护效果与运行效率。
7.1 Experimental Environment
实验中的物理 host 为一个有一颗 Intel i3-9100 @ 3.6 GHZ 4核心处理器、8G内存、256G硬盘的 HP 桌面电脑。不同 rootkit 的安装环境是非常不同的,为了安装 rootkit $f00lkit$,我们使用 Ubuntu 12.04 与内核 3.2.16 作为被测试操作系统。
7.2 Rootkit Detection, Defence, and Traceability
$f00lkit$ 通过修改系统调用表来隐藏目标对象,其将控制流重定向到其自己的代码段上。VTW 在 $f00lkit$ 上的检测效果如 图.7 所示。
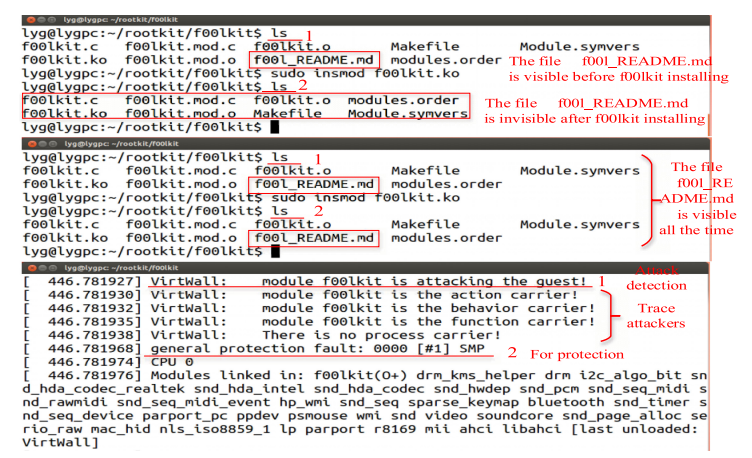
上、中、下三个窗口分别为在 VTW 载入之前对操作系统的入侵表现、在 VTW 载入后对操作系统的入侵表现、VTW 的防护结果。在上面的窗口中,我们发现 $f00lkit$ 可以隐藏以 $”f00l_“$ 开头的文件,如第二行所示。
中间的窗口显示了在 VTW 载入后 $f00lkit$ 不再对以 $”f00l_“$ 开头的文件有着隐藏的效果,当 $f00lkit$ 尝试修改系统调用表时,VTW 检测到了其意图并生成一个 “EPT violation”,之后 VTW 将一个 #GP 提交到 “guest” 进行预防。
为了测试 VTW 的可追踪性,我们重写了 rootkits $f00lkit$ 与 $xingyiquan$ ,并引入了两个辅助的 LKMs $jmp_lkm$ 与 $action_lkm$ ,在我们设置的攻击场景中,$f00lkit$ 并不会摧毁内核数据,其有一个用于替换系统函数以隐藏以 $”f00l_“$ 开头的文件的导出函数 $func_1$。
在辅助 LKM $action_lkm$ 中还有一个导出函数 $func_2$ 。当 $func_2$ 被执行时,其会篡改内核数据并将系统控制流重定向到 $func_1$ 。在辅助 LKM $jmp_lkm$ 中的导出函数为 $func_3$ ,在 $func_2$ 执行过程中 $func_3$ 会被调用。
上述三个导出函数直到被其他 LKMs 调用时才会被执行。当 $xingyiquan$ 执行时, $func_3$ 被 $xingyiquan$ 调用,最后内核函数被通过 $func_2$ 重定向至 $f00lkit$。
