本文最后更新于:2025年7月4日 凌晨
羊驼:会者不难
0x00. 一切开始之前 众所周知最近这几年大语言模型挺火的,包括今年年初 DeepSeek-R1 的爆火也让同是华人的笔者感到自豪(毕竟 DeepSeek 团队是“全华班”),当然更多的闲话在这里继续瞎扯没啥意义,总而言之笔者也想在本地自己部署一些轻量级的 LLM 玩一玩,包括 DeepSeek、QWEN 之类的,看了一圈发现 Ollama 方案还是挺方便的,因此简单写一篇博客讲讲怎么使用 Ollama 自行部署 LLM
0x01. 安装并使用 Ollama Ollama 是一个能够非常方便地在本地部署大模型的软件,提供了包括模型下载与管理、API 等功能,本节我们简单讲述如何安装与使用 Ollama
注:不包含 Windows 或 FreeBSD 等其他操作系统的方案,因为笔者不用这些系统:(
方法一:使用 Docker 进行部署(推荐) 众所周知前面忘了中间忘了后面也忘了,总而言之使用 Docker 等带隔离机制的工具进行部署通常是更加安全的解决方案
首先将 ollama 官方的 docker 镜像拉到本地:
1 $ docker pull ollama/ollama
然后就能直接使用了?答案是肯定的也是否定的,虽然可以直接用 CPU 来运行本地模型,但是很明显用 GPU 跑是更快的,所以我们接下来还需要将显卡接入到容器当中
如果你手上刚好没有显卡,或者你想只用 CPU 来跑本地模型,你也可以直接创建一个容器来运行:)
为 NVIDIA GPU 进行配置 NVIDIA Container Toolkit 是 NVIDIA 开发的能够让用户构建能使用 GPU 的容器的工具包,为了在容器当中使用 GPU,我们首先需要安装这一工具包
在 这篇博客 当中笔者已经讲述了如何安装并使用 NVIDIA Container Toolkit 将显卡挂载到容器当中,这里我们就简单叙述一下如何在 SUSE 系的 Linux 发行版上完成这件事,首先我们需要添加 NVIDIA 的仓库:
1 $ sudo zypper ar https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo
接下来安装 NVIDIA Container Toolkit:
1 $ sudo zypper --gpg-auto-import-keys install -y nvidia-container-toolkit
如果你使用的是 Gentoo 系统,可以直接安装社区移植到 Gentoo 仓库里的包:
1 $ sudo emerge -av app-containers/nvidia-container-toolkit
然后配置 container runtime:
1 2 $ sudo nvidia-ctk runtime configure --runtime=docker $ sudo systemctl restart docker
最后启动一个带 GPU 的 Ollama 容器,为了方便这里直接与本地共用网络:
1 $ docker run -d --network=host --gpus=all -v ollama:/root/.ollama --name ollama ollama/ollama
如果你的机器上有多张 GPU,而你想让你的容器只使用其中某一张,可以将 --gpus=all 改为 --gpus='"device=显卡标号"' 进行指定,其中显卡标号为使用 nvidia-smi 指令所获取的号码
Ollama daemon 默认会使用 11434 端口提供 API,因此我们可以将这个端口映射出来使用:
1 $ docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
简单拉一个模型测试看看效果:
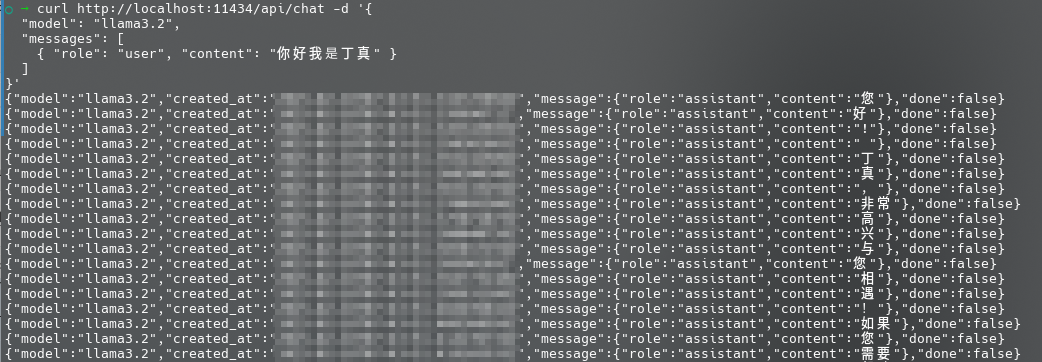
1 2 3 4 5 6 7 $ docker exec -it ollama ollama pull llama3.2 $ curl http://localhost:11434/api/chat -d '{
成功运行,不过返回结果的格式稍微有些抽象:
当然,我们也可以通过命令行与 Ollama 进行交互,只需要运行如下命令进入交互界面:
1 $ docker exec -it ollama ollama run llama3.2
