本文最后更新于:2024年8月19日 下午
真是序序又列列啊,你们有没有这样的文件接口啊我想问
0x00. 一切开始之前 笔者大二上那会学 kernel pwn 时便经常在用户态用到序列文件接口,不过在那个时候笔者只关心打开 /proc/self/stat 文件便能分配一个 kmalloc-32 对象(seq_operations );大二下写 Linux kernel rootkit 时又碰到 /proc/kallsyms 无法在内核层读取的问题,不过也是了解了一下序列文件接口的相关知识就没有再继续深入了(不过这个东西本来就很简约,就其本身而言确实没有什么能够深入的地方)
刚好笔者最近的工作又接触到了这个玩意,所以简单写一篇博客记录一下这是个什么玩意:)
0x01. 序列文件接口 - 简介 序列文件接口 是在现有 VFS 上建立的一套用于 从内核空间向用户空间提供传输序列数据 的接口,这里我们将序列数据简单定义为 由多条数据组成的数据 (例如 /proc/kallsyms 为用户提供了多条内核符号信息数据),这个场景下内核通常需要多次迭代地向用户空间拷贝多条数据
序列文件接口的设计主要出于一个原因:【大于一页的文件操作对于开发者而言非常麻烦】 ,我们要从内核空间向用户空间传递数据通常需要自行创建如 procfs 等节点并自定义一份 file_operations ,开发者能用的只有一个裸的 read(struct file *, char __user *, size_t, loff_t *) ,而对于这类功能比较单一的场景, 设计上要考虑的和常规的文件接口相比却一个都不能少 (跨页多条数据拷贝的文件偏移处理确实不是个小问题),这增大了开发者的开发难度,但序列数据的传输在内核开发中其实又是一个非常常见的场景
由此,针对此类场景,序列文件接口应运而生,为上层开发者提供了类似【迭代器】的简易文件读取接口 ,由此极大地简化了对于此类场景的内核开发工作
本篇博客使用的内核源码为 6.9.1
序列文件接口开发:操作函数 要使用序列文件接口,我们需要实现一个 seq_operations 函数表:
1 2 3 4 5 6 7 8 #include <linux/seq_file.h> struct seq_operations {void * (*start) (struct seq_file *m, loff_t *pos);void (*stop) (struct seq_file *m, void *v);void * (*next) (struct seq_file *m, void *v, loff_t *pos);int (*show) (struct seq_file *m, void *v);
各函数指针说明如下(按照被调用顺序 ):
start :在开始读取序列数据前进行初始化工作,并返回指定偏移上的序列数据对象show :打印传入的序列数据对象,该函数会被循环调用next : 根据传入的偏移值与当前对象获取下一个序列数据对象,并自增偏移值,该函数会被循环调用stop :在完成对序列文件的遍历后用以进行需要的收尾工作,可以为空函数
需要注意的是,这里所说的偏移值通常指的 其实是序列数据对象的索引值 ,而非基于具体内存对象大小计算的值
除了 seq_operations 函数表以外,序列文件接口对于每个文件还会额外分配一个 seq_file 结构体(在 open() 时分配到 file->private )用以存储如当前的读取偏移、整个序列的长度等数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct seq_file {char *buf;size_t size;size_t from;size_t count;size_t pad_until;loff_t index;loff_t read_pos;struct mutex lock ;const struct seq_operations *op ;int poll_event;const struct file *file ;void *private;
核心的字段说明如下:
buf :临时存放由 show() 打印的数据,通常为单张内存页大小,数据会先被拷贝到这块内存上再拷贝回用户空间size :buf 的总大小from:buf 当前数据写入的起始偏移count :buf 已经写入的大小,序列文件上的有效待写入数据为 &seq_file::buf[seq_file::from] 起始的长度为 seq_file::count 的区域 ,通常每一轮读取都会刷新一次 count 字段index : 当前正在读取的对象的偏移值read_pos :成功读取的数据量(字节)op :序列文件接口的函数表 其实是指玩原神的人 file :对应的 VFS file 节点private :供上层开发者存放私人数据
下面我们以一个基础的链表结构作为示例说明如何基于序列文件接口进行基本的开发:
1 2 3 4 5 6 struct a3_seq_data {struct list_head list ;char data[0x100 ];
start():序列文件读取初始化 内核将单次 read() 系统调用读取的过程称之为一个 session ,在每个 session 开始时都会调用序列文件接口的 start() 函数以进行初始化,核心作用是 在读取开始时获取指定偏移值上的对象作为起始点 ,我们通常需要返回指定偏移上的序列数据对象
在现代内核及驱动开发场景中 start() 所获取到的通常是第一个序列数据对象,这也是序列文件接口的规范用法, 因为大部分情况下开发者并不需要处理偏移值不为 0 的场景 ,因此也可以简单返回一个 SEQ_START_TOKEN (值为 1)
该值用于在 next() 与 show() 中供你自己进行识别 ,所以只要你认得就行
对于读取到末尾的情况(偏移值超出范围), 通常直接返回 NULL 即可 ,对于初始化失败的场景,我们还可以返回一个 ERR_PTR 类型值进行说明
以下是我们的示例代码,这里我们简单地返回链表上指定偏移的对象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 static void * a3kmod_seq_start (struct seq_file *m, loff_t *ppos) struct a3_seq_data *ptr ;loff_t cpos = 0 ;list ) {if (cpos == (*ppos)) {return ptr;return NULL ;
show():打印指定的序列数据 show() 函数用于将当前序列对象需要被导出的数据通过序列文件的打印接口拷贝到指定的临时内存(即 seq_file::buf )上,这些数据会在多次遍历完成后(buf 满了或者序列遍历完成)统一拷贝到用户空间,可用的接口通常有:
1 2 3 4 5 6 7 8 9 10 void seq_printf (struct seq_file *m, const char *fmt, ...) ; void seq_putc (struct seq_file *m, char c) ;void seq_puts (struct seq_file *m, const char *s) ;void seq_escape (struct seq_file *m, const char *s, const char *esc) ;int seq_path (struct seq_file *m, const struct path *path, const char *esc) ;int seq_path_root (struct seq_file *m, const struct path *path, const struct path *root, const char *esc)
正常打印完成需要返回 0,返回小于 0 的值表示出错,返回大于 0 的值( SEQ_SKIP )表示跳过该项,以下是我们的示例代码:
1 2 3 4 5 6 7 8 static int a3kmod_seq_show (struct seq_file *m, void *v) struct a3_seq_data *data ="[a3kmod_data] data: %s\n" , data->data);return 0 ;
next():获取指定偏移上的序列数据,自增偏移值 next() 函数用以 根据传入的偏移值获取下一个序列数据对象,并更新偏移值 ,在单次 session 中会迭代地调用 next() 函数,直到当前数据页无法继续装载,或是已经读取完序列上所有的数据
在 next() 函数当中,我们需要更新上层的 index (通常直接 +1 即可),并返回下一个序列数据对象,以下是我们的示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 static void * a3kmod_seq_next (struct seq_file *m, void *v, loff_t *ppos) struct a3_seq_data *ptr =list );if (unlikely(list_entry_is_head(ptr, &a3_seq_list, list ))) {return NULL ;return ptr;
stop():序列文件关闭清理 stop() 函数用于在单个 session 结束时进行一些自定义的需要的清理工作,因此通常也可以只是一个空函数,以下是我们的示例代码:
1 2 3 4 static void a3kmod_seq_stop (struct seq_file *m, void *v)
序列文件接口开发:初始化 完成了序列文件接口四个函数的定义后,接下来我们需要在创建通用 VFS 节点时进行初始化,主要就是定义四个通用函数:
open() :该函数中我们需要调用 seq_open() 进行初始化,其会分配一个 seq_file 结构体存放到 file->private ,我们也可以使用 __seq_open_private() (等价于多一次 kmalloc() 分配自定义数据对象)二选一:
read() :该函数指针需要被初始化为 seq_read() ,但你也可以再套个 wrapperread_iter() :该函数指针需要被初始化为 seq_read_iter() ,但你也可以再套个 wrapper
lseek() :该函数指针需要被初始化为 seq_lseek() ,但你也可以再套个 wrapperrelease() :该函数指针需要被初始化为 seq_release() ,但你也可以再套个 wrapper
之后像往常一样初始化文件接口即可,对序列文件接口的操作都会直接通过这些 seq_* API 完成,这极大地简化了开发者的工作,以下是我们以 procfs 为例的示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 static const struct seq_operations a3kmod_seq_ops =static int a3kmod_open (struct inode *i, struct file *f) return seq_open(f, &a3kmod_seq_ops);static const struct proc_ops a3kmod_ops =static void a3kmod_release_data_list (void ) struct a3_seq_data *cur , *next ;list ) {list );static int __init a3kmod_init (void ) struct a3_seq_data *data ;"[a3kmod:] Hello to kernel space!\n" );for (int i = 0 ; i < 0x10 ; i++) {sizeof (*data), GFP_KERNEL);if (!data) {"[a3kmod:] FAILED to alloc data!\n" );return -ENOMEM;sprintf (data->data, "arttnba3 - no.%.2d data" , i);list , &a3_seq_list);if (!proc_create("a3kmod" , 0666 , NULL , &a3kmod_ops)) {"[a3kmod:] FAILED to create procfs interface!\n" );return -EACCES;"[a3kmod:] Initialization done.\n" );return 0 ;static void __exit a3kmod_exit (void ) "[a3kmod:] Goodbye to kernel space!\n" );"a3kmod" , NULL );"GPL v2" );"arttnba3" );
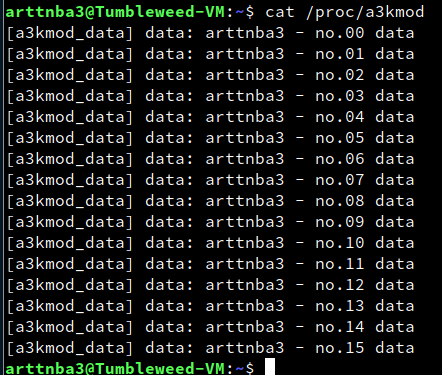
简单测试一下,可以看到内核非常完美地按照我们的需求输出了序列文件数据:
序列文件接口开发:single file(仅单个序列对象读取的简易预实现) /fs/seq_file.c 中除了序列文件接口以外,还有一套已经写好的 single_* 开头的序列文件接口实现,开发者只需要补充实现 show() 函数即可,这通常用于一些并不需要太复杂实现的 只需要读取一次的 场景(例如读取 /proc/self/stat ):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 void *single_start (struct seq_file *p, loff_t *pos) return *pos ? NULL : SEQ_START_TOKEN;static void *single_next (struct seq_file *p, void *v, loff_t *pos) return NULL ;static void single_stop (struct seq_file *p, void *v) int single_open (struct file *file, int (*show)(struct seq_file *, void *), void *data) struct seq_operations *op =sizeof (*op), GFP_KERNEL_ACCOUNT);int res = -ENOMEM;if (op) {if (!res)struct seq_file *)file->private_data)->private = data;else return res;
使用 single file 实现我们只需要将前面的 seq_open() 替换为 single_open() 并定义一个 show() 即可,注意传给 show() 的序列对象永远都是 NULL ,以下是一个简单的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <linux/module.h> #include <linux/kernel.h> #include <linux/init.h> #include <linux/fs.h> #include <linux/proc_fs.h> #include <linux/seq_file.h> struct a3_data {char name[0x100 ];size_t age;size_t money;"arttnba3" ,23 ,0 ,static int a3kmod_seq_show (struct seq_file *m, void *v) "[a3kmod_data] name: %s\n" , a3_info.name);"[a3kmod_data] age: %ld\n" , a3_info.age);"[a3kmod_data] money: %ld\n" , a3_info.money);return 0 ;static int a3kmod_open (struct inode *i, struct file *f) return single_open(f, a3kmod_seq_show, NULL );static const struct proc_ops a3kmod_ops =static int __init a3kmod_init (void ) if (!proc_create("a3kmod" , 0666 , NULL , &a3kmod_ops)) {"[a3kmod:] FAILED to create procfs interface!\n" );return -EACCES;"[a3kmod:] Initialization done.\n" );return 0 ;static void __exit a3kmod_exit (void ) "[a3kmod:] Goodbye to kernel space!\n" );"a3kmod" , NULL );"GPL v2" );"arttnba3" );
测试一下:
序列文件接口开发:proc_seq 接口 proc_seq 接口同时提供了创建 procfs 节点与初始化 seq_file 的功能,我们只需要调用 proc_create_seq() 便能创建 procfs + 初始化 seq_file 一步到位,底层而言不同的是其帮我们实现的是 read_iter 接口而非 read() 接口,这意味着 这样的序列文件可以从内核侧被读取
下面是对上面的链表读取的例子进行简单重写的例子:
其实也没有简化太多…
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 #include <linux/module.h> #include <linux/kernel.h> #include <linux/init.h> #include <linux/fs.h> #include <linux/proc_fs.h> #include <linux/seq_file.h> struct a3_seq_data {struct list_head list ;char data[0x100 ];static void * a3kmod_seq_start (struct seq_file *m, loff_t *ppos) struct a3_seq_data *ptr ;loff_t cpos = 0 ;list ) {if (cpos == (*ppos)) {return ptr;return NULL ;static void * a3kmod_seq_next (struct seq_file *m, void *v, loff_t *ppos) struct a3_seq_data *ptr =list );if (unlikely(list_entry_is_head(ptr, &a3_seq_list, list ))) {return NULL ;return ptr;static int a3kmod_seq_show (struct seq_file *m, void *v) struct a3_seq_data *data ="[a3kmod_data] data: %s\n" , data->data);return 0 ;static void a3kmod_seq_stop (struct seq_file *m, void *v) static const struct seq_operations a3kmod_seq_ops =static void a3kmod_release_data_list (void ) struct a3_seq_data *cur , *next ;list ) {list );static int __init a3kmod_init (void ) struct a3_seq_data *data ;"[a3kmod:] Hello to kernel space!\n" );for (int i = 0 ; i < 0x10 ; i++) {sizeof (*data), GFP_KERNEL);if (!data) {"[a3kmod:] FAILED to alloc data!\n" );return -ENOMEM;sprintf (data->data, "arttnba3 - no.%.2d data" , i);list , &a3_seq_list);if (!proc_create_seq("a3kmod" , 0666 , NULL , &a3kmod_seq_ops)) {"[a3kmod:] FAILED to create procfs interface!\n" );return -EACCES;"[a3kmod:] Initialization done.\n" );return 0 ;static void __exit a3kmod_exit (void ) "[a3kmod:] Goodbye to kernel space!\n" );"a3kmod" , NULL );"GPL v2" );"arttnba3" );
简单测试:
0x02. 序列文件接口 - 实现原理 序列文件接口的实现其实可以理解成在 VFS 上套了一层通用 wrapper,整体上还是比较简单的,本节我们从 VFS 文件接口的调用路径来看序列文件接口是如何实现的
seq_open() : 序列文件初始化 使用序列文件接口需要在自定义的 read() 函数中调用 seq_open() 进行初始化,这个函数的作用其实就是分配一个 seq_file 结构体存放到 file::private 中,并去除文件属性 file::f_mode 中的 FMODE_PWRITE 位(即文件变得不可被使用 pwrite() 访问,因为这个函数不会改变文件偏移,对序列文件接口而言增加了操作复杂性)
不过比起简约的函数本身,注释则详细地对序列文件接口进行了说明:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 int seq_open (struct file *file, const struct seq_operations *op) struct seq_file *p ;if (!p)return -ENOMEM;return 0 ;
这个函数有一个更常用的 wrapper 叫 __seq_open_private() ,主要就是帮开发者多 kmalloc() 一个内存对象放到 seq_file::private 中,这里不再赘叙:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 void *__seq_open_private(struct file *f, const struct seq_operations *ops,int psize)int rc;void *private;struct seq_file *seq ;if (private == NULL )goto out;if (rc < 0 )goto out_free;return private;return NULL ;
(⭐核心)seq_read() :读取序列文件 seq_read() 是正常 VFS 路径上 read() 会调用的函数,因为对于序列文件接口而言我们将函数表中的函数指针指定为该函数,不过这个函数主要是对 seq_read_iter() 的包装,在调用之前简单初始化了写入目标记录 iovec 与操作记录块 kiocb :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ssize_t seq_read (struct file *file, char __user *buf, size_t size, loff_t *ppos) struct iovec iov =struct kiocb kiocb ;struct iov_iter iter ;ssize_t ret;1 , size);return ret;
什么,你还不知道 iovec、 kiocb、iov_iter 是什么东西?简单来说就是在内核 IO 中用于存放操作信息的数据结构,前者是基础结构,后两者主要配对用于异步 IO:
iovec:io vector,表示一块带长度的缓冲区
kiocb:kernel i/o call back ,记录文件侧 IO 信息,包括文件指针、当前偏移等
iov_iter :iovec iterator ,用来操作 iovec 的迭代器,记录内存侧 IO 信息,包括内存地址、当前偏移等
下面我们来到序列文件读取的核心函数 seq_read_iter() ,首先会检查文件侧偏移,若是 0 则将序列文件的序列对象偏移与读取字节数也都设为 0:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 ssize_t seq_read_iter (struct kiocb *iocb, struct iov_iter *iter) struct seq_file *m =size_t copied = 0 ;size_t n;void *p;int err = 0 ;if (!iov_iter_count(iter))return 0 ;if (iocb->ki_pos == 0 ) {0 ;0 ;
若是文件侧偏移与序列文件读取偏移不等则调用 traverse() 函数处理,如果出错直接跳到 Done 进行收尾,否则将序列文件偏移与文件偏移进行同步:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 if (unlikely(iocb->ki_pos != m->read_pos)) {while ((err = traverse(m, iocb->ki_pos)) == -EAGAIN)if (err) {0 ;0 ;0 ;goto Done;else {
traverse() 函数有点类似一个小的 seq_read_iter() 的核心,作用其实是 将序列文件的偏移同步到指定的偏移值 ,这里是同步到文件侧记录的偏移 :
初始化从第一个序列数据对象开始读取,检查序列文件的临时缓冲区是否分配
调用 op->start() 初始化后进入读取循环:
首先调用 op->show() 打印到临时缓冲区上
调用 seq_has_overflowed() 检查临时缓冲区是否读满,满则跳到 Eoverflow 标签重新分配一块更大的内存,需要注意的是 traverse() 的作用主要是进行正式读取前的偏移同步,因此不会保存前面读取的数据
调用 op->next() 移动到下个序列数据对象,若本次超出预期偏移则减去对应数据量大小并退出循环,注意这里额外用了一个变量 pos 记录读取的数据量,且每次完成读取会清空临时缓冲区读取计数 m->count 加到 pos 上
若完成读取到指定偏移的任务则退出循环
调用 op->stop() 终止读取并返回
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 static int traverse (struct seq_file *m, loff_t offset) loff_t pos = 0 ;int error = 0 ;void *p;0 ;0 ;if (!offset)return 0 ;if (!m->buf) {if (!m->buf)return -ENOMEM;while (p) {if (IS_ERR(p))break ;if (error < 0 )break ;if (unlikely(error)) {0 ;0 ;if (seq_has_overflowed(m))goto Eoverflow;if (pos + m->count > offset) {break ;0 ;if (pos == offset)break ;return error;0 ;1 );return !m->buf ? -ENOMEM : -EAGAIN;
回到 seq_read_iter() ,接下来首先检查 buf 是否分配,之后检查 buf 上是否有数据 m->count != 0 ,若是则拷贝到 iovec 所指示的内存上:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 if (!m->buf) {if (!m->buf)goto Enomem;if (m->count) {if (m->count) goto Done;
然后是预检查部分,作用是 进行一次读取,并检查缓冲区大小是否足够 :
首先初始化序列文件临时缓冲区的起始偏移为 0,调用 op->start() 进行初始化,然后进入读取循环:
首先调用 op->show() 打印当前序列数据对象到临时缓冲区,若跳过(如 SEQ_SKIP )则当前轮的读取长度( m->count )记为 0 ,并开始下轮循环
若临时缓冲区未满 ,跳到 Fill 标签 开始正式的继续读取 ,否则调用 op->stop() 停止并重新分配一个更大的缓冲区 ,之后重新读取当前序列数据对象
若正常退出循环(break),说明读取失败,调用 op->stop() 停止并直接跳到 Done 标签进行收尾
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 0 ;while (1 ) {if (!p || IS_ERR(p)) break ;if (err < 0 ) break ;if (unlikely(err)) 0 ;if (unlikely(!m->count)) { continue ;if (!seq_has_overflowed(m)) goto Fill;0 ;1 );if (!m->buf)goto Enomem;0 ;goto Done;
接下来就是核心的数据读取部分了:
核心还是一个读取循环,不过前面预读取时已经 start() 过了所以这里直接开始读取:
首先直接调用 op->next() 获取下一个序列数据对象(因为前面已经读过一次了),若开发者定义的该函数没有更新 m->index 则会手动自增,获取出错则跳出循环
若缓冲区上已有数据量大于 iovec 迭代器剩余量(iov_iter_count(iter))则跳出循环
调用 op->show() 将新获取到的序列数据对象打印到缓冲区上,若溢出则跳出循环,注意这里的 offs 记录的是当前次循环开始前的 m->count
接下来调用 op->stop() 停止,并调用 copy_to_iter() 将临时缓冲区上数据拷贝到 iovec 迭代器所指示的 iovec 所指示的内存上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 Fill:while (1 ) {size_t offs = m->count;loff_t pos = m->index;if (pos == m->index) {"buggy .next function %ps did not update position index\n" ,if (!p || IS_ERR(p)) break ;if (m->count >= iov_iter_count(iter))break ;if (err > 0 ) { else if (err || seq_has_overflowed(m)) {break ;
最后就是一些常规的收尾工作,例如在序列文件与 kiocb 中记录拷贝的字节数等:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Done:if (unlikely(!copied)) {else {return copied;goto Done;
不难看出序列文件接口的读取实现其实非常的简洁
seq_lseek():序列文件偏移操作 这个函数比较简洁,主要就是移动当前的序列文件偏移,对于相对偏移值(SEEK_CUR 路径)会先转换成绝对偏移值,进行偏移值计算的路径归一化,偏移值移动则主要靠 traverse() 完成,前文已经讲过故这里不再赘叙:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 loff_t seq_lseek (struct file *file, loff_t offset, int whence) struct seq_file *m =loff_t retval = -EINVAL;switch (whence) {case SEEK_CUR:case SEEK_SET:if (offset < 0 )break ;if (offset != m->read_pos) {while ((retval = traverse(m, offset)) == -EAGAIN)if (retval) {0 ;0 ;0 ;0 ;else {else {return retval;
seq_release():关闭序列文件 这个函数主要是进行释放内存的收尾工作,不再赘叙:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int seq_release (struct inode *inode, struct file *file) struct seq_file *m =return 0 ;
对于 __seq_open_private() ,也有一个对应的关闭函数 seq_release_private() ,同样是在 seq_release() 上的 wrapper,不过会帮你释放掉 seq_file::private :
1 2 3 4 5 6 7 8 9 int seq_release_private (struct inode *inode, struct file *file) struct seq_file *seq =NULL ;return seq_release(inode, file);
至此序列文件接口的实现基本完结,可以看到这个实现其实非常的简洁,这个场景在内核中其实非常常见(例如读取各种内核对象的信息),对于开发者而言并不需要每个场景都手写一套,因此通用的序列文件接口应运而生
0x03. 序列文件接口 - 其他 序列文件接口其实没啥更多能讲的东西了,这一节主要记录一些比较零碎的迷思
在内核中读取特殊序列文件
部分的序列文件接口对于内核空间是不可以使用 kernel_read() 进行读取的,因为其文件函数表实现的是 read() 接口而非 read_iter() 接口,但是实战开发中我们往往又需要在内核空间读取一些序列文件,这通常是因为这一部分内核数据的获取接口并不对内核驱动导出,但留有向用户空间导出的序列文件接口,此时序列文件接口便几乎是我们唯一的数据获取方式
例如在 rootkit 开发当中我们通常需要获取各种内核符号的地址,但对应的获取内核符号的内核接口 kallsyms_lookup_name() 在内核版本 5.7.0 后默认不再导出,因此我们只能通过读取 /proc/kallsyms 进行获取
解决的方案其实很简单: 我们只需要分配一块属于用户空间的临时内存即可 ,这可以通过 vm_mmap() & vm_munmap() 完成,下面是一个简单的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 #include <linux/module.h> #include <linux/kernel.h> #include <linux/init.h> #include <linux/fs.h> #include <linux/mm.h> #include <linux/types.h> #include <linux/mman.h> static int __init a3kmod_init (void ) struct file *filp ;char __user *ubuf;char *kbuf;int ret = 0 ;ssize_t read_len;loff_t fpos;"[a3kmod:] Hello to kernel space!\n" );void *) vm_mmap(NULL ,0 ,0 );if (!ubuf) {"[a3kmod:] FAILED to allocate userspace buf!\n" );goto out_ret;"/proc/kallsyms" , O_RDONLY, 0 );if (IS_ERR(filp)) {"[a3kmod:] FAILED to open file! Error code: %ld\n" ,goto out_free_ubuf;if (!kbuf) {"[a3kmod:] FAILED to allocate kernelspace buf!\n" );goto out_close_file;memset (kbuf, 0 , PAGE_SIZE);0 ;if (read_len < 0 ) {"[a3kmod:] FAILED to read file! Error code: %ld\n" ,goto out_close_file;if (copy_from_user(kbuf, ubuf, read_len)) {"[a3kmod:] FAILED to copy data to kernel!\n" );goto out_close_file;"[a3kmod:] Got data: %s\n" , kbuf);NULL );unsigned long ) ubuf, PAGE_SIZE);return ret;static void __exit a3kmod_exit (void ) "[a3kmod:] Goodbye to kernel space!\n" );"GPL v2" );"arttnba3" );
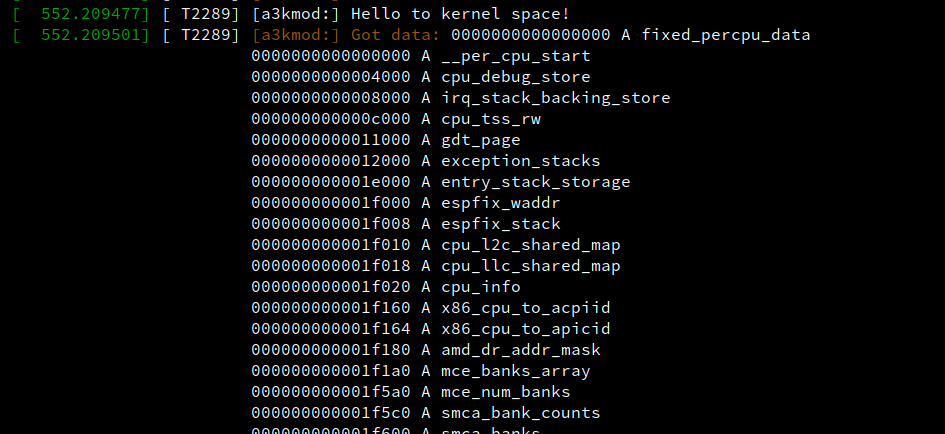
成功读取 /proc/kallsyms 文件:
注意到这里我们读取的数据似乎不太对?这实际上是因为权限不足的缘故(在 sudo insmod 下我们的主体凭证虽然提升到了 root,但是与文件权限相关的客体凭证不与 sudo 相关联,因此在打开文件之前我们需要 在内核中手动进行提权 ,完成读取后再降回原权限(可选)