LKM $action_lkm$ 直接篡改系统调用表,其为一个行为载体。原有的系统调用函数被 $f00lkit$ 中的函数所替,由此,VTW认定 $f00lkit$ 为一个函数载体。该次攻击的第一个发起者为 $xingyiquan$,其通过 $lkm_jmp$ 使得控制流跳转到其他模块,由此 $xingyiquan$ 被确定为动作载体,$jmp_lkm$ 被确定为过程载体。
VTW 检测、防御、追踪包括 $adore$-$ng、kbeast、wnps、brootus、diamorphine、z$-$rootkit、suterusu$ 等在内的内核 rootkits。VTW 通过 EPT 页表为如系统调用表的内核对象设置写保护,由此,任何写操作都将导致操作系统从 “guest” 模式陷入到 “host” 模式。
之后 VTW 使用 #GP 异常来防止非法操作。内核 rootkits 的整个执行过程都被 VTW 所监控。通过操控 LKMs 的执行权限,VTW 可以夺取每个 LKM 的执行。由此,LKM 的调用、跳转、返回都被同步记录。
7.3 Performance Evaluation
在本节中, VTW 在 CPU 上的执行开销将被使用 $nbench$ 测量,对系统延迟与带宽的影响将被 Lmbench 测量,对 I/O 的影响将被 IOMeter 测量。所有的结果都在原生操作系统测试中进行了标准化。
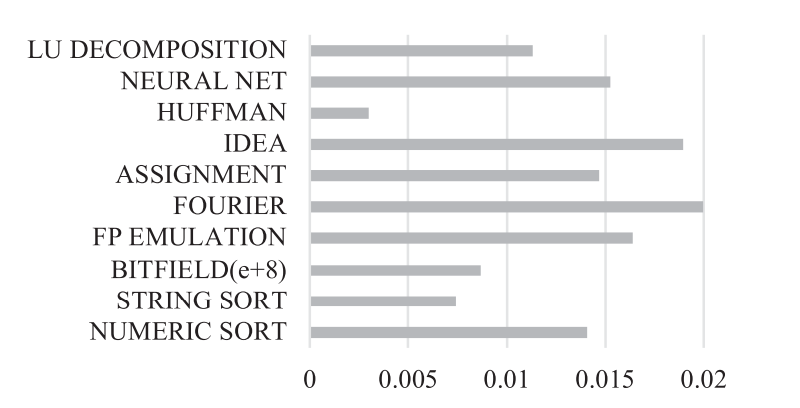
$Nbench\ Test$。测试结果如 图.8 所示。VTW 引入了小于 2% 的 CPU 开销。VTW 本质上是一个轻量级的 hypervisor 且不提供如其他虚拟化平台(例如 Xen)那样复杂的虚拟化功能。由此,其带给 CPU 的性能开始非常小。
$Lmbench\ Test$。Lmbench 被用以测量系统延迟与贷款。测试结果如 图.9a、9b、9c 所示。VTW 增加了平均 8.8% 的内存与网络延迟与平均 5.9% 的文件操作延迟。通信带宽减少了 2.2%。
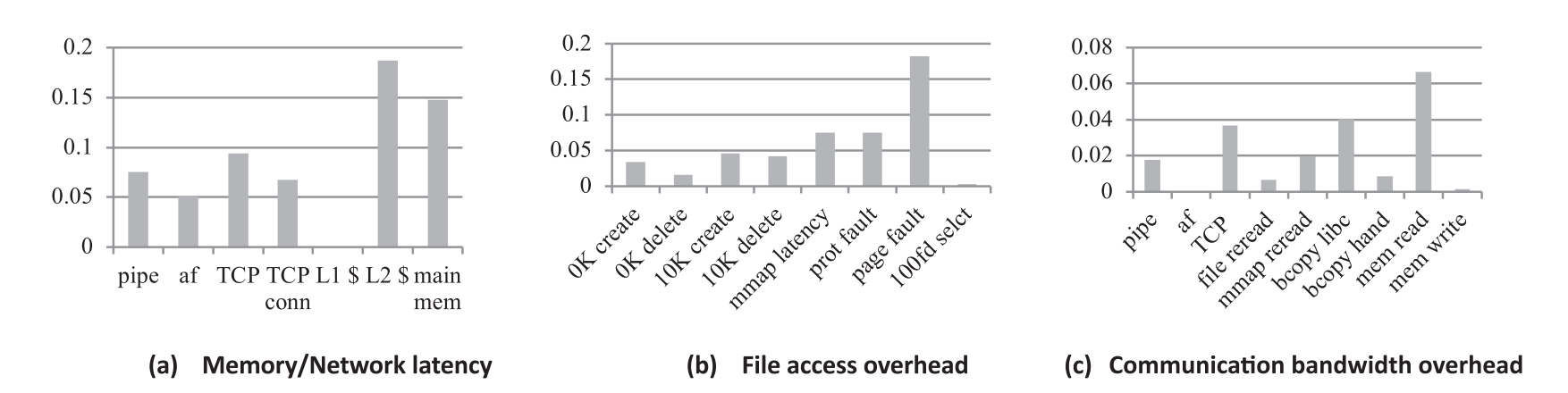
在 Lmbench 测试中,我们发现 OS 在 “host” 与 “guest” 间的切换频率显著地增长了,大部分的切换由指令 $cpuid$ 引起。由于缓存操作速度非常快,其对于任何的延迟都是极度敏感的。由此,在缓存上的模式切换的影响是尤其明显的,导致了将近 20% 的延迟开销。