然后就是一个交互式的聊天界面了,可以输入 /bye 退出:
为 AMD GPU 进行配置(🕊) 笔者手上没有 AMD 的 GPU(短期内大概率应该也不会也没钱买),所以这一节先空着🕊🕊🕊🕊🕊🕊
按照 Ollama Docker 的文档,可以运行如下命令创建带 AMD GPU 的容器,不过笔者没有试过,所以不保真:
1 $ docker run -d --device /dev/kfd --device /dev/dri -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama:rocm
方法二:直接将 Ollama 安装到本地 笔者比较推荐的是通过发行版对应的包管理器进行安装,例如笔者的服务器使用的是 openSUSE Tumbleweed,直接通过 zypper 安装即可:
1 2 $ sudo zypper in ollama $ sudo systemctl enable --now ollama
我们也可以通过官网的安装脚本将 Ollama 直接安装到本地,只需要运行:
1 $ curl -fsSL https://ollama.com/install.sh | sh
需要注意的是这个方式安装的 Ollama 会直接安装到 /usr/local/bin/lib/ollama 或是其他类似路径,然后会直接删除旧 ollama 的二进制文件,非常不优雅也不受包管理器管控,笔者不太喜欢:(
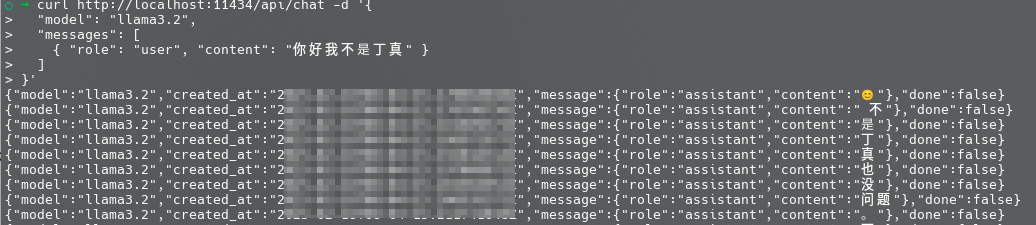
之后就能直接使用 ollama 了,这里还是简单随便测试一个模型:
1 2 3 4 5 6 7 $ ollama pull llama3.2 $ curl http://localhost:11434/api/chat -d '{
LLAMA3.2 的回答幽默程度超出笔者想象:
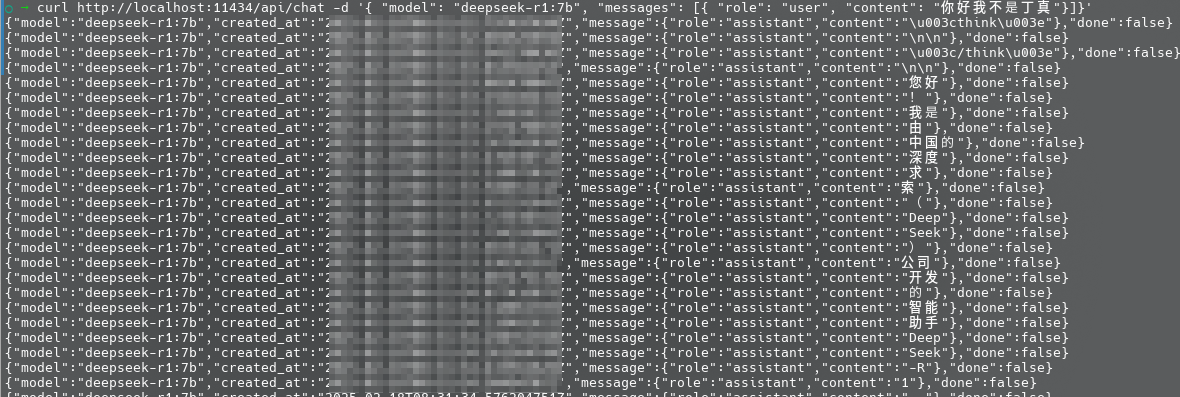
Example. 部署 DeepSeek 感觉其实没啥好讲的,直接用 Ollama 拉到本地就行,这里注意根据自己需求决定拉的版本的参数数量,笔者本地的显卡只有 6G 所以先拉一个 7B 版本的 DeepSeek-R1 试试水:
1 $ ollama pull deepseek-r1:7b
还是简单测试一下,感觉回答没有刚刚 LLAMA3.2 灵光一闪的那么幽默:
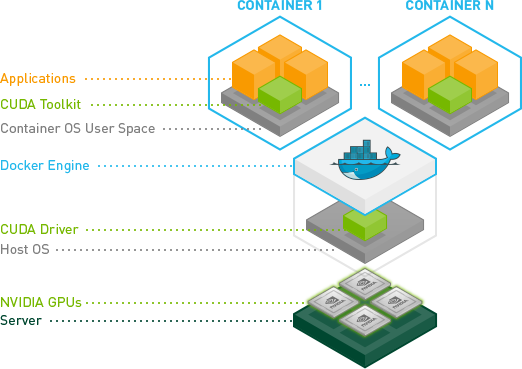
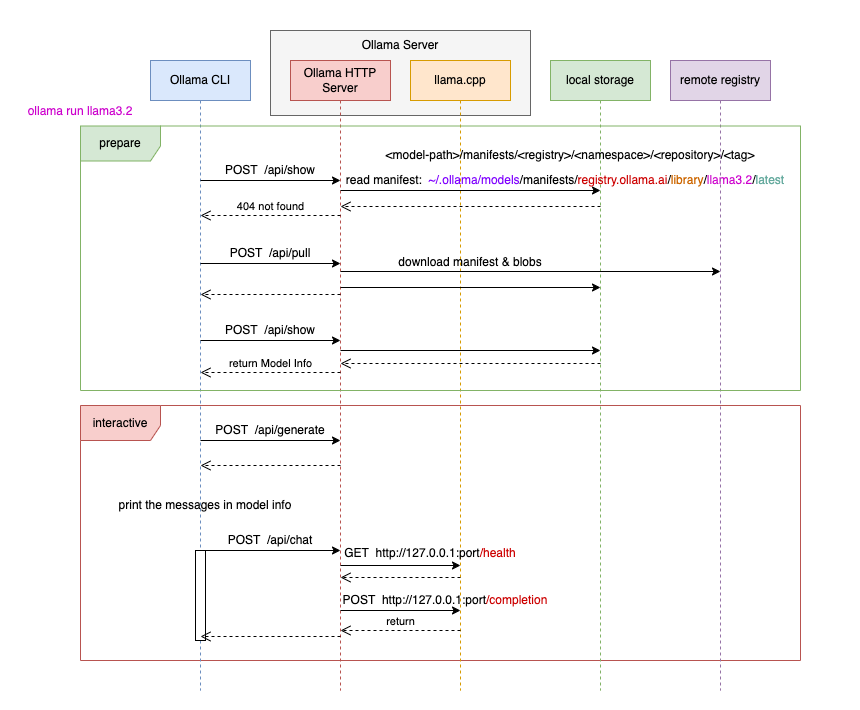
0x02. 通过 Web API 与 Ollama 进行交互 除了直接通过 shell 与 Ollama cli 聊天以外,我们还可以通过 Web API 与 Ollama 进行交互,Ollama 的基本架构如下图所示,其提供了一个 HTTP Server 供我们进行 HTTP 请求:
对于部署在本地的 Ollama,其 Web 端口通常开放于 11434 ,我们通常应当提交 POST 请求,下面我们看一些常见的 API 与例子
通过 /api/generate 进行简易交互 /api/generate 是一个简易的交互接口,用户可以通过该接口提供提示词让其生成单条回复,我们应当传入如下格式 JSON 数据作为输入:
1 2 3 4 { "model" : "模型名" , "prompt" : "你的初始提示词" }
以下是一个简易的例子:
1 2 3 4 $ curl http://localhost:11434/api/generate -d '{
可以看到 Ollama 的回答都是割裂成好多条的:
其回复通常遵循如下格式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 "model" :"模型名" ,"created_at" :"生成时间" ,"response" :"单个 token" ,"done" :false "model" :"模型名" ,"created_at" :"生成时间" ,"response" :"" , "done_reason" :"stop" , "done" :true, "context" :[ "total_duration" : 数字,"load_duration" :数字,"prompt_eval_count" :数字,"prompt_eval_duration" :数字,"eval_count" :数字,"eval_duration" :数字
