【FUZZ.0x01】syzkaller - I:基本使用方法
本文最后更新于:2025年6月10日 凌晨
尝试遍历所有的世界线
0x00.一切开始之前
syzkaller 是由 Google 开发的一个十分强大的针对内核的 fuzzer,自其面世以来已经帮助全世界的内核安全研究员发现了数量惊人的内核漏洞
本篇文章中笔者将简述 syzkaller 的使用方法
0x01.环境配置
这里参照官方文档进行配置: https://github.com/google/syzkaller
注意:本文可能已经过时,请参照 Google 最新的官方文档进行配置!
笔者本地环境:Ubuntu 21.04
在安装之前请确保你的电脑具有足够的运行内存与存储空间!(笔者的2G阿里云学生机就被搞炸了
要使用 syzkaller 进行漏洞挖掘,我们需要:
Go compiler and syzkaller itselfC compiler with coverage supportLinux kernel with coverage additionsVirtual machine or a physical device
安装依赖
1 | |
配置 golang 环境
首先配置 golang 环境,可以参照官方文档:
1 | |
在 /etc/profile 中写入如下配置,重启,这里需要注意的是 YourGoPath应当替换为你实际存放 go 的路径,在上一步的终端中输入 pwd 后将其值替换到下方
1 | |
编译 syzkaller
直接从 GitHub 拉取即可
1 | |
编译目标内核
从镜像站随便拉一个版本的源码过来就行,笔者这里拉了一个 5.11 版本的内核
1 | |
解压
1 | |
然后执行下面这两条指令
1 | |
对于老版本内核,应当为:
1 | |
接下来编辑 .config 文件,在其末尾添加如下:
注:此为基础配置,更多可选配置可以参见 https://github.com/google/syzkaller/blob/master/docs/linux/kernel_configs.md
1 | |
接下来开始编译内核,这个时候可以简单开一局你喜欢的游戏慢慢等待(笑)
1 | |
如果编译的时候出现了这个错误,则说明内核版本与当前编译器可能不兼容:
cc1: error: ‘-fcf-protection’ is not compatible with this target可以尝试 切换到老版本的 gcc8 重新进行编译
2
3$ sudo apt-get install gcc-8 gcc-8-multilib
$ sudo apt-get install g++-8 g++-8-multilib
$ sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-8 1
出现下面这行就标志着编译完成
1 | |
编译出来的 bzImage 在 arch/x86/boot/bzImage,vmlinux 则就在源码根目录下,这两个文件前者是压缩后的内核后者是原始内核文件
配置 ext4 硬盘镜像文件
这里我们使用 debootstrap 来创建ext4硬盘镜像
1 | |
wget 的这一步需要翻墙(
raw.githubusercontent.com在国内似乎是被墙了,总之笔者记忆里从没成功在不翻墙的情况下成功上去过),若嫌麻烦可以直接 copy 笔者已经下好的
这一步不知道是因为网络原因还是别的原因总而言之非常的慢(比上面编译内核耗时还长),完成之后如下:
1 | |
我们可以在文件目录下找到一个名为 stretch.img 的文件,这个文件就是构建好的磁盘镜像文件
安装 qemu
这一步还是比较简单的,需要注意的是如果你和笔者一样在 VMware 上使用 Linux 则应当在设置中把 虚拟化 Intel VT-x/EPT 或 AMD-V/RVI(V) 打开
1 | |
完成这一切之后看看内核是否能够被成功启动,启动脚本如下(别忘了替换内核镜像与硬盘镜像的路径):
1 | |
默认 root 账户无密码,成功登入
前面在配置硬盘镜像文件时还给我们提供了 ssh key,我们也可以用 ssh 来直接连接至虚拟机:
1 | |
至此,需要的环境就都配置完成了
0x02.开始使用 syzkaller
PRE.工作原理
对于 syzkaller 的架构,官方给出了这样的一张 Overview
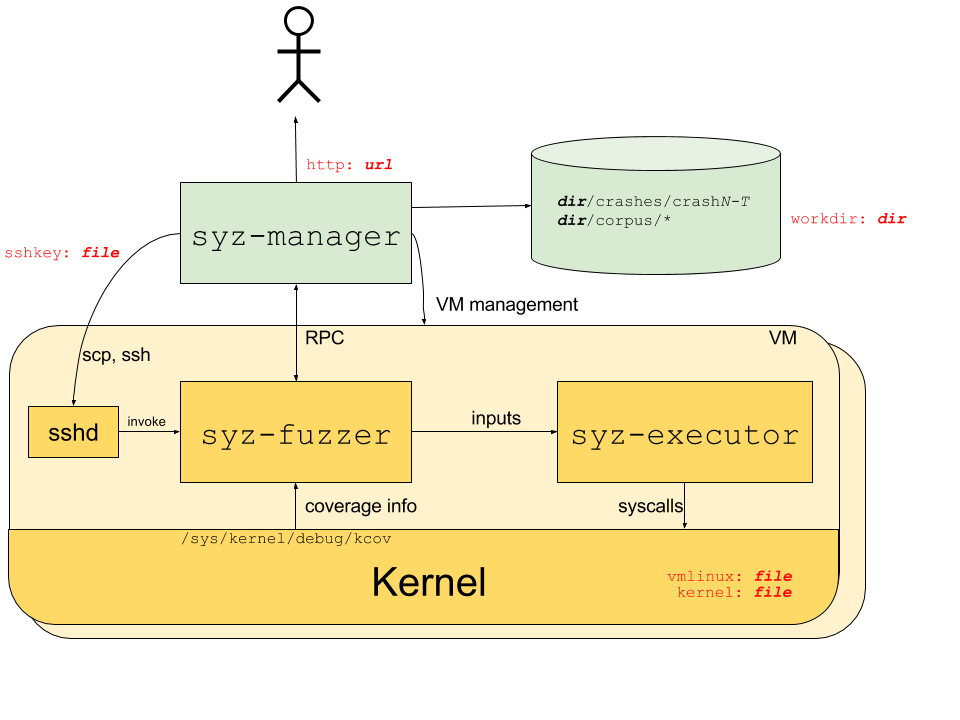
syz-manager:syzkaller 的控制中枢,其会启动多个 VM 实例(如图所示的一个黄色卡片就是一个实例)并进行监视,同时通过 RPC 来启动syz-fuzzersyz-fuzzer:负责引导整个 fuzz 的过程:- 生成 input
- 启动
syz-executor进程进行 fuzz - 从被 fuzz 的 kernel 的
/sys/kernel/debug/kcov获得覆盖(coverage)的相关信息 - 通过 RPC 将新的覆盖回送到
syz-manager
syz-executor:负责执行单个输入——从syz-fuzzer处接受 input 并执行,最后回送结果
配置文件(for test)
我们需要为 syzkaller 编写额外的配置文件,一个简单的例子如下,这里需要注意替换为你自己的路径,包括 workdir 文件夹你应当手动 mkdir 一个:
config.cfg
1 | |
启动 syzkaller
在 syzkaller 目录下输入如下命令启动 syzkaller:
1 | |
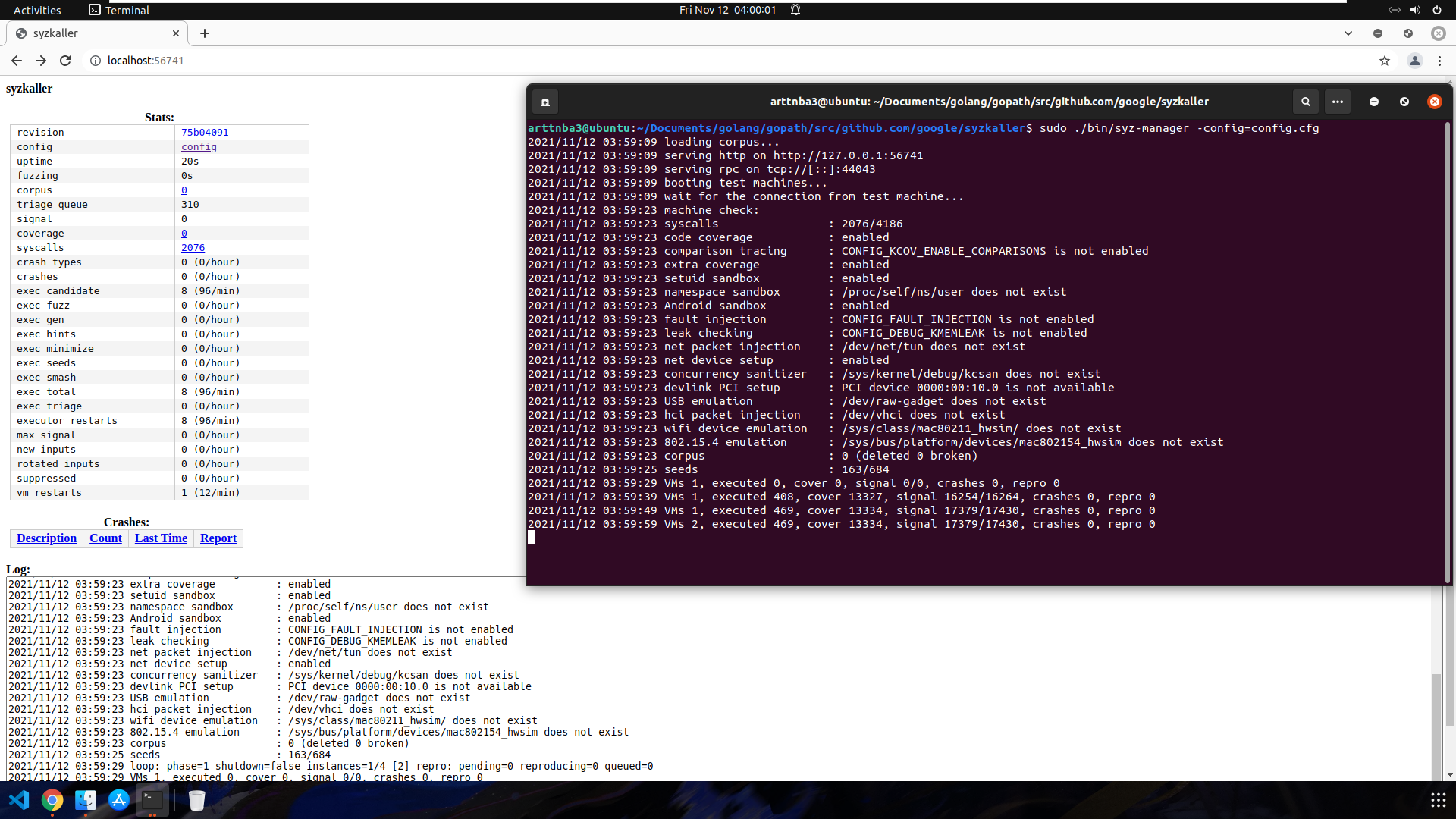
成功启动后我们可以通过访问 localhost:56741 来获取 syzkaller 的状态,效果如下图所示:
*可能会遇到的问题
无法启动 vm instance
有可能会遇到无法启动 vm instance 的问题,报错形式大致如下:
1 | |
按照官方给出的解决办法是在 qemu 的启动参数中去掉 -cpu host,migratable=off,我们需要在配置文件的 vm 项中添加 qemu-args项,值为 -enable-kvm,如下:
1 | |
网络设备问题
在 syzkaller 挖掘过程中可能出现如下报错信息:
1 | |
可能有两种原因:
第一种原因是没有给内核传递参数导致的,我们需要在配置文件的 vm 项中添加 qemu-args项,值为 -append \"net.ifnames=0\",如下:
1 | |
第二种原因是网络配置错误,我们需要在虚拟机磁盘镜像文件 stretch.img 的 /etc/network/interfaces 当中添加如下内容,这里注意将 enp0s4 替换为你在虚拟机中通过 ip addr 看到的物理网卡名称:
1 | |
连接丢失
在syzkaller 运行过程中你可能会遇到这样的报错:
1 | |
点开网页端的 log 一看很容易发现是 libc 版本对不上导致 syz-executor 起不来:
1 | |
如果你本地的发行版比较 cutting edge 的话确实容易出现这样的问题(因为 syzkaller 的镜像默认用 Debian),比较好的解决方案是确保本地环境和远程用的同一个环境(例如都用 Debian),或者手搓一个其他发行版的镜像
此外还有一个办法就是修改 Makefile 让 executor 静态编译
crash 分析
笔者本来想写一个有漏洞点内核模块来人为制造 crash,不过现在刚开挖没几分钟就出了一个 crash,由于用的是 5.11 版本的内核,已经不算太新了,笔者认为应该是挖到了已经被人发现的漏洞,通过 Google 笔者也找到了一个基本上是一样的 crash,不过我们还是来简单分析一下

在 Description 项中说明了 crash 的简要信息,点开分为两项:log 和 report

log 中给出的是 fuzz 的流程,包括运行的系统调用、输入参数等一系列信息,因为是自动生成的所以一般不会特别好看

report 中给出的则是 kernel 相关信息,例如调用栈回溯等
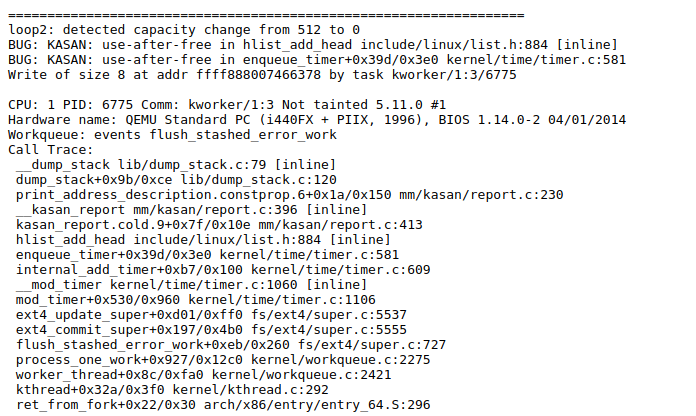
比较可惜的是这个 crash 没法重现,在一个 crash 刚刚生成时 syzkaller 会尝试进行重现,此时 report 的状态会显示为 reproducing,若成功了则会显示对应的结果,品相比较好的一种 report 就是 has C repo:有产生该 crash 的 C 代码

0x03.使用 syzlang 编写描述文件进行 fuzz
直接就这样挂着肯定不能直接就把洞挖出来虽然笔者前面没挂一会就出了一个crash,因此接下来我们需要人工配置系统调用模板,以有针对性地进行漏洞挖掘
syzkaller 使用它自己的声明式语言(Syscall Description Language,aka syzlang(读作 [siːzˈlæŋg],笔者以前一直读作 [saiːzˈlæŋg]…))来描述系统调用模板,在安装目录下的 docs/syscall_descriptions.md 与 docs/syscall_descriptions_syntax.md 中有着相关的说明,在笔者看来是类似 C 的一门描述语言
我们需要使用 syzlang 来编写特定的系统调用描述文件(也叫规则文件,后文中这两个词指的是同一个东西),syzkaller 会根据我们的描述文件有针对性地进行 fuzz
笔者看着也是比较头大的…还是慢慢来吧…
以下主要是翻译谷歌官方的文档(
谁叫国内没有中文文档呢),外加一些笔者自己本人的理解以及补充说明
syzlang 语法
syzlang 的语法结构如下,看完你也能快速上手!:
1 | |
这个时候你需要把自己当作一个 scanner + parser(大雾
正则表达式相信大家应该都学过,哪怕没学过编译原理课上你总会学到的,那么按照正则来看的话其实这个语法结构并不难解析(
以下是对其中的一些符号说明,不是 syzlang 实际语法内容:
- 双引号
""表示这个符号内的东西表示要按其原样进行匹配,丢弃双引号 - 或符号
|表示值可以取左边也可以取右边 - 等于号
=表示左边的表达式应当为右边的形式 - 中括号
[]表示一个可选表达式,取其内的值并丢弃中括号 - 星号
*表示闭包,即 0 次或多次的自我连接什么?你还没学过离散数学
这是谷歌官方给出的一个例子:
syzkalleruses declarative description of syscall interfaces to manipulate programs (sequences of syscalls). Below you can see (hopefully self-explanatory) excerpt from the descriptions:
2
3
4open(file filename, flags flags[open_flags], mode flags[open_mode]) fd
read(fd fd, buf buffer[out], count len[buf])
close(fd fd)
open_mode = S_IRUSR, S_IWUSR, S_IXUSR, S_IRGRP, S_IWGRP, S_IXGRP, S_IROTH, S_IWOTH, S_IXOTH
斯密🦄赛,👴没法做到 self-explanatory
O.注释与文件包含
syzlang 中的注释与 shell 脚本注释形式相同,为以 # 开头的单行注释
这是一个🌰:
1 | |
在 syzlang 中,我们可以额外引入内核源码文件作为参数、系统调用…等等一系列的补充,形式与 C 语言的 include 语句大致相同,不过**没有了开头的”#”**(因为 # 开头是注释)
这是一个🌰:
1 | |
I.参数(arg)与参数名(argname)
我们输入给系统调用模板的 参数 (arg) 应当为如下形式:
1 | |
即一个参数由 参数名 (argname) 与 类型(type) 组成
其中,参数名便是 标识符(identifier)
example
这么讲有些空泛,我们来简单看一个例子,在 Linux 中系统调用 read 的声明(其实是定义)如下:
1 | |
当我们使用 libc 的 wrapper 进行 read 系统调用时,形式如下:
1 | |
在这个例子当中,fd、buf、count 便是 argname,my_file_fd、my_buf、my_count 便是 type
那么,在我们使用 syzlang 编写系统调用模板时,例如 read 的第一个参数,我们应该写成下面这个样子(假设 my_file_fd 已定义为一个 resources(后面会讲)):
1 | |
II.类型(type)
其实这么翻译笔者觉得好像不大准确,不过笔者英文不大行所以这里暂且直译…
前面我们讲到一个 arg 由 一个 argname 与 type 组成,argname 我们已经讲了,现在我们来讲 type
type 的定义同样由两部分组成——类型名(typename) 与 类型选项(type-options):
1 | |
类型名(typename)
即该 type 的类型,例如 C 当中的int、char、void 等等
常规选项包括:
- opt:这是一个可选参数(例如 mmap 的 fd)
其余 type-options 是基于特定 type 的,如下:
const:整型常数
- 类型选项:
- 值(value):例如
0 - 基础类型(underlying type):
intN或intptr之一
- 值(value):例如
- 类型选项:
intN 或 intptr:一个有着特殊含义的整型,下文会进行详细说明
- 类型选项:
- 可选范围区间:例如
"1:100"表示取值值的区间为[1, 100] - 可选参数
- 可选范围区间:例如
- 类型选项:
flags:值的集合
- 类型选项:
- 对 flags 描述的引用
- 基础整型类型:例如
int32
- 类型选项:
array:一个可变长/固定长度的数组
- 类型选项:
- 元素的 type
- 可选长度区间:例如固定长度
"5"或者长度范围"5:10"(包括边界)
- 类型选项:
ptr 或 ptr64:指向一个对象的指针
- 类型选项:
- 方向:
in或out或inout - 对象的 type
- 方向:
- 无论对象指针大小如何,ptr64 永远为 8 字节
- 类型选项:
string:一块有着 0 终止符的内存缓冲区
- 类型选项:
- 常量字符串/对字符串的引用
- 前者:例如
"foo"作为常规字符串进行解析,或者`deadbeef`作为4个 16 进制字节进行解析 - 后者:若是特殊类型
filename则会生成文件名
- 前者:例如
- 常量字符串/对字符串的引用
- 类型选项:
stringnoz:一块没有 0 终止符的内存缓冲区
- 类型选项:(同
string)
- 类型选项:(同
glob:匹配目标文件的 glob(?)模式
- 类型选项:
- 用引号包裹着的模式字符串:例如
"/sys/"或"/sys/**/*/",具体用法参见https://pkg.go.dev/path/filepath#Match
- 用引号包裹着的模式字符串:例如
- 类型选项:
fmt:一个表示一个整数的字符串
- 类型选项:
- 格式与值:前者可取值为
dec或hex或oct;后者可以是一个 resource、int、flags、const 或 proc
- 格式与值:前者可取值为
- 最终的结果通常是固定尺寸的
- 类型选项:
len:另一个
字段的长度(对于 array 而言为元素的数量)- 类型选项:
- 对象的 argname
- 类型选项:
bytesize:与 len 类似,不过单位是字节
- 类型选项:
- 对象的 argname
- 类型选项:
bitsize:与 len 类型,不过单位是比特位
- 类型选项:
- 对象的 argname
- 类型选项:
offsetof:一个
字段在其 parent struct 中的偏移(笔者怎么译都没那感觉,故保留原词)- 类型选项:
字段
- 类型选项:
vma 或 vma64:指向一组页的指针(用作 mmap/munmap/mremap/madvise 的输入)
- 类型选项:
- (可选)页的数量或页的范围:前者例如
vma[7],后者例如vma[2-4]
- (可选)页的数量或页的范围:前者例如
- vma64 的长度恒为 8 字节
- 类型选项:
proc:单个进程的整型(详见下面的描述)
- 类型选项:
- 值的区间的起始
- 每个进程的值的数量
- 基础类型
- 类型选项:
text:特定 type 的机器码
- 类型选项:
- 代码类型:
x86_real,x86_16,x86_32,x86_64,arm64
- 代码类型:
- 类型选项:
void:type with static size 0(自己体会,怎么译都没那种感觉…)
- 通常在模板以及可变长(varlen)联合体中使用,不能用作系统调用的参数
在 结构体/联合体/指针 中使用时,flags/len/flags 的构成中尾部还可以跟着 type type-options
唉呀你说了这么多谁听得懂啊,还是快把🌰搬上来吧
关于 flags 的补充说明
flags 通常具有如下形式:
1 | |
这是一个🌰:
1 | |
对于 string 类型的 flag,其应当具有如下形式:
1 | |
这是一个🌰:
1 | |
类型选项(type-options)
在类型当中,类型选项其实也是可选项(
又搁这绕口令了)
type-options 在笔者的理解中为对一个特定 type 的补充说明,其应当具有如下形式:
1 | |
我们不难看出 type-options 在 syzlang 中为可选项,同样地,对于一个 type 其可以有多个 type-options
查看前面 type 的形式说明可知,在使用类型选项时,我们应当使用 [] 将之包裹
以下是一个简单的🌰(作为系统调用参数输入,而非单独的参数定义):
1 | |
从左向右解析:对于这个系统调用的 flags 参数,我们的输入是一个 flags 类型,其类型选项为对一个 flags 描述 open_flags 的引用,意为取值为 open_flags 中之一
其中 open_flags 被定义如下,这些值通过 include 语句从内核源文件中被包含进来:
1 | |
III.系统调用模板
我们将上面的结果进行整合,一个系统调用的形式应当如下:
1 | |
接下来笔者通过一个🌰进行分解说明
基本形式
我们将其最小化,我们应当书写为如下形式,类似于常规的 C 语言函数调用:
1 | |
例如对于 open 这个系统调用,我们可以写成这个样子:
1 | |
对于 open 系统调用的三个参数,我们给了这样的输入:
- file 参数:一个指针类型,其 type-opetions 的第一个为
in,意为由该指针指向特定对象,第二个为filename,为特殊的 string 对象,对于 filename,syzlang 会进行文件生成,将文件名作为输入 - flags 参数:一个 flags 类型,其 type-options 为
open_flags,意为从我们定义的 flags——open_flags中取值 - mode 参数:一个 flags 类型,其 type-options 为
open_mode,意为从我们定义的 flags——open_mode中取值
返回值
接下来我们再继续深入,系统调用通常都有返回值,我们可以选择接收也可以选择忽视,若是我们需要进行接收,则应当在系统调用的末尾添加 type ,例如 open 这个系统调用会返回一个文件描述符,我们现在想将其返回的文件描述符存到一个变量比如说 a3fd(假如已被声明为 _资源_(下文解释)) 当中,我们应当写成下面这个形式:
1 | |
那么 open 的返回值便被存储到了 a3fd 这一个 type 当中,我们在后续便可以将 fd 用作其他系统调用的参数,例如:
1 | |
call attributes
系统调用模板当中还有一个可选项是 attributes,即这一个系统调用的属性,可以取的值如下:
disabled:该系统调用将不用于 fuzzing;这个属性通常用于临时禁用某些系统调用,或者禁用特定的参数组合timeout[N]:系统调用在默认值以外的额外的超时时间,单位为毫秒(ms)prog_timeoout[N]:若一个程序包含了该系统调用,则该属性为整个程序的执行的超时时间,若存在多个定义了该属性的系统调用则取最大值ignore_return:在回退反馈(笔者推指的是 syzkaller 的 fuzz 机制之一,根据返回值判断路径覆盖之类的)中忽视这个系统调用的返回值;用于不返回固定的错误码(例如 -EFAULT)而是返回其他值的系统调用break_returns:忽略回退反馈中程序中所有后续系统调用的返回值(文档中说can't be trusted,笔者暂时不理解…)
变种(variants)
对于系统调用的变种形式,我们应当在系统调用名后面使用 $ 符号进行额外的指定
下面是一个🌰:
1 | |
按笔者的理解应该是为其取一个别名?比如说对于 syzkaller 而言
open$dir和open$a3dir就是两个东西,而若是在两个不同的文件中都出现了open$dir则会在_重编译_(下文解释)时发生冲突
IV.整型(integer)
整型也是一种 type,其可选项为 int8 、int16、int32、int64,表示相应大小的整型
intptr 用以表示一个指针大小的整型,对应 C 语言中的 long
通过添加 be 后缀表示这个整型存储为大端序
这是一个🌰:
1 | |
我们可以用这样的形式来指定 int 的范围:int32[0:100]——意为该整型的取值范围为 [0,100]
我们还可以额外指定取值的跨度,例如 int32[1:10, 2] 意为其取值为 {1, 3, 5, 7, 9}
我们还可以额外指定一个整型的取值范围,单位为比特位,例如 int64:20 意为这个整型只取其 20 bit 的值进行随机化
V.结构体、联合体与其成员(字段)
在 syzlang 中同样可以定义结构体/联合体,结构体/联合体的成员被称之为 字段(field)
结构体(struct)
在 syzlang 中,一个结构体应为如下形式:
1 | |
对于字段而言,其可以在后面的 () 中指定字段属性,但与 type 的属性不同,唯一的属性只有方向: in/out/inout,对于指定的字段,其方向属性会被上层属性给覆盖
在结构体定义的尾部,我们可以额外指定一些属性(使用 [] 包裹),可选属性有:
packed:该结构体不同字段之间没有 padding(例如 C 中有一个结构体struct T{int a; char b;};,char 为 1 字节,int 为 4 字节,那么该结构体便会对 4 字节对齐,在其两个字段之间就会有 3 字节的 padding)align[N]:指定该结构体对 N 字节对齐,padding 的内容并未指定(通常为0)size[N]:结构体被填充到指定的大小N
其实和我们在 C 语言中写结构体差不多,下面是一个🌰:
1 | |
联合体(union)
与结构体基本相同,如下:
1 | |
不同的是其属性的可选项,有:
varlen:联合体的大小可变(为指定的字段的长度),若未指定则该联合体大小为其最大字段的大小(类型 C 语言)size[N]:该联合体被填充到指定的大小N
VI.资源(resources)
资源(resources)用作那些需要作为一个系统调用的输出的值传递给另一个系统调用做输入的值。
这么说可能有些空泛,笔者来举个🌰, close 系统调用接收一个文件描述符作为参数,而这个文件描述符应当为你在之前进行 open 或 pipe 系统调用时获得的返回值,为了达成这个目的,我们需要将文件描述符(比如说叫 fd)声明为一个资源
resources 的形式如下:
1 | |
其中的 underlying_type 可以是 int8, int16, int32, int64, intptr 或者是另一个资源(可以是其子类,比如说一个 socket 便是 文件描述符的“子类”)
常量集合可以作为可选参数,表示该资源的特殊值(比如说 0xdeadbeef),特殊值偶尔被用作资源的值,若未指定特殊值,则会使用特殊值 0
资源也可以被用作类型(types),这是官方给出的一个🌰:
1 | |
资源并不一定要是系统调用的返回值,例如:
1 | |
对于更为复杂的生产者/消费者场景,字段属性也可以被利用,例如:
1 | |
VII.类型别名(Type Alias)
笔者认为可以理解为 C 中的一种特殊的 typedef,其格式如下:
1 | |
这么看可能有些空泛,我们来看一个🌰:
1 | |
在这个例子当中我们需要使用布尔值,其取值只有 0 或 1 ,所以我们需要写成 intN[0:1],但是若是在每一个需要用到布尔值的地方都这么写就太麻烦了,也不利于理解,这个时候就可以给他定义一个类型别名 boolN,简单易懂
VIII.类型模板(Type Template)
类型模板应定义为如下形式:
1 | |
唉呀谷歌你这么讲谁能够看得懂啊,还是赶紧把🌰给掏出来吧
下面是一个简单的用法🌰:
1 | |
笔者也没看明白,暂时就先不误人子弟了
IX.长度(length)
你可以使用关键字 len、bytesize、bitsize 来指定结构体当中特定字段的长度
若是 len 的参数为一个指针,则其取值为指针所指对象的大小
若要表示一个 N 字节的字 中字段的长度,则应当使用 bytesizeN,其中 N 的取值可以为 1、2、4、8
example
这是谷歌官方给出的一个🌰:
1 | |
在 write 系统调用当中,我们给其 count 参数传入了一个特殊的参数 len[buf],表示此处传入的值为参数 buf 的长度
在 sock_fprog 这个结构体当中,我们给其字段 len 设置的值为其 filter 字段的长度,类型为 int 16
若要表示父类的长度,可以使用 len[parent, intN],若要在结构体互相嵌入时表示更顶层的父类的长度,可以指定特定父类的类型名称,下面是一个🌰:
1 | |
len 也支持更加复杂的路径寻址,比如说如果你闲着没事干你可以写成谷歌给出的这个🌰里的样子:
1 | |
X.进程(proc)
进程 proc 类型可以用于表示分进程整型值,即为每一个执行程序设置一个单独的值的范围,这样他们之间就不会互相干扰,🌰如端口号就不能够被共享,而是需要每个进程有一个自己的端口
这里举一个简单的🌰, proc[20000, 4, int16be] 表示为每个进程生成一个大端序的 int16 的值,为每个进程分配其中的 4 个值,从 20000 开始分配,比如说第 N 个 executor 分配到的值范围便是 [20000 + n * 4, 20000 + (n + 1) * 4)
XI.整型常量(Integer Constants)
整型常量可以指定为十进制、0x 开头的十六进制、用单引号 ' 包裹的字符,或者从内核头文件中提取出来的由 define 定义的常量(比如说 O_RDONLY)
这是一个🌰:
1 | |
XII.杂项(Misc)
描述文件还包括用以进行内核头文件包含的 include 指令,用以包含内核头文件目录的 incdir 指令,以及用以设置常量的 define 指令
syzkaller executor 还定义了一些 pseudo system calls ,我们可以在描述文件中使用这些伪系统调用。这些伪系统调用被扩展为 C 代码,可以执行用户自定义的一些操作,这里是一些🌰
要写出优秀的描述文件,这里是一些 tips
编写并使用描述文件
Step I.编写描述文件
我们需要在 syzkaller 目录下的 syzkaller/sys/linux/ 这个目录下面新建我们自己的描述文件,比如说笔者新建一个 a3_handsome.txt 文件如下:
1 | |
随便写的,没有任何的针对性设计
在这里变种名为 a3proc,可以理解为笔者自己取的别名,这是因为若不同的描述文件中存在相同的系统调用则编译时会发生冲突
Step II.编译 syz-extract 与 syz-sysgen
接下来我们需要编译 syz-extract 与 syz-sysgen,从而应用我们新编写的描述文件
1 | |
- syz-extract 用以提取引入的内核头文件中的 define 常量等,生成
.const文件 - syz-sysgen 用以结合
.txt文件与.const文件进行语法分析和语义分析生成 AST ,最后生成.go文件
对于版本较新的 syzkaller ,其在编译时会默认编译 syz-sysgen,因此我们只需要手动编译 syz-extract 即可
Step III.处理新规则文件
使用如下命令处理我们刚刚写的规则文件
1 | |
$ARCH应为你的目标架构,可选项有amd64,386arm64,arm,ppc64le,mips64le$KSRC应为 fuzz 的内核的源码目录$LINUXBLD应为你的编译目录,为可选项(-builddir)<new>.txt就是你刚刚编写的规则文件的文件名
会在 syzkaller/sys/linux 下生成 .const 文件提取出常量,在正式编译时会进行替换,例如笔者上面给出的例程生成的 .const 文件如下:
1 | |
Step IV.重新编译 syzkaller
命令如下:
1 | |
Step V.修改配置文件,启动 syzkaller
前面我们命名了 a3proc ,因此我们还需要在配置文件中进行 enable,在你的 .cfg 文件中添加这一项:
1 | |
之后按惯例启动即可:
1 | |
*工作原理
当我们使用 syzlang 编写好模板之后,这些系统调用模板会通过 syz-extract 和 syz-sysgen 翻译为 syzkaller 能够读懂的代码,笔者这里简述一下其原理
这里你可能需要一点编译原理的知识,不过笔者相信大家编译原理应当都及格了(笑)
什么?你说你还没上这门课
什么?用 syzkaller 挖洞只要会写 syzlang 就行了,根本不需要理解他的原理简要而言,从源代码到可执行文件大概有如下过程:
- 词法分析(lexical analysis):扫描器(scanner,通常是一个有限状态自动机)从源码文本中逐字符读入,过滤掉注释,将词素映射为词法单元,生成符号表,建立映射,最终输出词素序列
- 语法分析(syntax analysis):语法分析器从词法分析器中获取词素序列,构建树形的中间表示:通常是抽象语法树(abstract syntax tree),树形中间节点表示运算分量,最终输出被称之为词法单元流的语法树
- 语义分析(semantic analysis):语义分析器使用语法树与符号表检查源程序的语义一致性,例如一个整数和一个字符串相加是符合语法规则的,但对于大部分语言而言这并不是一个合法的运算,因此不符合语义规则(
什么?你说你用 JavaScript)- 中间代码生成与优化:中间代码生成器通过语义分析的结果生成对应的中间代码(例如三地址码),并进行一定的优化
- 代码生成:由代码生成器将中间代码转为可执行代码
syz-extract
第一步是从内核源文件中提取符号常量的值:syz-extract 会根据 syzlang 文件从内核源文件中提取出使用的对应的宏、系统调用号等的值,生成 .const 文件
syz-sysgen
第二步便是将描述翻译成 Golang 代码:syz-sysgen 通过 syzlang 文件与 .const 文件进行语法分析与语义分析,生成抽象语法树,最终生成供 syzkaller 使用的 golang 代码,分为如下四个步骤:
- assignSyscallNumbers:分配系统调用号,检测不支持的系统调用并丢弃
- patchConsts:将 AST 中的常量替换为对应的值
- check:进行语义分析
- genSyscalls:从 AST 生成 prog 对象
0x04. 实战:使用 syzkaller 测试 CTF 中的闭源内核驱动
首先我们需要将 CTF 中的内核模块文件放到 syzkaller 所使用的磁盘镜像中(而非使用题目原有的磁盘镜像,因为通常那环境里啥都没有),我们需要挂载磁盘镜像并 chroot 到里边:
1 | |
创建 /etc/systemd/system/ctf-chall.service 文件写入如下内容:
1 | |
之后创建 /root/ctf-service.sh 文件,添加可执行权限,并写入如下内容(这里以这道题为例):
1 | |
使用如下命令启用自启动:
1 | |
之后退出 chroot,umount 磁盘镜像,使用该磁盘镜像启动虚拟机我们便能看到题目服务已经启动起来了
接下来我们还需要修改 syzkaller 的源码,以记录 dmesg 信息,这里将 vm/qemu/qemu.go 中 Run() 函数的开头修改为如下即可:
1 | |
0x05.实战:用 syzkaller 挖掘出 CVE-20??-????
CVE-20??-???? 是由于 ?? 原因造成的内核空间中的 ??,笔者接下来将尝试使用 syzkaller 来挖掘出该漏洞
🕊🕊🕊