$IOMeter Test$。IOMeter 是由 Intel 开发的一个用以测试最大磁盘 I/O 性能与最大数据吞吐量的一个测试工具测试结果如 图.10a、10b 所示,该图展示了 VTW 造成了平均 8.9% 的 I/O 带宽减少,与平均 3.9% 的运行时间增长。
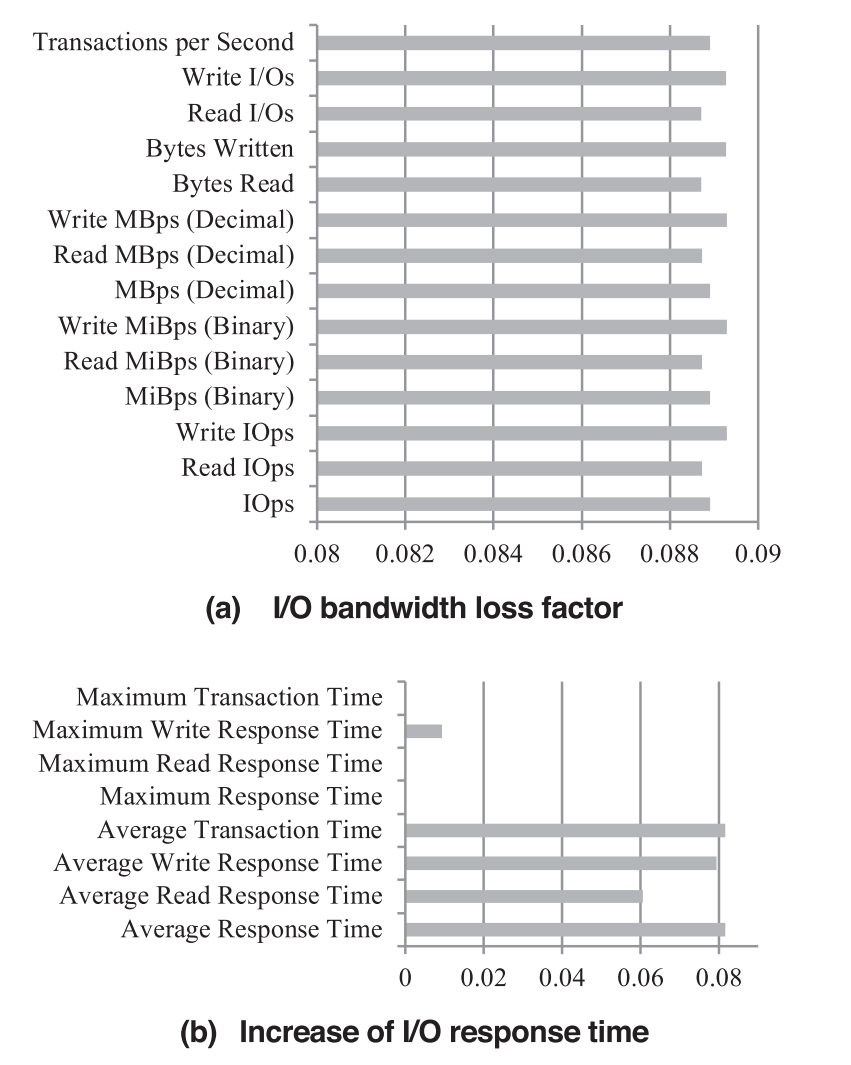
VTW 在 I/O 上的影响主要由 I/O 操作的运行时间导致,这减少了 I/O 吞吐量且增加了 I/O 响应时间。由 VTW 引入的开销包括存储与计算开销。
存储开销主要指内存开销,包括内存空间开销与寻址时间开销。 VTW 占用不多于 200KB 的内存空间来存储其核心代码与数据,以及 64KB 以存储被保护的内核数据。
计算开销来自由 VTW 带来的事件注入、内核保护与异常处理,这些操作将造成操作系统从 guest 模式陷入 “host” 模式。
在 host 模式中,VTW 将接管控制流并进行异常处理。在异常处理完成之后,VTW 将操作系统切换回 “guest” 模式,并将控制流返还给操作系统进行后续执行。
在整个过程中 “guest” 模式的执行始终是被阻塞的,因此如执行速度、延迟、网络延迟、I/O 吞吐这样的表现指示器将会受到影响。此外,模式切换造成对 TLB 与缓存的刷新,这将增加对操作系统的性能影响。
当 VTW 正在运行,导致操作系统进行模式切换的因素包括指令陷入与事件陷入,前者由对特定指令的执行触发,后者由特定事件触发。在 guest 模式中,对指令 CPUID、GETTSEC、INVD、XSETBV 与除了 VMFUNC 以外的所有 VMX 指令都将导致操作系统无条件地陷入到 “host”。
触发操作系统模式切换的事件包括模块加载、模块卸载、在模块加载时的状态切换、模块间的跳转与控制流返回、模块调度执行、“host” 私有页表的更新、篡改静态内核数据、单步调试模式、动作回放。
$Impact on the Execution Speed of LKM$。为了测量 VTW 在 LKM 执行速度上的影响,我们引入了两个测试模块 $LKM_1$ 与 $LKM_2$ ,他们分别属于 CPU 密集型与 I/O 密集型的模块,前者用以计算 $\pi$ 的值,后者用以读写文件。
测试结果如 图.11 所示。横坐标为实线指示了 $\pi$ 小数点后的位数,与文件操作数量相关的为点线。纵坐标指示了速度损失速率。
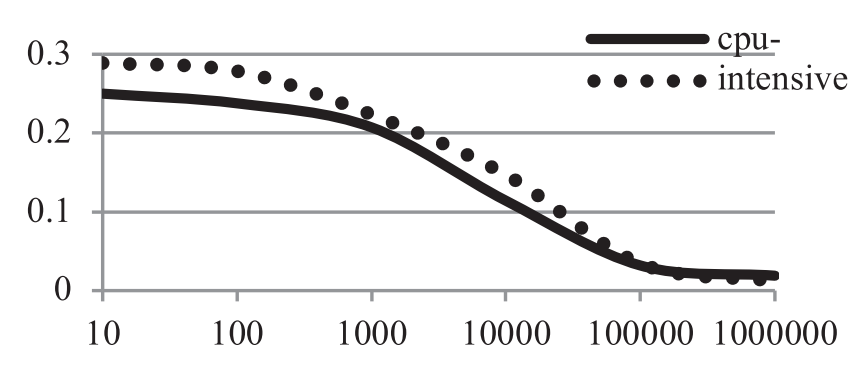
与此相反,当模块运行较长一段时间时,由 VTW 造成的性能损失比例更小。对于普通 LKMs 而言,VTW 仅在他们被加载以及状态被更新时干涉他们的执行。由 VTW 造成的 “guest” 的阻塞时间是比较固定的。当 LKM 的执行时间较短时,VTW 会阻塞 “guest” 模式更多比例的时间,由此性能损失系数会变得更大。
陷阱的数量与在模块间的控制流跳转的数量为影响 LKM 执行速度的关键因素。我们以一个运行时间大约 7.6s 的 $LKM_3$ 作为测试对象,并测量了陷阱数量在其执行速度上的影响。
我们重写了 $LKM_1$ 与 $LKM_2$ 使得控制流在其间跳转, 他们可以被用以测量跳转次数对 LKM 执行速度的影响。实验结果如 图.12 所示。
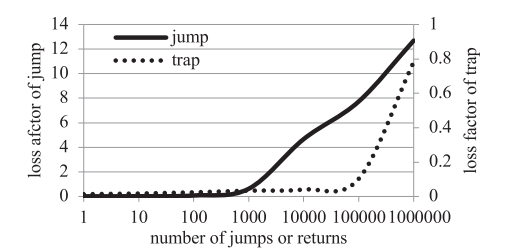
点线显示了当陷阱数量较少时 VTW 在 LKM 的执行速度上的影响是较小的。当陷阱数量超过 1000000 时,LKM 的执行将会减速到 80%。实线显示了当跳转数量超过 100 时,VTW 减速到了 8%。当跳转数量超过 1000 时, LKM 的执行速度将会急剧减小。
控制流跳转对 LKM 执行的影响比陷阱更大。一个完整的跳转与返回涉及到两个模式切换与四个代码执行权限,因此 VTW 在处理模块间跳转时会遇到更多的开销,
7.4 Comparison With Other Defence Schemes
在 表.6 中,我们将 VTW 的表现与七个已知 rootkit 防御方案对比。大部分其他的 rootkit 防护方案应用了虚拟机的内省技术,这与 VTW 主要基于事件追踪的方案是非常不同的。
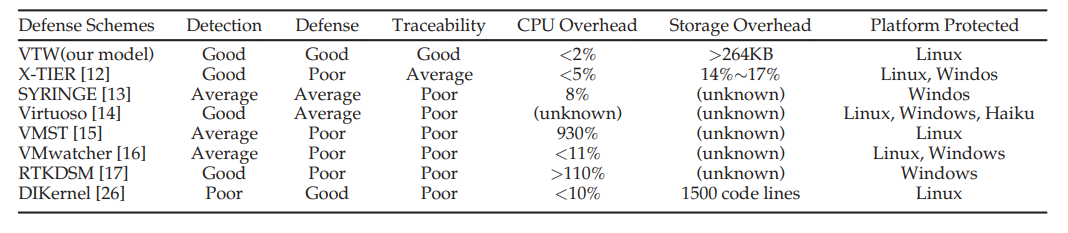
我们从四个表现领域对他们进行定性比较:$检测、防护、可追踪性、可移植性$。VTW 在这四个领域有着如前文所述的显著的优点。在未来的工作中需要更多的基准测试实验以揭示一些定量的结果。
我们的 VTW 仅被设计以支持 Intel 处理器及仅保护基于 Linux 的 x86 服务器。当前的 VTW 版本并不支持运行 Windows 或其他操作系统平台的服务器。然而,Virtuoso 方案已经报告了其在不同平台上的高可移植性。
根据解决恶意软件变种的能力,我们将检测、防护、可追踪性能力分为三个级别:好、一般、差。
对于 rootkit 检测,VTW、Xtier、Virtuoso、RTKDSM 都被评为好。对于防护与可追踪性,所有的方案都被评为一般或差,仅有 DIKernel 展示了一些防护能力。与 VTW 类似,所有报道的方案都运行在 x86 处理器,除了 DIKernel 在 arm-v7。
我们的实验揭示了一些在 CPU 上的测量结果与存储开销。如与 表.6 中剩余的方案对比所示,VTW 在实施所有的防护与过滤操作的系统开销上展现了显著的优势。特别的,我们想要指出使用 VMST 与 PTKDSM 方案的过度开销。
8 Concluding Remarks
本论文提出了一种新的虚拟化墙(virtual wall,VTW)方案以在 Linux 服务器上过滤内核 rootkit。总而言之,我们证明了我们的 VTW 防护方案在 rootkit 的检测、防护、可追踪性上有着较好的表现。VTW 比其他任何 rootkit 防护系统的内存与存储开销都要低得多。
所有在 guest 模式下损坏安全策略的操作都将导致操作系统陷入到 host 模式中,VTW 利用一种内存访问控制机制与一个事件注入机制来完成 rootkit 过滤过程。
未来追踪 LKMs 的执行路径与所有的内核攻击参与者,我们提出了一种基于 LKM 执行路径的追踪机制。我们的 VTW 实时保护了静态内核数据的完整性。对于动态内核对象,VTW 在追踪过程中检测内核数据的可用性,由此每个被破坏的 LKM 数据都可以被检测与恢复。
我们的 VTW 使用通用防护异常来防止更多的损害。当内核攻击的参与者涉及多个内核 rootkits 时,我们可以通过检查 LKM 的执行路径获得与攻击相关的执行实体。我们追踪在一次攻击中所有参与的内核 rootkits。VTW 为总的 CPU 时间增加了额外的 2% 。
消极的一面是,VTW 被限制于仅能保护 Linux 服务器。我们的 VTW 方案仅支持 Intel 处理器与 Linux 系统。VTW 并不能在 AMD、ARM 处理器或是运行 Windows 的服务器上运行。SYRINGE、VMST、DIKernel 防护方案亦是如此。
VTW 对 BIOS 或用户级的 rootkit 攻击的防护有限。对于可能损害内核完整性的 rootkits,他们可能使用 $/dev/kmem$ 或 $/dev/mem$ 或其他方案,这可以从本论文的 VTW 中扩展。由于页数限制,我们将在未来的工作中使用这些扩展。