【CVE.0x00】CVE-2016-5195 “脏牛”漏洞分析及利用
本文最后更新于:2025年4月21日 凌晨
快给你的🐂洗洗澡吧~
0x00.一切开始之前
CVE-2016-5195 即 dirtyCOW ,俗称「脏牛」漏洞,是 Linux Kernel 中的条件竞争漏洞,攻击者可以利用 Linux kernel 中的 COW(Copy-on-Write)技术中存在的逻辑漏洞完成对文件的越权读写
脏牛漏洞几乎涵盖了所有主流的 Linux 发行版,同时也是一个由Linus本人亲手修复的漏洞
笔者本人尝试复现的第一个 kernel 方向的 cve ,不禁感叹自己会的还是太少…
本篇文章中贴出的内核源码主要关注笔者写上中文注释的部分即可
一、写时复制机制(Copy-on-Write)
要想说清楚什么是 dirtyCOW ,首先得先把什么是 COW 给弄明白,这里我们先从教科书上讲的常规的 COW 入手
basic COW
COW 即 Copy On Write——「写时复制」:为了减少系统的开销,在一个进程通过 fork() 系统调用创建子进程时,并不会直接将整个父进程地址空间的所有内容都复制一份后再分配给子进程(虽然第一代 UNIX 系统的确采用了这种非常耗时的做法),而是基于一种更为高效的思想:
「父进程与子进程共享所有的页框」而不是直接为子进程分配新的页框,「只有当任意一方尝试修改某个页框」的内容时内核才会为其分配一个新的页框,并将原页框中内容进行复制
- 在
fork()系统调用之后,父子进程共享所有的页框,内核会将这些页框全部标为read-only - 由于所有页框被标为只读,当任意一方尝试修改某个页框时,便会触发「缺页异常」(page fault)——此时内核才会为其分配一个新的页框
大致过程如下图所示:
这便是「写时复制」的大体流程——只有当某个进程尝试修改共享内存时,内核才会为其分配新的页框,以此大幅度减少系统的开销,达到性能优化的效果
mmap 与 COW
同样地,若是我们使用 mmap 映射了一个只具有读权限而不具有写权限的文件,当我们尝试向 mmap 映射区域写入内容时,也会触发写时复制机制,将该文件内容拷贝一份到内存中,此时进程对这块区域的读写操作便不会影响到硬盘上的文件
二、缺页异常(page fault)
在 CPU 中使用 MMU(Memory Management Unit,内存管理单元)进行虚拟内存与物理内存间的映射,而在系统中并非所有的虚拟内存页都有着对应的物理内存页, 当软件试图访问已映射在虚拟地址空间中,但是并未被加载在物理内存中的一个分页时,MMU 无法完成由虚拟内存到物理内存间的转换,此时便会产生「缺页异常」(page fault)