通过 /api/chat 使用 ChatML 格式进行交互 基本对话 /api/chat 是最常用的交互接口,通常我们应当传递入以下格式的 JSON 数据:
1 2 3 4 5 6 { "model" : "模型名" , "messages" : [ ] }
其中 "messages" 参数我们需要传入符合 OpenAI 格式的消息上下文,即 ChatML (Chat Message Language) ,该格式虽然由 OpenAI 制定,但已经成为目前事实上的对话大模型标准,其基本结构应当为如下格式的数组:
1 2 3 4 5 6 ["role" : "角色" ,"content" : "消息"
各字段说明如下:
"role" :该字段用以表示对话的角色,可选项有:
"system" :系统消息,用以设定对话的初始背景"user" :用户输入的消息,表示用户的提问"assistant" :助手回答的消息,表示模型生成的回复
"content" :该字段用以表示角色所说的内容
例如以下是一个合法的请求:
1 2 3 4 5 6 7 8 9 10 11 12 13 {"model" : "deepseek-r1:7b" ,"messages" : ["role" : "system" ,"content" : "你是游戏主播电棍,你现在正在进行直播,并针对观众的弹幕进行回复,你的回答应当符合他的直播风格" "role" : "user" ,"content" : "你是职业选手吗"
而 ollama 的返回格式通常遵循如下格式,每次回复一个 json 直到终止:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 "model" :"模型名" ,"created_at" :"生成时间" ,"message" : {"role" :"assistant" ,"content" :"单个 token" "done" :false "model" :"模型名" ,"created_at" :"生成时间" ,"message" : {"role" :"assistant" ,"content" :"" "done_reason" :"stop" , "done" :true, "total_duration" : 数字,"load_duration" :数字,"prompt_eval_count" :数字,"prompt_eval_duration" :数字,"eval_count" :数字,"eval_duration" :数字
使用 curl 编写请求还是太粗糙了,通常我们还是得将与模型间的交互整合到实际应用当中,下面是一个简易的 Python 示例程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import requestsimport jsondef main ():"model" : "deepseek-r1:7b" ,"messages" : ["role" : "system" ,"content" : "你是游戏主播电棍,你现在正在进行直播,并针对观众的弹幕进行回复,你的回答应当符合他的直播风格" "role" : "user" ,"content" : "你是职业选手吗" 'http://localhost:11434/api/chat' '\n' )'' for i in reply:if len (i) == 0 :continue 'message' ]['content' ]print (reply_msg)if __name__ == '__main__' :
因为模型的回答断断续续的,所以我们在 Python 脚本里拼了一下,可以看到 Deepseek 模型在回复中还会带有思考过程:
Example. 将 Ollama 接入 QQ bot 这里我们使用基于 Shigure-Bot 这一 Bot SDK 开发的 Bot 应用 Shione 构建一个用于聊天的插件,Bot 后端使用兼容 OneBot 11 API 的开源 NT QQ Protocol 的实现 Lagrange.Core ,如何与这些框架进行对接以及具体使用方式留给读者课后自行阅读文档了(笑
首先编写一个核心函数用以处理模型的回复消息,这里笔者额外添加了一个在使用 Deepseek 时把思考过程删去的过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 func ParseOLLAMAReply (rawReplyMsg []byte ) string , error ) {var respMsg string byte ("\n" ))for _, respJsonData := range respJsonDataList {make (map [string ]interface {})if err != nil {return "" , errors.New(fmt.Sprintf("Error parsing reply: %v, original reply data:\n%v" , err.Error(), respJsonData))if respJson["done" ].(bool ) {break "message" ].(map [string ]interface {})["content" ].(string )if len (respMsg) > len ("<think>" ) && respMsg[:len ("<think>" )] == "<think>" {"</think>\n" )if len (splitRes) > 1 {1 ]return respMsg, nil
然后是消息请求函数,我们将请求直接发给对应路径即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 func RequestModel (provider string , url string , model string , headers map [string ]interface {}, maxWaitingTime time.Duration, messages interface {}) byte , error ) {make (map [string ]interface {})"model" ] = model"messages" ] = messagesif err != nil {return nil , err"POST" , url, bytes.NewBuffer(reqBodyJson))if err != nil {return nil , err"Content-Type" , "application/json" )if headers != nil {for k, v := range headers {string ))if err != nil {return nil , errdefer resp.Body.Close()if resp.StatusCode != 200 {return nil , errors.New("Response status code is " + strconv.Itoa(resp.StatusCode))if err != nil {return nil , errreturn respBody, nil
之后在上面再套一层,其根据不同的供应商选择调用不同的消息处理函数,这里我们只有 Ollama 所以只需要调用前面写的 ParseOllamaReply:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 func ChatWithAI (provider string , url string , model string , prompt string , headers map [string ]interface {}, maxWaitingTime time.Duration, messages interface {}) string , error ) {var respMsg string if err != nill {return "" , errswitch provider {case "Ollama" :if err != nil {return "" , errbreak default :return "" , errors.New("Unknown provider: " + provider)return respMsg, nil
之后可以自己预先构筑一个想要的上下文作为输入来构造一个自己想要的 bot 人格,下面简单测试一下: