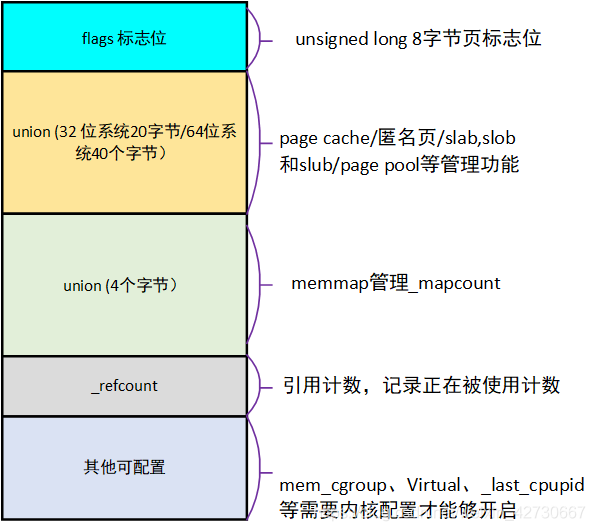
/* First tail page only */ unsignedchar compound_dtor; unsignedchar compound_order; atomic_t compound_mapcount; unsignedint compound_nr; /* 1 << compound_order */ }; struct {/* Second tail page of compound page */ unsignedlong _compound_pad_1; /* compound_head */ atomic_t hpage_pinned_refcount; /* For both global and memcg */ structlist_headdeferred_list; }; struct {/* 页表页面 */ unsignedlong _pt_pad_1; /* compound_head */ pgtable_t pmd_huge_pte; /* protected by page->ptl */ unsignedlong _pt_pad_2; /* mapping */ union { structmm_struct *pt_mm;/* 用于 x86 的全局目录表(pgd) */ atomic_t pt_frag_refcount; /* 用于 powerpc 架构 */ }; #if ALLOC_SPLIT_PTLOCKS spinlock_t *ptl; #else spinlock_t ptl; #endif }; struct {/* ZONE_DEVICE pages */ /** @pgmap: Points to the hosting device page map. */ structdev_pagemap *pgmap; void *zone_device_data; /* * ZONE_DEVICE private pages are counted as being * mapped so the next 3 words hold the mapping, index, * and private fields from the source anonymous or * page cache page while the page is migrated to device * private memory. * ZONE_DEVICE MEMORY_DEVICE_FS_DAX pages also * use the mapping, index, and private fields when * pmem backed DAX files are mapped. */ };
enumpageflags { PG_locked, /* Page is locked. Don't touch. */ PG_referenced, PG_uptodate, PG_dirty, PG_lru, PG_active, PG_workingset, PG_waiters, /* Page has waiters, check its waitqueue. Must be bit #7 and in the same byte as "PG_locked" */ PG_error, PG_slab, PG_owner_priv_1, /* Owner use. If pagecache, fs may use*/ PG_arch_1, PG_reserved, PG_private, /* If pagecache, has fs-private data */ PG_private_2, /* If pagecache, has fs aux data */ PG_writeback, /* Page is under writeback */ PG_head, /* A head page */ PG_mappedtodisk, /* Has blocks allocated on-disk */ PG_reclaim, /* To be reclaimed asap */ PG_swapbacked, /* Page is backed by RAM/swap */ PG_unevictable, /* Page is "unevictable" */ #ifdef CONFIG_MMU PG_mlocked, /* Page is vma mlocked */ #endif #ifdef CONFIG_ARCH_USES_PG_UNCACHED PG_uncached, /* Page has been mapped as uncached */ #endif #ifdef CONFIG_MEMORY_FAILURE PG_hwpoison, /* hardware poisoned page. Don't touch */ #endif #if defined(CONFIG_IDLE_PAGE_TRACKING) && defined(CONFIG_64BIT) PG_young, PG_idle, #endif #ifdef CONFIG_64BIT PG_arch_2, #endif __NR_PAGEFLAGS,
/* Two page bits are conscripted by FS-Cache to maintain local caching * state. These bits are set on pages belonging to the netfs's inodes * when those inodes are being locally cached. */ PG_fscache = PG_private_2, /* page backed by cache */
/* XEN */ /* Pinned in Xen as a read-only pagetable page. */ PG_pinned = PG_owner_priv_1, /* Pinned as part of domain save (see xen_mm_pin_all()). */ PG_savepinned = PG_dirty, /* Has a grant mapping of another (foreign) domain's page. */ PG_foreign = PG_owner_priv_1, /* Remapped by swiotlb-xen. */ PG_xen_remapped = PG_owner_priv_1,
/* SLOB */ PG_slob_free = PG_private,