可能出现缺页异常的情况如下:
- 线性地址不在虚拟地址空间中
- 线性地址在虚拟地址空间中,但没有访问权限
- 线性地址在虚拟地址空间中,但没有与物理地址间建立映射关系
虽然被命名为 “fault” ,但是缺页异常的发生并不一定代表出错
分类
①软性缺页异常(soft page fault)
软性缺页异常意味着相关的页已经被载入内存中,但是并未向 MMU 进行注册,此时内核只需要在 MMU 中注册相关页对应的物理页即可
可能出现软性缺页异常的情况如下:
- 两个进程间共享相同的物理页框,操作系统为其中一个装载并注册了相应的页,但是没有为另一个进程注册
- 该页已被从 CPU 的工作集(在某段时间间隔 ∆ 里,进程实际要访问的页面的集合,为提高性能,只有经常被使用的页才能驻留在工作集中,而长期不用的页则会被从工作集中移除)中移除,但是尚未被交换到磁盘上;若是程序重新需要使用该页内容,CPU 只需要向 MMU 重新注册该页即可
②硬性缺页异常(hard page fault)
硬性缺页异常意味着相关的页未经被载入内存中,此时操作系统便需要寻找到一个合适且空闲的物理页/将另一个使用中的页写到硬盘上,随后向该物理页内写入相应内容,并在 MMU 中注册该页
硬性缺页异常的开销极大,因此部分操作系统也会采取延迟页载入的策略——只有到万不得已时才会分配新的物理页,这也是 Linux 内核的做法
若是频繁地发生硬性缺页异常则会引发系统颠簸(system thrashing,有的书上也叫系统抖动)——因资源耗尽而无法正常完成工作
③无效缺页异常(invalid page fault)
无效缺页异常意味着程序访问了一个无效的内存地址(内存地址不存在于进程地址空间),在 Linux 下内核会向进程发送 SIGSEGV 信号
处理缺页异常
由于本篇所分析的漏洞存在于老版本的 Linux kernel,故我们简要分析相应版本内核(笔者选择了 v4.4)中该函数的逻辑
在接下来的分析过程中所涉及到的地址如无说明皆为【线性地址】
仅针对「文件映射缺页异常」而言,大致的流程如下图所示:(字比较丑见谅qwq
预处理:__do_page_fault()
先来看处理缺页异常的顶层函数__do_page_fault (),该函数位于内核源码中的 arch/x86/mm/fault.c 中,代码逻辑如下:
注:找寻某个函数于内核源码中的位置可以使用https://elixir.bootlin.com/
1 | |
大致流程应当如下:
- 判断缺页异常地址位于用户地址空间还是内核地址空间
- 位于内核地址空间
- 内核态触发缺页异常,
vmalloc_fault()处理 - 用户态触发缺页异常,段错误,发送SIGSEGV信号
- 内核态触发缺页异常,
- 位于用户地址空间
- 内核态触发缺页异常
- SMAP保护已开启,终止进程
- 进程无地址空间 | 设置了不处理缺页异常,终止进程
- 进入下一步流程
- 用户态触发缺页异常
- 设置对应标志位,进入下一步流程
- 检查是否是写页异常,可能是页不存在/无权限写,设置对应标志位
- 找寻线性地址所属的线性区(vma)[1]
- 不存在对应vma,非法访问
- 存在对应vma,且位于vma所描述区域中,进入下一步流程
- 存在对应vma,不位于vma所描述区域中,说明可能是位于堆栈(stack),尝试增长堆栈
- ✳调用
handle_mm_fault()函数处理,这也是处理缺页异常的核心函数- 失败了,进行重试(返回到[1],只会重试一次)
- 其他收尾处理
- 内核态触发缺页异常
其中进程描述符(task_struct)、内存描述符(mm_struct)、线性区描述符vm_arena_struct)之间的关系应当如下图所示(转自看雪论坛):
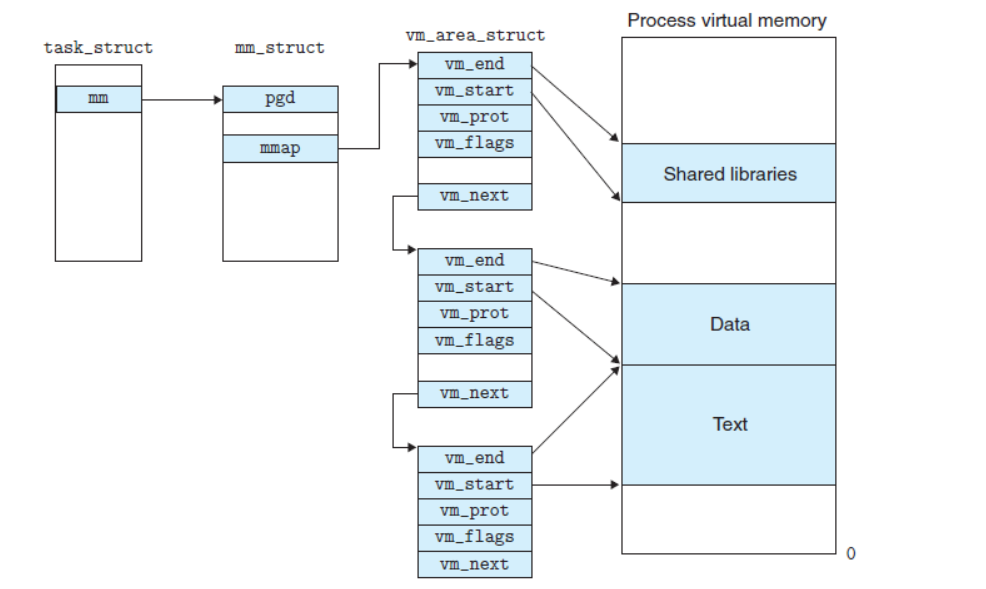
很可惜的是本次分析的dirtyCOW虽然走
__handle_mm_fault()但是不走__do_page_fault()(这不是白分析一通么(恼)
分配页表项:__handle_mm_fault()
该函数定义于 mm/memory.c 中,如下:
1 | |
该函数为触发缺页异常的线性地址address分配各级的页目录,在这里的pgd表会直接使用该进程的 mm_struct 中的 pgd 表,但是pud、pmd表都存在着创建新表的可能
此时我们已经有了与触发缺页异常的地址相对应的页表项(PTE),接下来我们将进入 handle_pte_fault() 函数进行下一步
处理页表项:handle_pte_fault()
该函数同样定义于 mm/memory.c 中,如下:
1 | |
我们不难看出该函数的流程如下:
- 或许页表项中内存页
- 该页不在主存中[1]
- pte项为空,表示进程第一次访问该页,未与物理页建立映射关系
- 该页为匿名页,分配内容初始化为0的页框
- 该页不为匿名页,调用
do_fault()进行进一步的分配操作
- pte项不为空,说明该页此前访问过,但是被换到交换空间(外存)里了(太久没用?),此时只需将该页交换回来即可
- pte项为空,表示进程第一次访问该页,未与物理页建立映射关系
- 该页在主存中[2]
- 缺页异常由【写】操作引起
- 对应页不可写,调用
do_wp_page()进行写时复制 - 对应页可写,标脏
- 对应页不可写,调用
- 将新内容写入pte页表项中
- 缺页异常由【写】操作引起
那么我们不难看出,当一个进程首次访问一个内存页时应当会触发两次缺页异常,第一次走[1],第二次走[2],后面我们再进行进一步的分析
接下来我们来看 do_fault() 函数的流程
挂载物理页:do_fault()
这个函数的逻辑较为简单,主要是根据相应的情况调用不同的函数,代码同样位于 mm/memory.c 中,如下:
1 | |
见注释,不再赘叙
处理写时复制(无内存页): do_cow_fault()
本篇主要关注写时复制的过程;COW流程在第一次写时触发缺页异常最终便会进入到 do_cow_fault() 中处理,该函数同样位于 mm/memory.c 中,代码如下:
1 | |
该函数会将拷贝的新的页更新到页表中,对应着开头的这张图,不过此时还没进行对应进程的写操作,需要等到第二次缺页异常时写入该页
处理写时复制(有内存页):do_wp_page()
当通过 do_fault() 获取内存页之后,第二次触发缺页异常时便会最终交由 do_wp_page() 函数处理,该函数同样位于 mm/memory.c 中,代码如下:
1 | |
我们不难看出其核心思想是尝试重用内存页,实在没法重用时才会进行写时复制
三、COW 与 缺页异常相关流程
当我们使用mmap映射一个只读文件,随后开辟一个新进程,尝试通过 /proc/self/mem 文件直接往一个原有的共享页面写入内容时,其流程应当如下:
系统调用:writeの执行流
用户态的 write 系统调用最终对应的是内核中的 sys_write(),该系统调用定义于 fs/read_write.c 中,如下:
直接在源码里查 sys_write 是没法查到的,这是因为系统调用对应的内核函数名都是由宏
SYSCALL_DEFINE最终拼接而成,可以参见这里
1 | |
中间的具体执行过程并非本篇重点,我们暂且略过,快进到其调用并写入用户内存页的步骤,执行流如下:
1 | |
/proc/self/mem:绕过页表项权限
“脏牛”通常利用的是 /proc/self/mem 进行越权写入,这也是整个“脏牛”利用中较为核心的流程
对于该文件,其执行流如下:
1 | |
接下来我们来看 mem_rw() 函数,该函数定义于 fs/proc/base.c 中,如下:
1 | |
其流程应当如下:
- 判断该文件对应的内存描述符是否为空,根据笔者调试的结果,第一次进入时确乎为空,返回上层,分配一个对应的
mm_struct后会重新进入该函数 - 调用
__get_free_page()函数分配一个空闲的内存页作为临时储存用户数据的空间 - 调用
access_remote_vm()函数进行内存访问操作,根据传入的write参数进行读/写内存页面操作
其中 access_remote_vm() 函数本身为 __access_remote_vm() 函数的套娃,该函数位于 mm/memory.c 中,代码如下:
1 | |
那么这个函数主要就分如下几步:
- 通过
get_user_pages()获取到对应的内存页(注意这里获取的是page结构体,因为该物理页不一定有映射) - 通过
kmap()或许到该内存页映射到的虚拟地址(若无则会建立新的临时映射) - 通过
copy_from_user_page()/copy_to_user_page()读/写对应的内存页
我们在这里主要关注点在写之前——该函数使用 get_user_pages() 获取对应的内存页,主要还是套娃,其会调用 __get_user_pages_locked() ,该函数最终调用 __get_user_pages(),定义于 mm/gup.c 中,如下:
1 | |
COW的两个要点:
- 在我们第一次尝试访问某个内存页时,由于延迟绑定机制,Linux尚未建立起该页与对应物理页间的映射,此时
follow_page_mask()返回 NULL;由于没获取到对应内存页,接下来调用faultin_page()函数解决缺页异常,分配物理页 - 调用
faultin_page()函数成功解决缺页异常之后会回到retry标签,接下来会重新调用follow_page_mask(),而若是当前进程对于该页没有写权限(二级页表标记为不可写),则还是会返回NULL;由于没获取到对应内存页,接下来调用faultin_page()函数解决缺页异常,进行写时复制
到了这里,mem_rw() 大致的流程便一目了然了:
1 | |
接下来来到缺页异常的处理函数 faultin_page() 的流程。
第一次触发缺页异常
由于 Linux 的延迟绑定机制,在第一次访问某个内存页之前 Linux kernel 并不会为其分配物理页,于是我们没法获取到对应的页表项, follow_page_mask() 返回 NULL,此时便会进入 faultin_page() 函数处理缺页异常,该函数定义于 mm/gup.c 中,如下:
1 | |
大致的调用流程如下:
1 | |
之后该页被调入主存中,但是此时我们并无对该页的写权限
第二次触发缺页异常
虽然我们成功调入了内存页,但是由于我们对该页并无写权限, follow_page_mask() 依旧会返回 NULL ,再次触发缺页异常,于是我们再次进入 faultin_page() 函数,来到了「写时复制」的流程,细节在前面已经分析过了,这里便不再赘叙
由于这一次成功获取到了一个可写的内存页,此时 faultin_page() 函数会清除 foll_flags 的 FOLL_WRITE 标志位
大致流程如下:
1 | |
接下来的流程最终回到 __get_user_pages() 的 retry 标签,第三次尝试获取内存页,此时 foll_flags 的 FOLL_WRITE 标志位已经被清除,内核认为该页可写,于是 follow_page_mask() 函数成功获取到该内存页,接下来便是常规的写入流程, COW 结束
0x01.漏洞分析
既然CVE-2016-5195俗称「dirtyCOW」,毫无疑问漏洞出现在 COW 的过程当中,现在让我们来重新审视整个 COW 的过程
多线程竞争
我们在通过 follow_page_mask() 函数获取对应的内存页之前,用以判断该内存页是否会被写入的逻辑是根据 foll_flags 的 FOLL_WRITE 标志位进行判断的,但是决定 从该内存页读出数据/向该内存页写入数据 则是由传入给 mem_rw() 函数的参数 write 决定的
我们来思考如下竞争过程,假如我们启动了两个线程:
- [1] 第一个线程尝试向「仅具有读权限的mmap映射区域写入内容」,此时便会触发缺页异常,进入到写时复制(COW)的流程当中
- [2] 第二个线程使用
madvise()函数通知内核「第一个线程要写入的那块区域标为未使用」,此时由 COW 分配得到的新内存页将会被再次调出
四次获取内存页 & 三次缺页异常
我们不难想到的是,既然这两个线程跑在竞争态,在第一个线程走完两次缺页异常的流程之后,若是第二个线程调用 madvise() 将页表项中的该页再次调出,第一个线程在第三次尝试获取内存页时便无法获取到内存页,便会再次触发缺页异常,接下来进入到 faultin_page() 的流程获取原内存页
而 __get_user_pages() 函数中 foll_flags 的 FOLL_WRITE 标志位已经在第二次尝试获取内存页、第二次触发缺页异常被清除, 此时该函数 第四次尝试获取内存页,由于不存在标志位的冲突,便可以 “正常” 获取到内存页
接下来便回到了 mem_rw()的写流程,此时我们便成功绕过了 foll_flags对于读写的检测,成功获取到只有读权限的内存页,完成越权写
0x02.漏洞利用
有了以上思路,我们的 POC 并不算特别难写,开两个线程来竞争即可
我们先通过 mmap 以只读权限映射一个文件,随后尝试通过 /proc/self/mem 文件直接向进程的对应内存区域写入,这样便可以无视 mmap 设定的权限进行写入,从而触发 COW
poc
完整 POC 如下:
1 | |
运行,成功修改只读文件
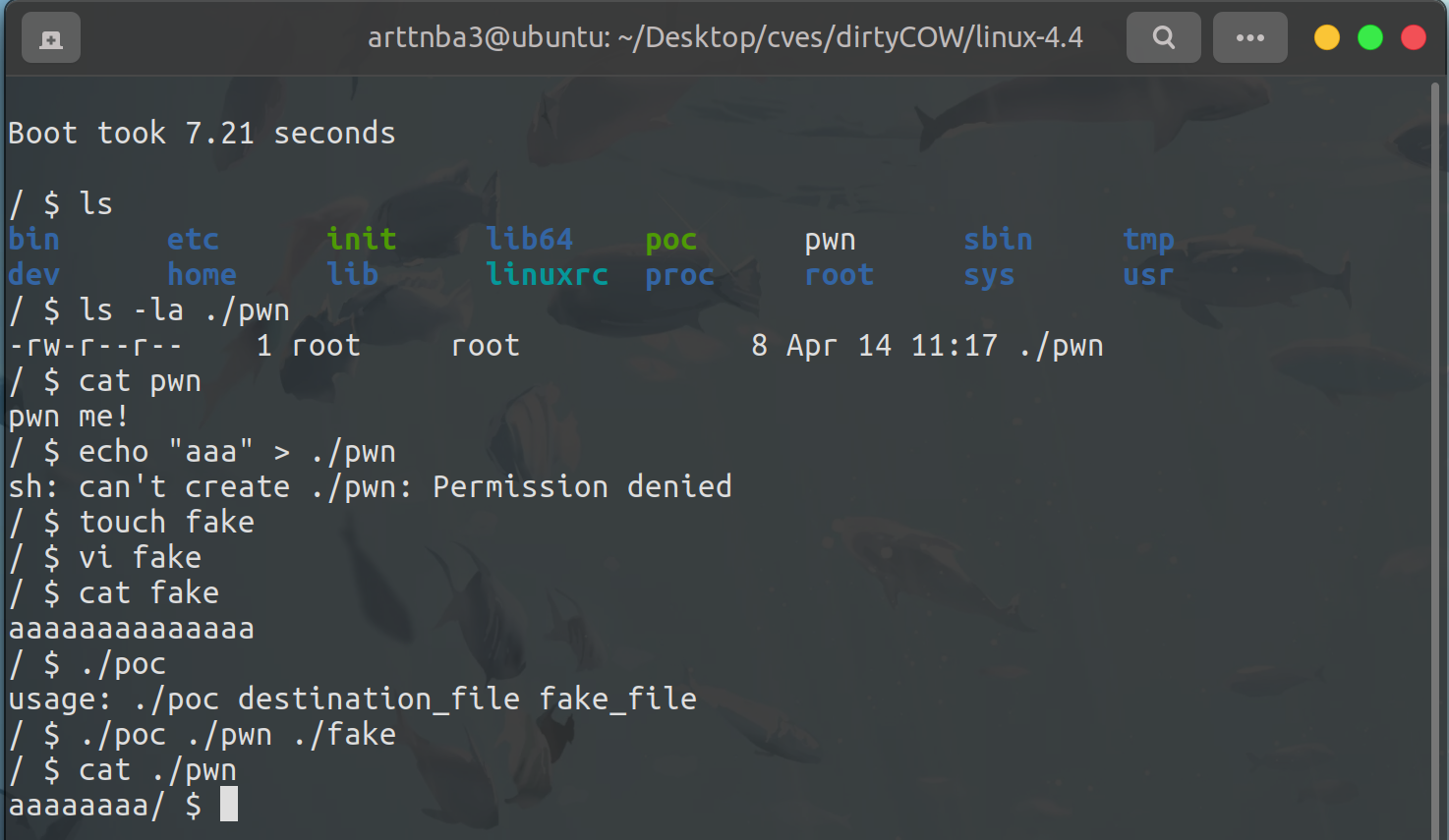
提权
一、新建 root 用户
我们可以通过修改 /etc/passwd 这个文件的方式向其中添加一个 uid 为 0 的新用户,之后再登入这个用户即可完成提权拿到 root shell,具体的构造过程就不在此赘叙了
exp 如下:
1 | |
crypt() 为非标准库函数,编译的时候需要加上 -lcrypt 参数
1 | |
运行,成功拿到 root shell
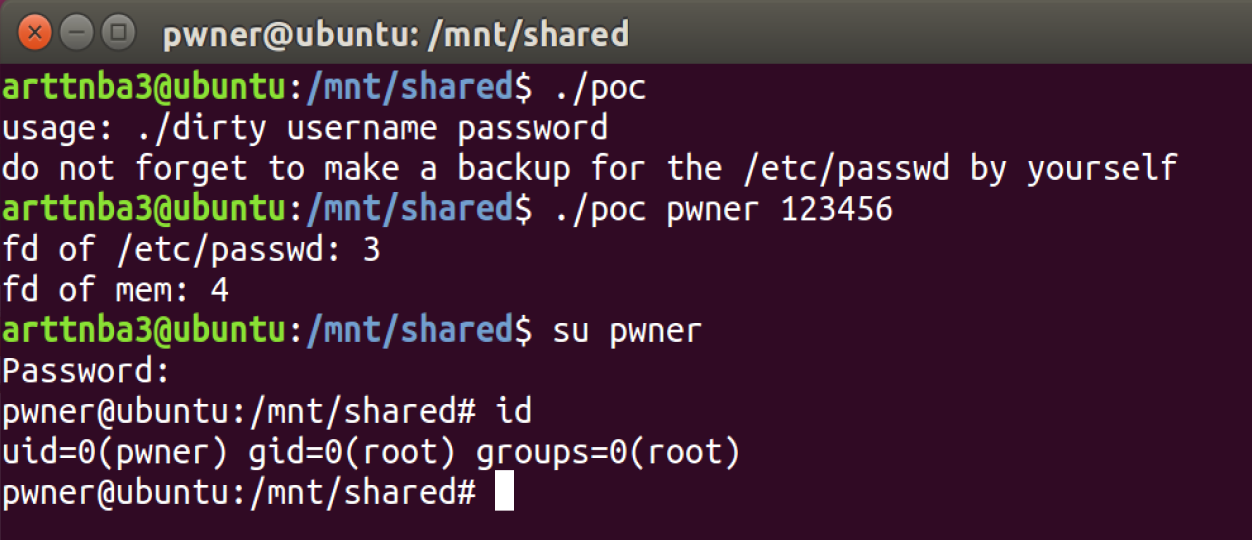
二、SUID 提权
既然有了任意文件读写,那么我们可以选择一些具有特殊权限的文件(SUID/SGID,即被设定好其执行用户(组)权限的一些文件,如 /usr/bin/passwd),将其改写为我们构造好的特定代码,我们在执行时就能完成提权
笔者这里选择改写 /usr/bin/passwd 以完成提权,因为这个程序有着 root 的执行权限
在这里笔者选择使用 msfvenom 这一个工具构造 payload,如下:
1 | |
exp 如下:
1 | |
运行,成功提权到 root
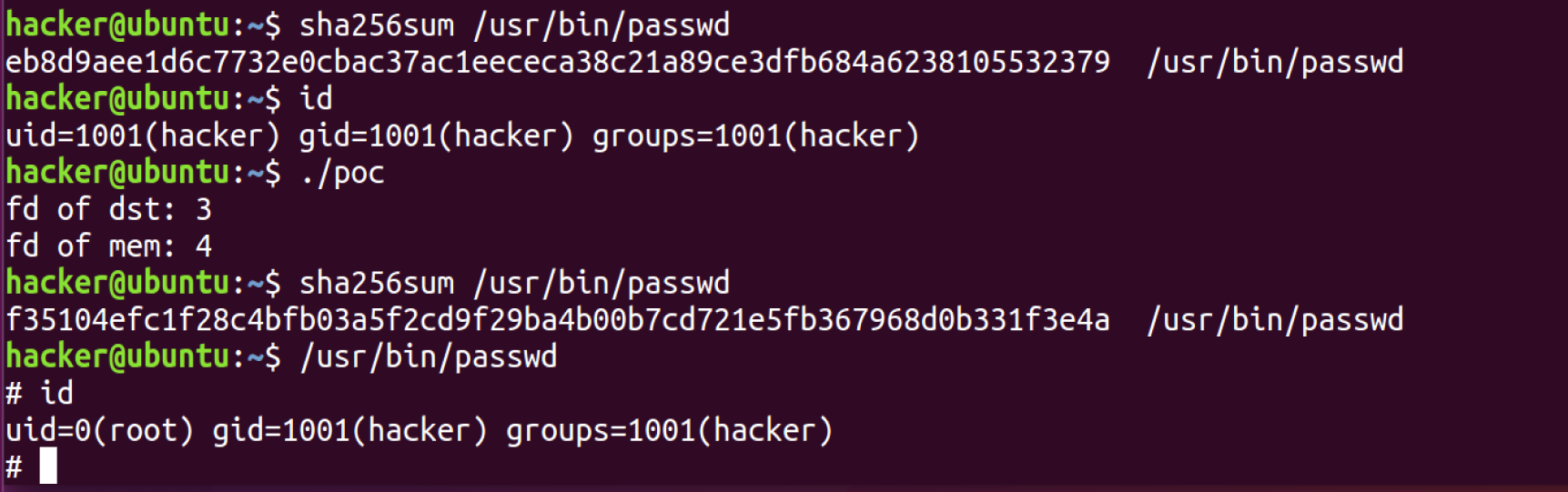
msfvenom 使用格式如下:
msfvenom -p <payload> <payload options> -f <format> -o <path>