/* Compound pages. Stored in first tail page's flags */ PG_double_map = PG_workingset,
/* * page->flags layout: * * There are five possibilities for how page->flags get laid out. The first * pair is for the normal case without sparsemem. The second pair is for * sparsemem when there is plenty of space for node and section information. * The last is when there is insufficient space in page->flags and a separate * lookup is necessary. * * No sparsemem or sparsemem vmemmap: | NODE | ZONE | ... | FLAGS | * " plus space for last_cpupid: | NODE | ZONE | LAST_CPUPID ... | FLAGS | * classic sparse with space for node:| SECTION | NODE | ZONE | ... | FLAGS | * " plus space for last_cpupid: | SECTION | NODE | ZONE | LAST_CPUPID ... | FLAGS | * classic sparse no space for node: | SECTION | ZONE | ... | FLAGS | */
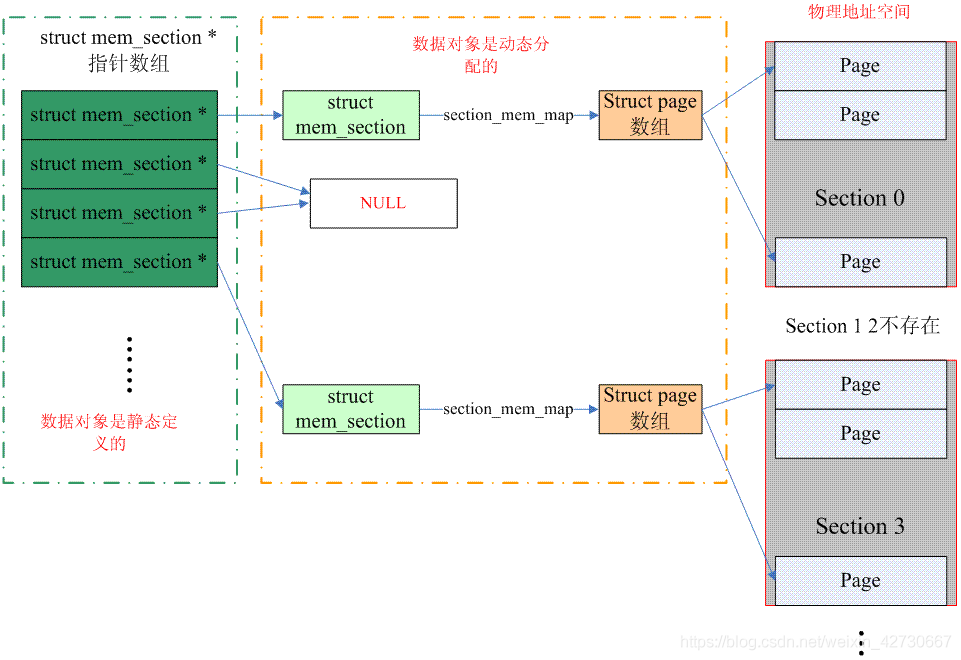
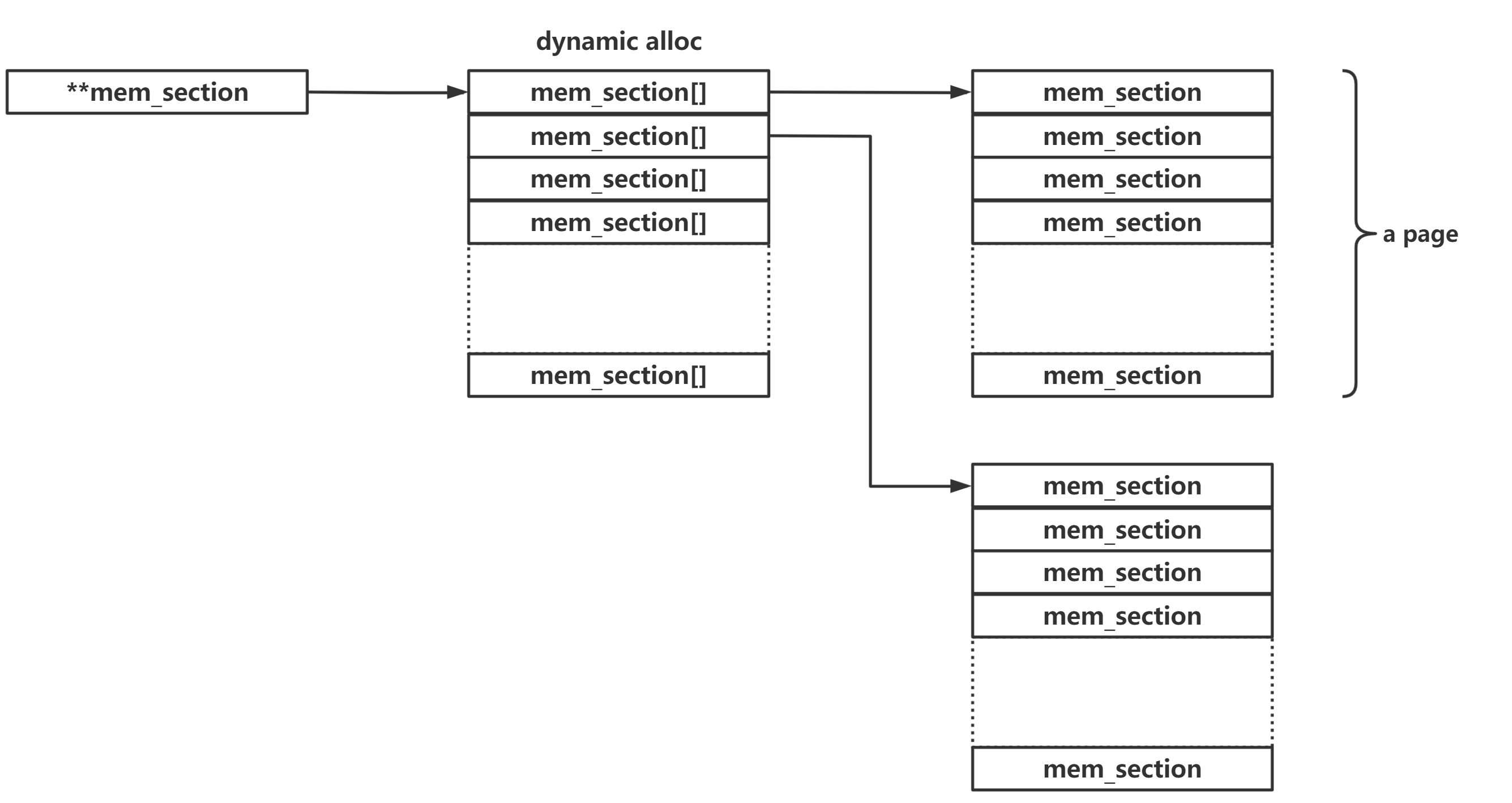
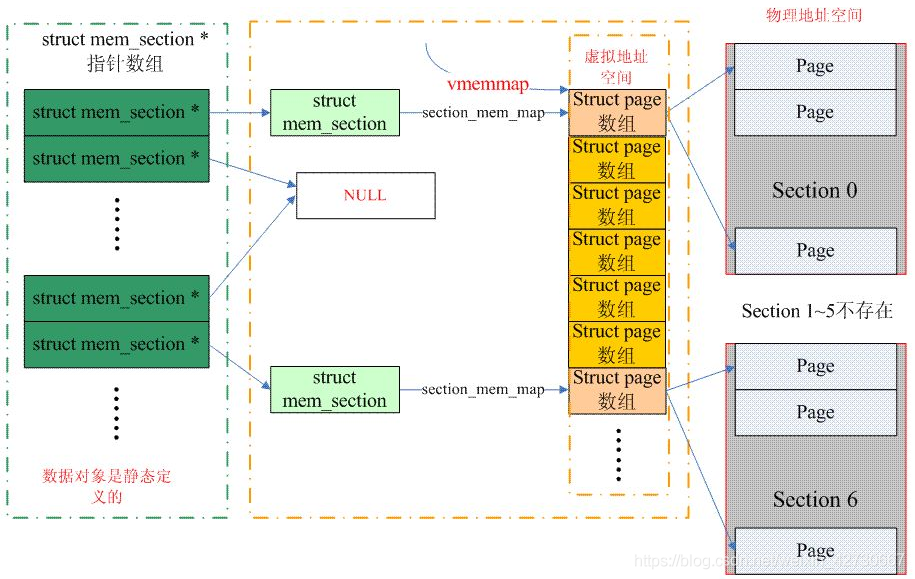
非 sparse 内存模式 / sparse vmemmap 内存模式
如下图所示,低位用作该 page 的 flag,高位分别标识其归属的 zone, node id(非 NUMA 系统中为0),中间剩余的位保留
/* * For pages that are never mapped to userspace (and aren't PageSlab), * page_type may be used. Because it is initialised to -1, we invert the * sense of the bit, so __SetPageFoo *clears* the bit used for PageFoo, and * __ClearPageFoo *sets* the bit used for PageFoo. We reserve a few high and * low bits so that an underflow or overflow of page_mapcount() won't be * mistaken for a page type value. */
/* * 我们不知道我们将要分配的内存是否是可释放的 或/且 最终会被释放, * 因此为了避免将整个的几个 GB 的 RAM浪费掉, * 我们必须要保留一些 lower zone memory * (否则我们将有在 lower zones 上耗尽所有内存(OOM)的风险, * 尽管此时在 higher zones 仍有大量的 RAM). * 若 sysctl_lowmem_reserve_ratio 系统控制项改变, * 这个数组有可能在运行时被改变 */ long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA int node; #endif structpglist_data *zone_pgdat; structper_cpu_pageset __percpu *pageset; /* * the high and batch values are copied to individual pagesets for * faster access */ int pageset_high; int pageset_batch;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA /* pfn where compaction free scanner should start */ unsignedlong compact_cached_free_pfn; /* pfn where compaction migration scanner should start */ unsignedlong compact_cached_migrate_pfn[ASYNC_AND_SYNC]; unsignedlong compact_init_migrate_pfn; unsignedlong compact_init_free_pfn; #endif
#ifdef CONFIG_COMPACTION /* * On compaction failure, 1<<compact_defer_shift compactions * are skipped before trying again. The number attempted since * last failure is tracked with compact_considered. * compact_order_failed is the minimum compaction failed order. */ unsignedint compact_considered; unsignedint compact_defer_shift; int compact_order_failed; #endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA /* Set to true when the PG_migrate_skip bits should be cleared */ bool compact_blockskip_flush; #endif
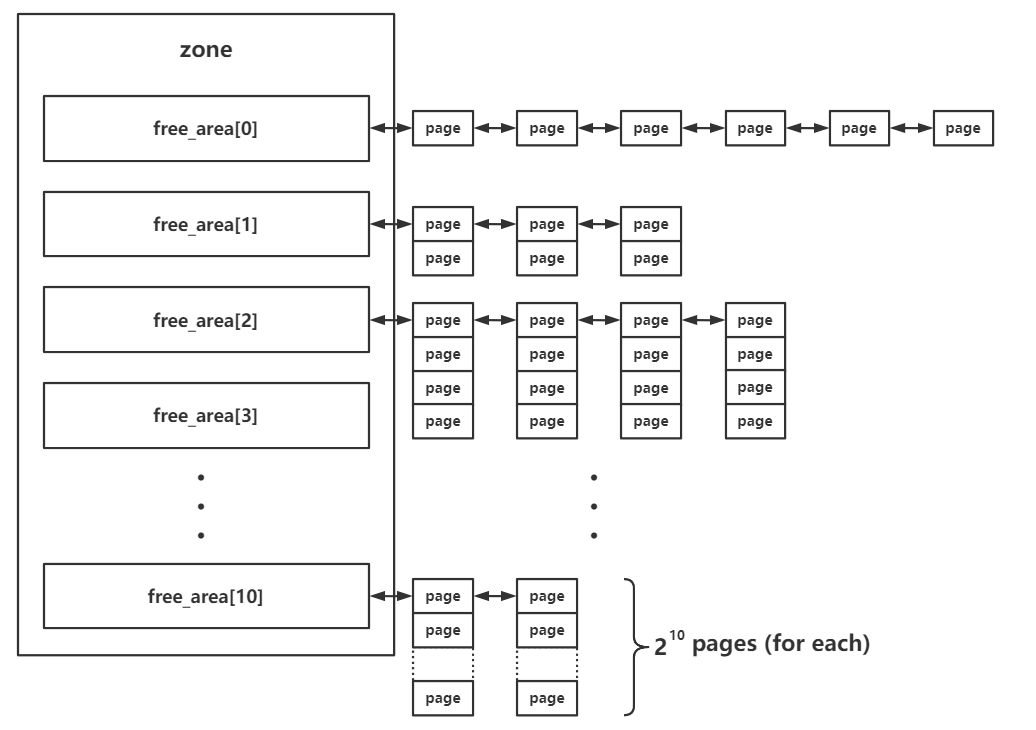
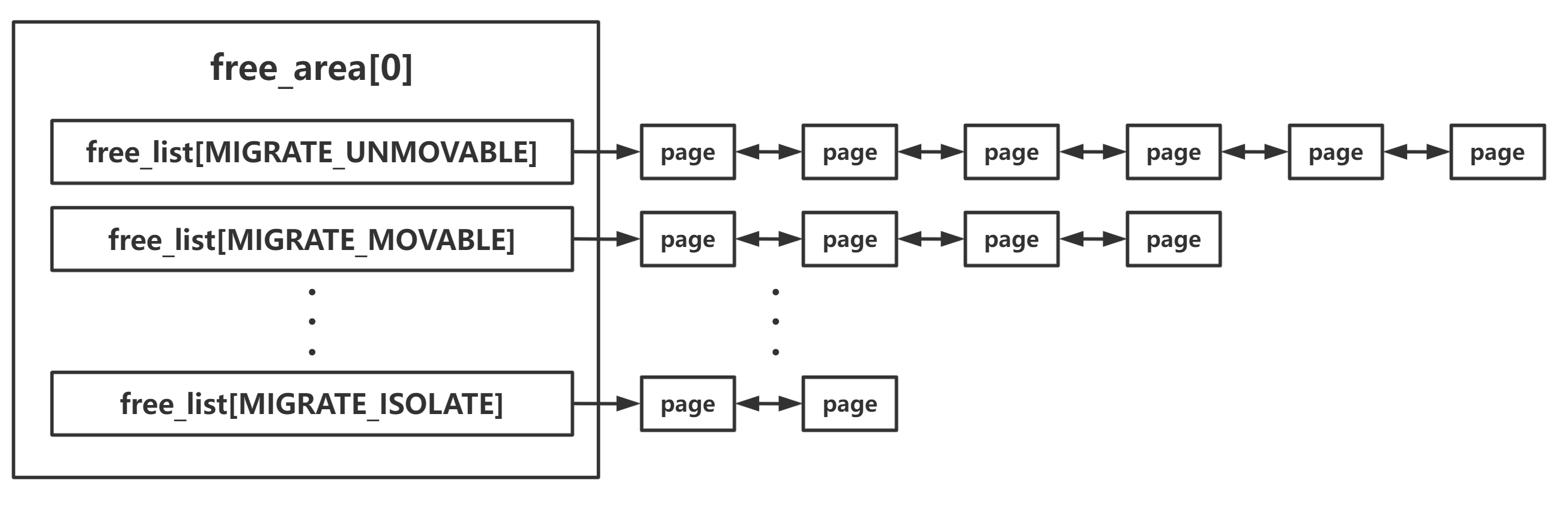
enummigratetype { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RECLAIMABLE, MIGRATE_PCPTYPES, /* the number of types on the pcp lists */ MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES, #ifdef CONFIG_CMA /* * MIGRATE_CMA migration type is designed to mimic the way * ZONE_MOVABLE works. Only movable pages can be allocated * from MIGRATE_CMA pageblocks and page allocator never * implicitly change migration type of MIGRATE_CMA pageblock. * * The way to use it is to change migratetype of a range of * pageblocks to MIGRATE_CMA which can be done by * __free_pageblock_cma() function. What is important though * is that a range of pageblocks must be aligned to * MAX_ORDER_NR_PAGES should biggest page be bigger then * a single pageblock. */ MIGRATE_CMA, #endif #ifdef CONFIG_MEMORY_ISOLATION MIGRATE_ISOLATE, /* can't allocate from here */ #endif MIGRATE_TYPES };
在进行内存分配时,若当前的 zone 没有足够的内存了,则会向下一个 zone 索要内存,那么这就存在一个问题:来自 higher zones 的内存分配请求可能耗尽 lower zones 的内存,但这样分配的内存未必是可释放的(freeable),亦或者/且最终不一定会被释放,这有可能导致 lower zones 的内存提前耗尽,而 higher zones 却仍保留有大量的内存
为了避免这样的一种情况的发生,lowmem_reserve 字段用以声明为该 zone 保留的内存,这一块内存别的 zone 是不能动的
node:NUMA 中标识所属 node
这个字段只在 NUMA 系统中被启用,用以标识该 zone 所属的 node
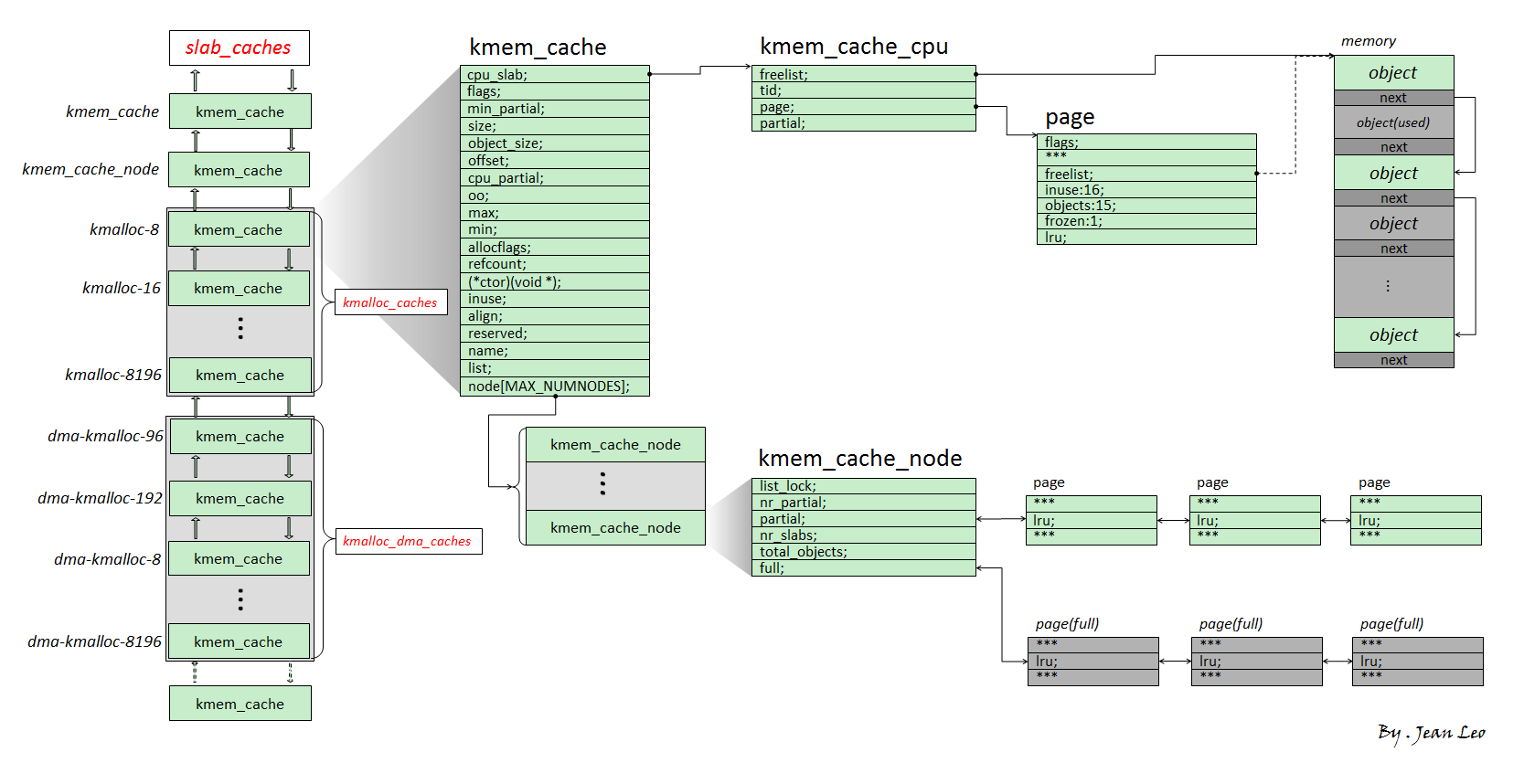
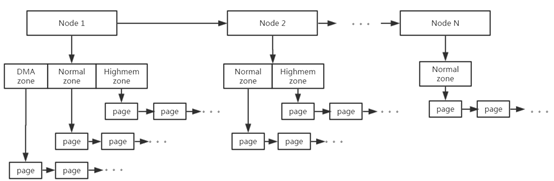
可以参考下面的图
图还是偷的,侵删
zone_pgdat:zone 所属的 pglist_data 节点
该字段用以标识该 zone 所属的 pglist_data 节点
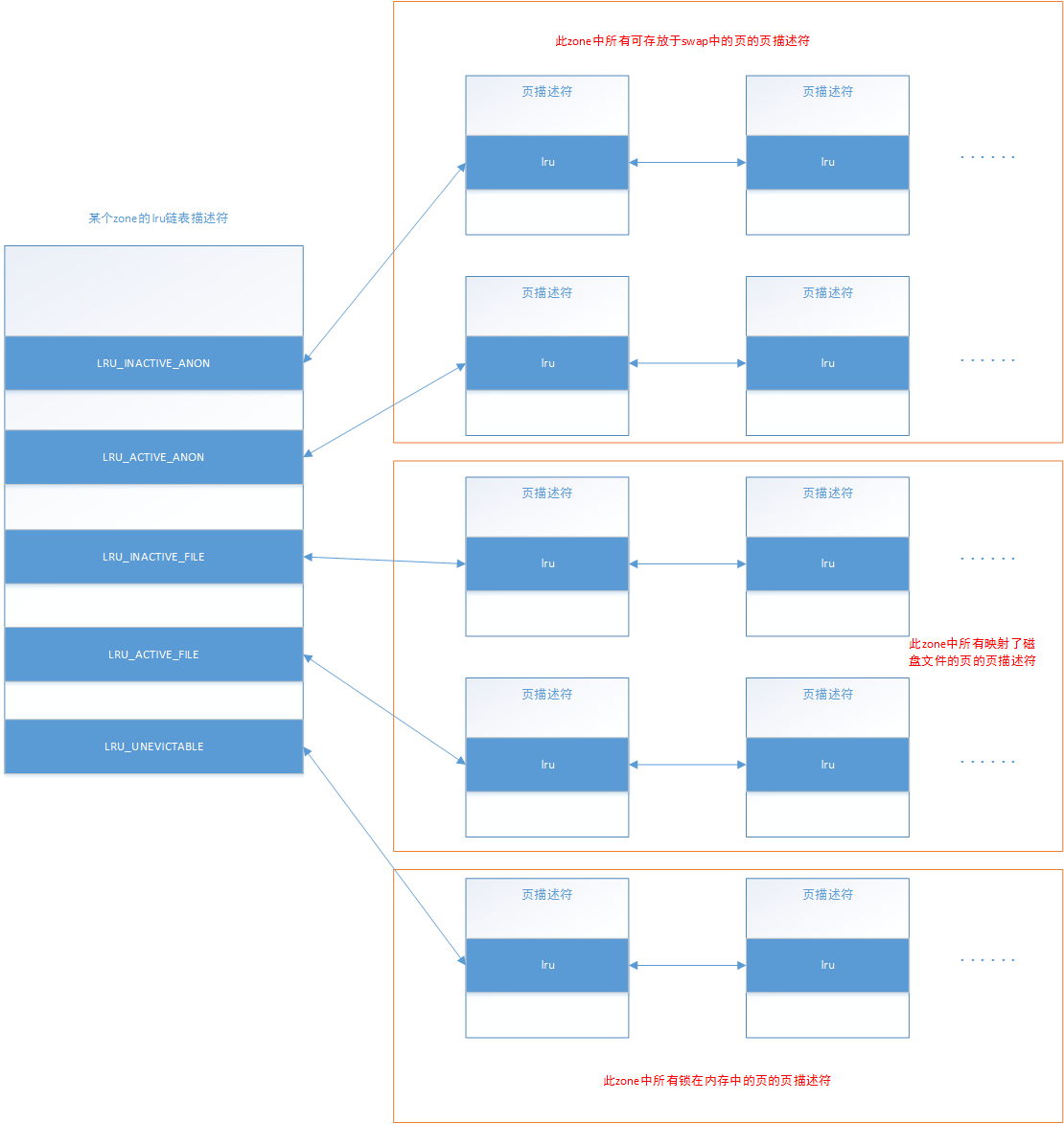
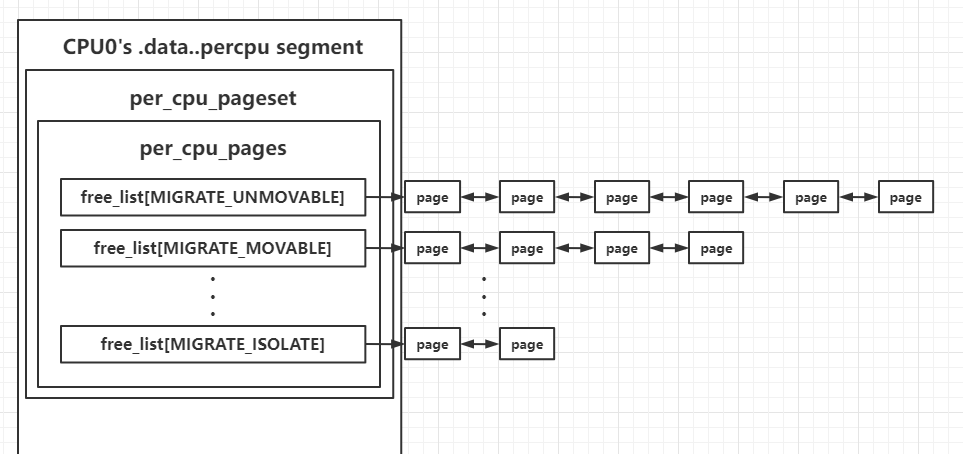
**pageset**:zone 为每个 CPU 划分一个独立的”页面仓库“
众所周知伴随着多 CPU 的引入,条件竞争就是一个不可忽视的问题,当多个 CPU 需要对一个 zone 进行操作时,频繁的加锁/解锁操作则毫无疑问会造成大量的开销,因此 zone 引入了 per_cpu_pageset 结构体成员,即为每一个 CPU 都准备一个单独的页面仓库,因此其实现方式是实现为一个 percpu 变量
在一开始时 buddy system 会将页面放置到各个 CPU 自己独立的页面仓库中,需要进行分配时 CPU 优先从自己的页面仓库中分配
该数组用来进行数据统计,按照枚举类型 zone_stat_item 分为多个数组,以统计不同类型的数据(比如说 NR_FREE_PAGES 表示 zone 中的空闲页面1数量):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
enumzone_stat_item { /* First 128 byte cacheline (assuming 64 bit words) */ NR_FREE_PAGES, NR_ZONE_LRU_BASE, /* Used only for compaction and reclaim retry */ NR_ZONE_INACTIVE_ANON = NR_ZONE_LRU_BASE, NR_ZONE_ACTIVE_ANON, NR_ZONE_INACTIVE_FILE, NR_ZONE_ACTIVE_FILE, NR_ZONE_UNEVICTABLE, NR_ZONE_WRITE_PENDING, /* Count of dirty, writeback and unstable pages */ NR_MLOCK, /* mlock()ed pages found and moved off LRU */ /* Second 128 byte cacheline */ NR_BOUNCE, #if IS_ENABLED(CONFIG_ZSMALLOC) NR_ZSPAGES, /* allocated in zsmalloc */ #endif NR_FREE_CMA_PAGES, NR_VM_ZONE_STAT_ITEMS };
flags:标志位
该 zone 的标志位,用以标识其所处的状态
II.zone 的分类
在 Linux kernel 当中,我们根据内存区段的不同用途,将其划分为不同的 zone,在 /include/linux/mmzone.h 中有着相应的枚举定义,如下:
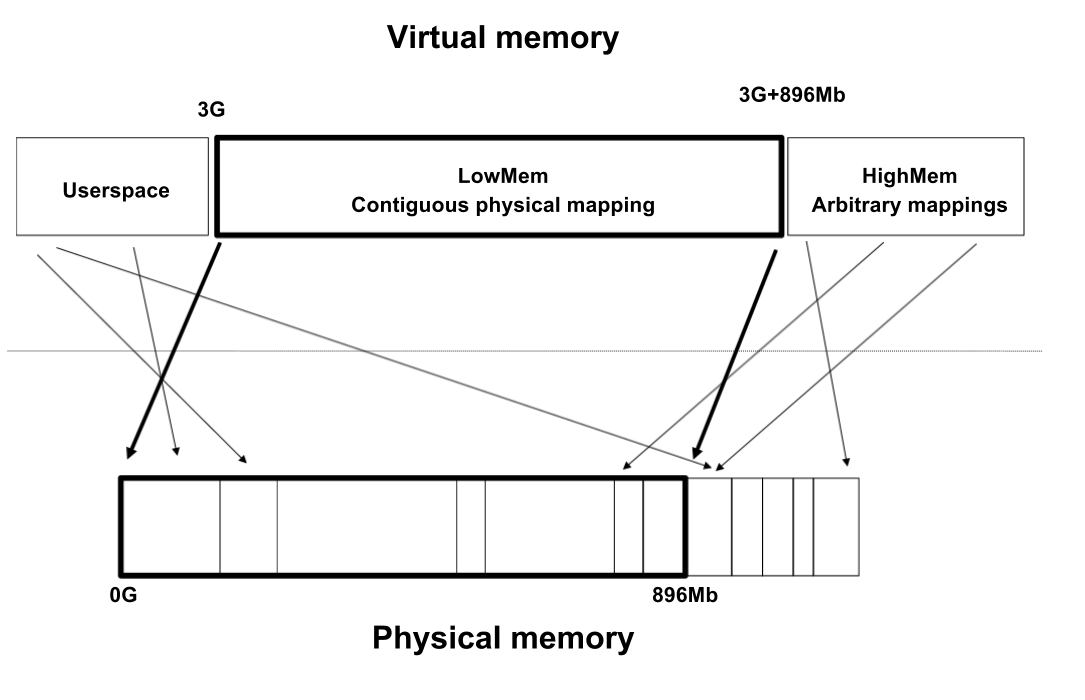
enumzone_type { /* * ZONE_DMA and ZONE_DMA32 are used when there are peripherals not able * to DMA to all of the addressable memory (ZONE_NORMAL). * On architectures where this area covers the whole 32 bit address * space ZONE_DMA32 is used. ZONE_DMA is left for the ones with smaller * DMA addressing constraints. This distinction is important as a 32bit * DMA mask is assumed when ZONE_DMA32 is defined. Some 64-bit * platforms may need both zones as they support peripherals with * different DMA addressing limitations. */ #ifdef CONFIG_ZONE_DMA ZONE_DMA, #endif #ifdef CONFIG_ZONE_DMA32 ZONE_DMA32, #endif /* * Normal addressable memory is in ZONE_NORMAL. DMA operations can be * performed on pages in ZONE_NORMAL if the DMA devices support * transfers to all addressable memory. */ ZONE_NORMAL, #ifdef CONFIG_HIGHMEM /* * A memory area that is only addressable by the kernel through * mapping portions into its own address space. This is for example * used by i386 to allow the kernel to address the memory beyond * 900MB. The kernel will set up special mappings (page * table entries on i386) for each page that the kernel needs to * access. */ ZONE_HIGHMEM, #endif /* * ZONE_MOVABLE is similar to ZONE_NORMAL, except that it contains * movable pages with few exceptional cases described below. Main use * cases for ZONE_MOVABLE are to make memory offlining/unplug more * likely to succeed, and to locally limit unmovable allocations - e.g., * to increase the number of THP/huge pages. Notable special cases are: * * 1. Pinned pages: (long-term) pinning of movable pages might * essentially turn such pages unmovable. Memory offlining might * retry a long time. * 2. memblock allocations: kernelcore/movablecore setups might create * situations where ZONE_MOVABLE contains unmovable allocations * after boot. Memory offlining and allocations fail early. * 3. Memory holes: kernelcore/movablecore setups might create very rare * situations where ZONE_MOVABLE contains memory holes after boot, * for example, if we have sections that are only partially * populated. Memory offlining and allocations fail early. * 4. PG_hwpoison pages: while poisoned pages can be skipped during * memory offlining, such pages cannot be allocated. * 5. Unmovable PG_offline pages: in paravirtualized environments, * hotplugged memory blocks might only partially be managed by the * buddy (e.g., via XEN-balloon, Hyper-V balloon, virtio-mem). The * parts not manged by the buddy are unmovable PG_offline pages. In * some cases (virtio-mem), such pages can be skipped during * memory offlining, however, cannot be moved/allocated. These * techniques might use alloc_contig_range() to hide previously * exposed pages from the buddy again (e.g., to implement some sort * of memory unplug in virtio-mem). * * In general, no unmovable allocations that degrade memory offlining * should end up in ZONE_MOVABLE. Allocators (like alloc_contig_range()) * have to expect that migrating pages in ZONE_MOVABLE can fail (even * if has_unmovable_pages() states that there are no unmovable pages, * there can be false negatives). */ ZONE_MOVABLE, #ifdef CONFIG_ZONE_DEVICE ZONE_DEVICE, #endif __MAX_NR_ZONES
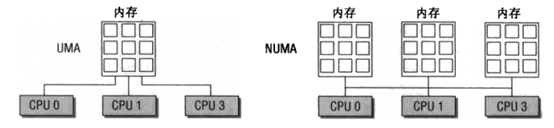
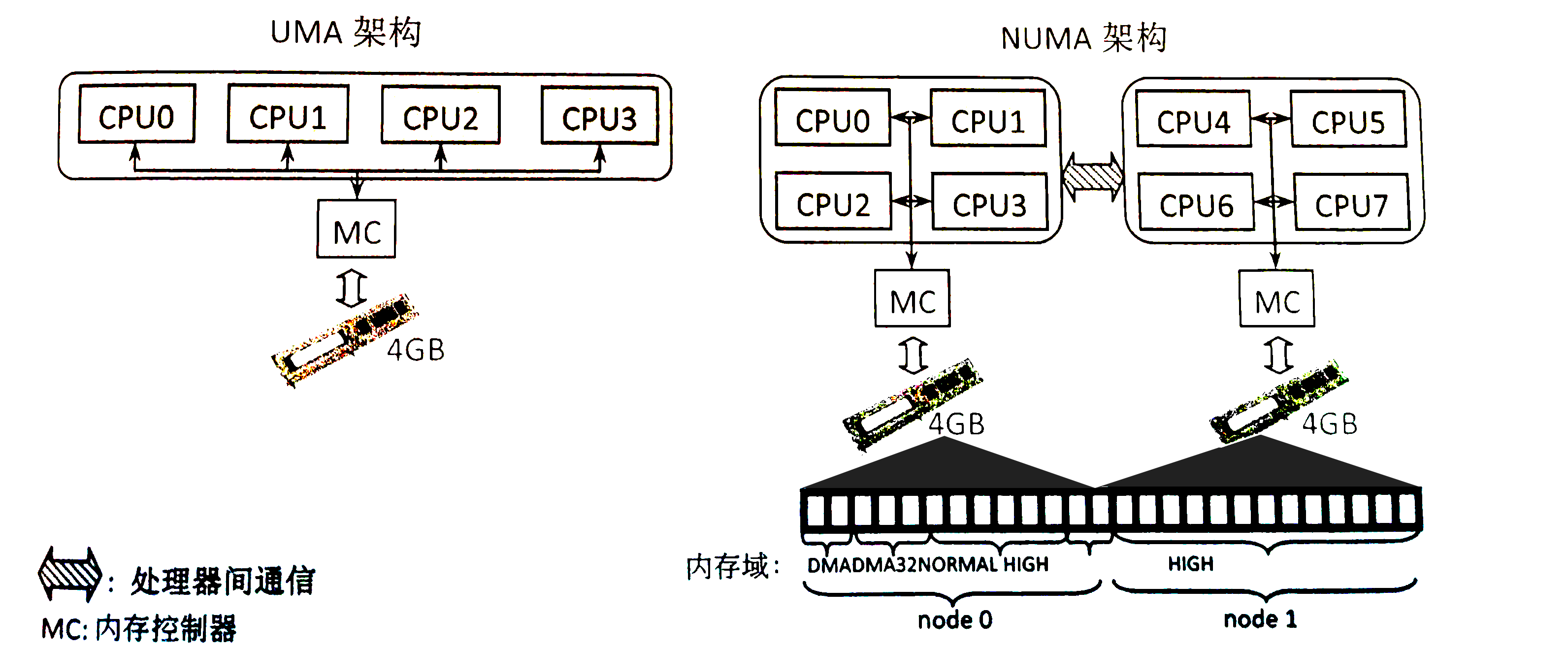
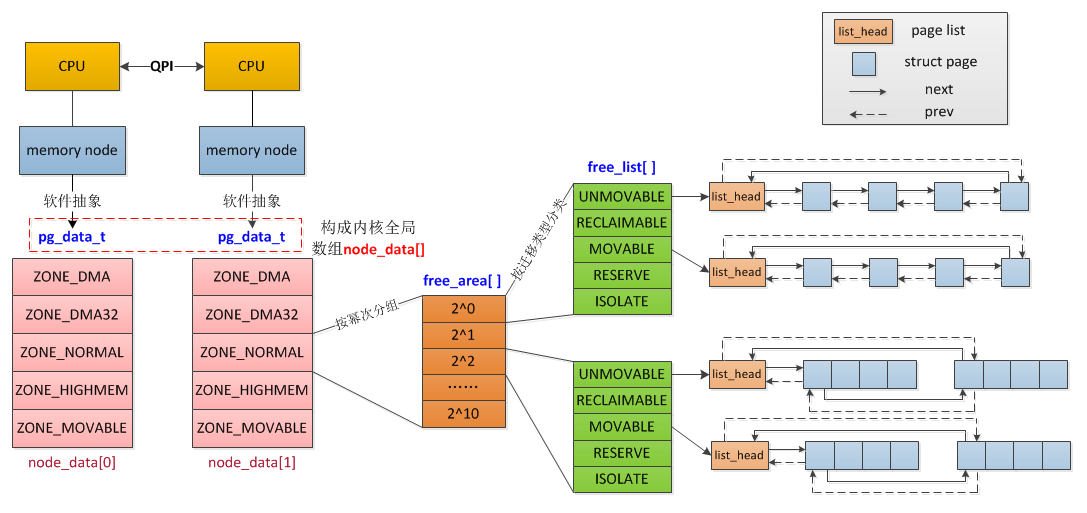
zone 再向上一层便是节点——Linux 将_内存控制器(memory controller)_作为节点划分的依据,对于 UMA 架构而言只有一个节点,而对于 NUMA 架构而言通常有多个节点,对于同一个内存控制器下的 CPU 而言其对应的节点称之为_本地内存_,不同处理器之间通过总线进行进一步的连接。如下图所示,一个MC对应一个节点: