【VIRT.0x02】系统虚拟化导论
本文最后更新于:2025年3月8日 早上
虚拟化方向YLG速成入门指北
0x00.一切开始之前
因为笔者最近不知道为什么开始做 X86 虚拟化这一块的工作了(大雾),而虚拟化的知识点比较杂也比较乱,所以特地开这一篇博客简单记录一下虚拟化的一些基本概念
0x01. Virtualization Basis
一、虚拟化的基本概念
什么是虚拟化?狭义地说,大家在日常生活中说到的虚拟化主要指的还是 虚拟机 (Virtual Machine),即通过虚拟化技术将一台计算机虚拟为多台逻辑计算机——这其实是虚拟化技术中的一个抽象粒度为单个计算机的分支:系统虚拟化
在计算机科学当中,虚拟化(Virtualization)指的其实是一种「将计算机的各种实体资源进行逻辑抽象,从而呈现出不同的虚拟资源」的资源管理技术。利用虚拟化技术,我们可以打破实体结构间不可切割的特性——一份实体资源可以对用户呈现为多份虚拟资源,多份实体资源也可以呈现为一份物理资源。
通过虚拟化技术,我们可以实现资源的动态分配、灵活调度、跨域共享等,从而提高资源的利用率。
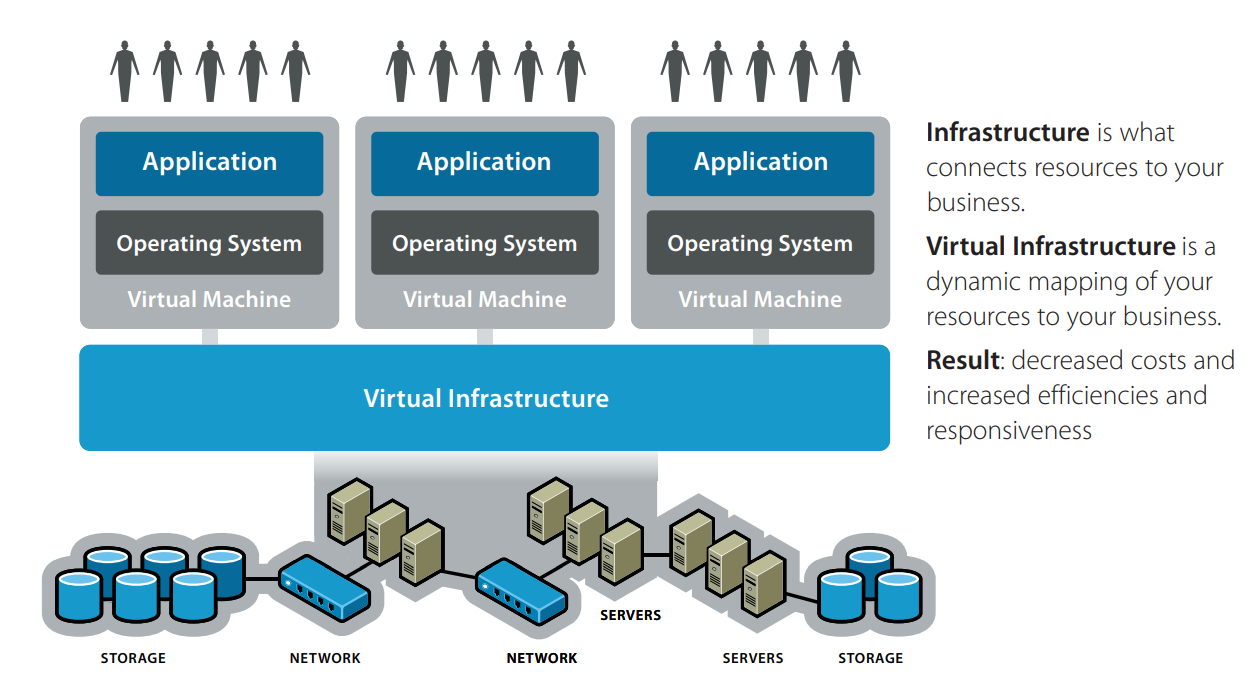
这里所说的实体资源包括CPU、内存、磁盘空间、网络适配器等。
这里笔者摘抄一段来自一本经典的虚拟化技术教材的叙述:
抽象来说,虚拟化是资源的逻辑表示,它不受物理限制的约束。具体来说,虚拟化技术的实现形式是在系统中加入一个虚拟层,虚拟化层将下层的资源抽象成另一形式的资源,提供给上层使用。通过空间上的分割、时间上的分时以及模拟,虚拟化可以将一份资源抽象成多分。反过来,虚拟化也可以将多份资源抽象成一份。
——《系统虚拟化:原理与实现》
即虚拟化技术的实现其实源自于现代计算机系统自下而上的多层抽象的结构:「每个层次都向上一层次呈现一个抽象,每一层只需要知道下层的抽象接口,而无需了解其内部运作机制」——我们不难想到的是,只要我们能够通过某种方式向上层提供表现相同的抽象接口,在上层看来我们就是正常的该层所提供的资源,从而就实现了对该层的虚拟化。
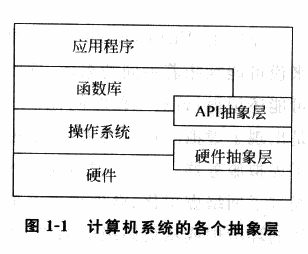
由此,从物理层与虚拟层的两侧来看,我们便有了虚拟化中的两个重要定语:
- 「Host」:物理资源方
- 「Guest」:虚拟资源方
根据资源的不同,在这两个定语之后我们可以接不同的名词:例如我们将一台物理机器称之为 Host Machine (宿主机),将运行在其上的虚拟机称之为 Guest Machine (客户机);相应地,在宿主机上若运行有操作系统,则称之为 Host OS,而运行在虚拟机中的操作系统称之为 Guest OS
由此,我们将位于不同抽象层上的虚拟化分为如下类:
- 硬件抽象层上的虚拟化:通过虚拟硬件抽象层来实现虚拟机器,为 Guest OS 呈现与物理硬件相同或相类似的硬件抽象层,也称之为「系统级虚拟化」(例如VMWare、Xen)
- 操作系统层上的虚拟化:通常指的是操作系统内核可以提供多个互相隔离的用户态实例(通常称之为容器),这些用户态实例对其用户而言就像是一台真实的计算机,有着自己独立的网络、文件系统等(例如 VServer)
- 库函数层上的虚拟化:通过虚拟化操作系统的应用级库函数的服务接口,使得应用程序不需要修改就可以在不同的操作系统中无缝运行(例如 Wine、WSL)
- 编程语言层上的虚拟化:这类虚拟机运行的是进程级别的不存在于硬件上的虚拟体系结构,其程序代码由虚拟机的运行时支持系统翻译成机器语言后再执行,属于进程级的虚拟化(例如 JVM)
例如 Linux kernel 当中的 VFS 便是非常符合虚拟化这一概念的子系统:从上层调用的角度而言,我们所看到的都是统一的 API 接口,不同文件系统的具体实现则被隐藏在了 VFS 层的下方。我们只需要知道在这一抽象层中 open、read、write 等抽象 API 的用法,而无需关注底层的 ext4 或是 ntfs 的内部实现。
虚拟化亦是如此,从 Guest 侧我们所能看到的也只是统一的虚拟资源的接口,或者说 Host 为我们呈现出了虚拟化的资源接口,其表现的行为与实体设备是一致的。
我们日常所说的虚拟化技术主要是硬件抽象层上的虚拟化,即「系统级虚拟化」:通过虚拟化技术将一台计算机虚拟为多台逻辑计算机
针对实体资源类型的不同,我们还可以再细分为:
- 计算虚拟化:针对 CPU 和内存资源进行虚拟化
- 网络虚拟化:针对网络链路资源进行虚拟化
- IO虚拟化:针对 IO 资源进行虚拟化
- 存储虚拟化:针对磁盘存储资源虚拟化
二、虚拟化与云计算
说到虚拟化就不得不提云计算这一“新兴事物”(其实在笔者写下这句话的时候云计算技术已经发展多年了hhh),似乎每次提到云计算总是离不开虚拟化这个词,那先来和笔者一起看一下「什么是云计算吧」(笑)
- 「云计算」(Cloud computing)即通过网络向用户按需提供可动态伸缩的计算服务与 IT 资源,云服务厂商将多份实体资源以一定形式进行整合后,将其称之为「云」,通过互联网按需向用户提供其所需的资源
相信大家已经注意到其相似之处了——虚拟化技术便是云计算服务的技术基石之一
- 通过虚拟化可以解决数据中心(IDC)资源整合的问题,对计算、存储等资源进行标准化
- 通过虚拟化可以将资源进行更为合理的切割调度,从而充分利用硬件资源
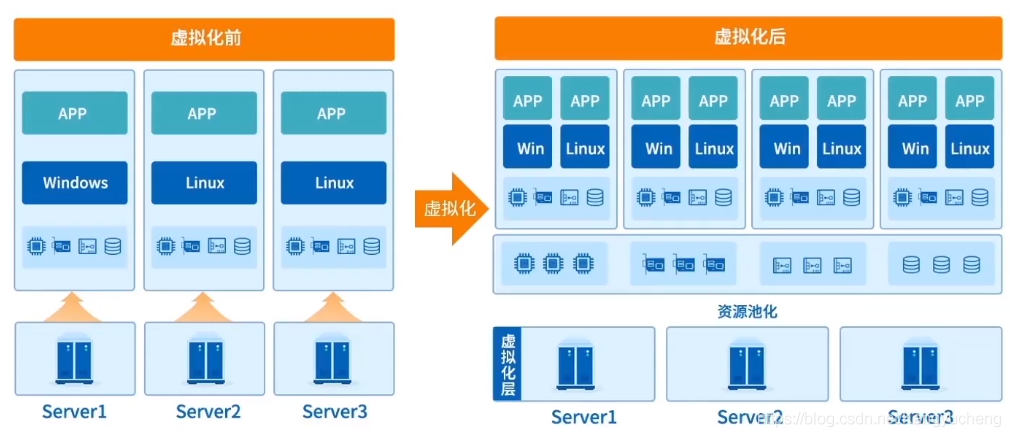
当然云计算的基石不仅仅是虚拟化,但是这篇博客主要讲的还是系统虚拟化而不是云计算(笑)
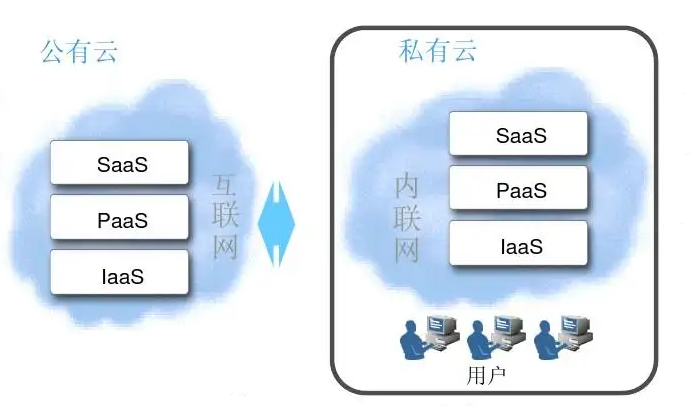
根据提供的资源服务的类型不同,我们将云服务分为以下三种类型:
Infrastructure-as-a-Service(IaaS):云厂商向用户提供完整的基础设施,即提供云硬件环境,包括计算(CPU)、存储(硬盘)、网络等,用户需要自行在云硬件环境上搭建自己需要的服务
通俗点说就是卖服务器(笑)
Platform-as-a-Service(PaaS):云厂商向用户提供软件部署平台,即提供服务器平台或者开发环境,用户可以直接在云平台上进行开发部署等工作,而无需管理底层的基础设施
比如说微软的 Azure 和 Redhat 的 OpenShift
Software-as-a-Service(SaaS):云厂商向用户提供具体的软件服务,用户可以通过网络直接使用厂商提供的服务
比如说腾讯的共享文档就是一个典型的 SaaS
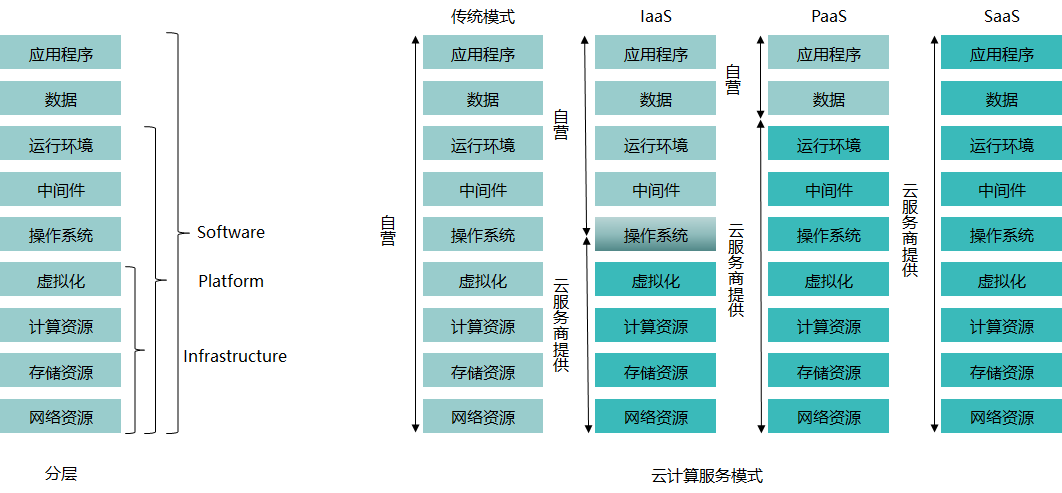
我们按照其部署形式的不同还可以将云分为以下三类:
- 公有云:云服务的基础设施部署在云厂商的机房里,由云厂商向用户提供云上资源,云资源实体由多个用户共享(一台物理服务器上可能跑多个用户的虚拟机)
- 私有云:云服务的基础设施部署在用户自己的机房里(部署在内部自有机房的叫内部私有云,部署在外部托管机房的叫外部私有云),由云厂商提供部署服务或是用户自行部署,云资源实体由用户独享
- 混合云:用户在使用云厂商提供的云资源的同时自己也搭建了一个云
现在网上各种关于云计算的文章包括像百度百科这样的,几乎没有一个能准确给这个概念下一个最基本的定义的,全篇都是各种假大空的套话,看着让人血压升高……
👴觉得百度百科就是个🐓⑧云计算本质上其实就是一个通过互联网向用户按需提供可动态伸缩的 IT 资源,至于用户拿到这个计算资源后要做什么笔者并不关心(笑)
0x02. 系统虚拟化概述
一、基本模型
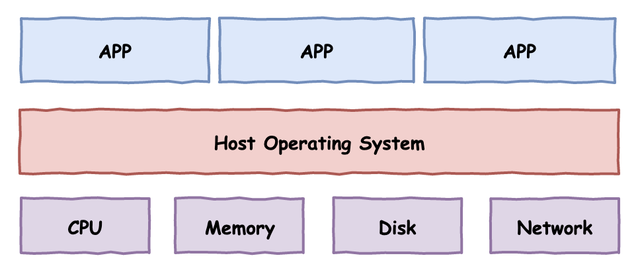
对于一台计算机,我们可以简单地抽象成下图所示的三层模型,从下往上分别是物理硬件层、操作系统层、应用程序层:
我们首先给「虚拟机」下一个定义:
- 虚拟机(Virtual Machine)是计算机的虚拟化实例,拥有自己的虚拟硬件(如 CPU、内存、设备等),可执行与计算机几乎完全相同的功能,包括运行应用和操作系统
即我们可以把一个虚拟机实例看作是一台具有如上图所示层次的逻辑的计算机
但虚拟机的运行是需要有物理环境所支撑的,同时虚拟机实例也是不可能凭空出现/凭空消失的,因此接下来我们引入一个新的概念——VMM,即 Virtual Machine Monitor,又称 Hypervisor,这是一个介于 VM 与硬件中间的软件层,其负责 VM 的创建、销毁等工作,并为 VM 提供了运行环境:「虚拟硬件抽象层」
1974年,Gerald J. Popek 与 Robert P. Goldberg 发表了合作论文《Formal Requirements for Virtualizable Third Generation Architectures》,在论文中提出了满足虚拟化系统结构的 VMM 的三个充分条件,称之为Popek and Goldberg virtualization requirements:
- 等价性(essentially identical):一个运行于 VMM 下的程序,其行为应与直接运行于等价物理机上的同程序的行为完全一致
- 资源控制(resource control):VMM 对虚拟资源具有完全的控制能力,包括资源的分配、监控、回收
- 效率性(efficiency):机器指令中经常使用的那一部分应在没有 VMM 干预下直接在硬件上执行
由此,论文中提出了两种 Hypervisor 方案,这也成为了现在最主流的两种方案:
Type I:Hypervisor 直接运行在硬件上,即以 Hypervisor 作为 Host OS 直接管控硬件资源。例如VMware ESXI便是采用此种架构的 Hypervisor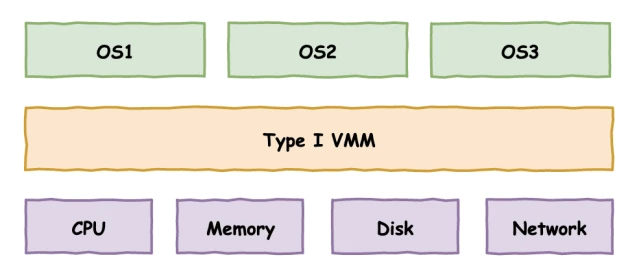
Type II:Hypervisor 运行在传统的操作系统上,与其他应用程序并行运行。例如Qemu与VMware Player便是采用此种架构的 Hypervisor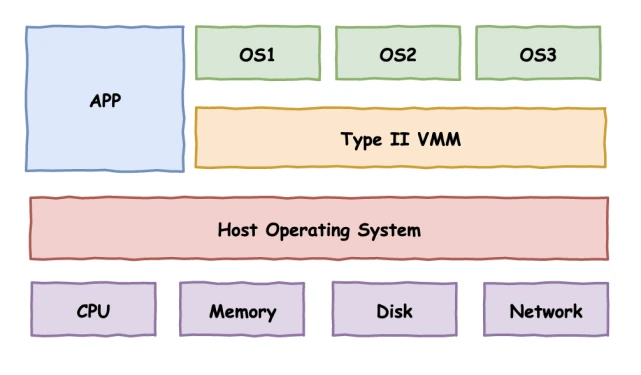
具体到技术细节上,我们应该如何去实现上述的虚拟化方案呢?我们先来介绍一个概念——「敏感指令」,即操作特权资源的指令,例如 IO 操作、修改页表寄存器等
为了我们的 VMM 能够完全地控制系统资源,敏感指令必须在 VMM 的监控审查下完成,或是经由 VMM 来完成。因此,若一个架构中所有的特权指令都是敏感指令,则我们可以使用特权级压缩(Ring Compression)的方式来实现虚拟环境:
- VMM 运行在最高特权级上,Guest VM 运行在低特权级上,当 Guest VM 执行到敏感指令时,其便会陷入位于最高特权级的 VMM,此时便能由 VMM 模拟敏感指令的行为
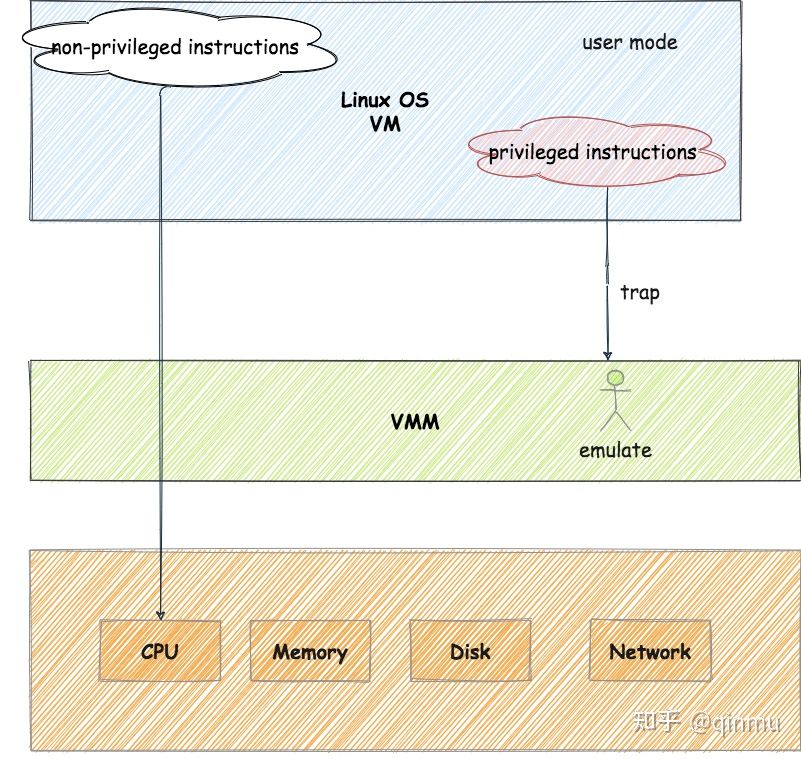
——这就是系统虚拟化最典中典的模型「Trap & Emulate」:
- 我们将操作系统分为两个运行模式:「用户模式(user mode)」与「特权模式(privileged mode)」,在用户模式下只能直接执行非特权指令,当执行到特权指令时便会触发异常,从而陷入特权模式对应的处理代码中
- Guest VM 运行在用户模式下,从而使得普通指令可以直接放在 CPU 上执行,当 Guest VM 执行到敏感指令时,便会触发异常,此时由 VMM 介入并模拟其应有的行为
因此,一个 ISA 是否可以虚拟化,其核心就在于敏感指令是否都是特权指令
而由于硬件实体资源也有着不同的类型,我们将对不同类型实体资源的虚拟化技术分为如下类型:
- CPU 虚拟化
- 内存虚拟化
- I/O 虚拟化
二、遇到的问题
在虚拟化技术的发展初期,在个人计算机领域广泛使用的 x86 架构并没有对虚拟化的经典架构「Trap & Emulate」提供很好的支持,存在着对系统虚拟化的支持缺陷,系统虚拟化并不能直接而有效的实现
Intel 分级保护环将权限分为 ring0~ ring3,其中操作系统内核运行在 ring0 权限而用户进程运行在 ring3 权限
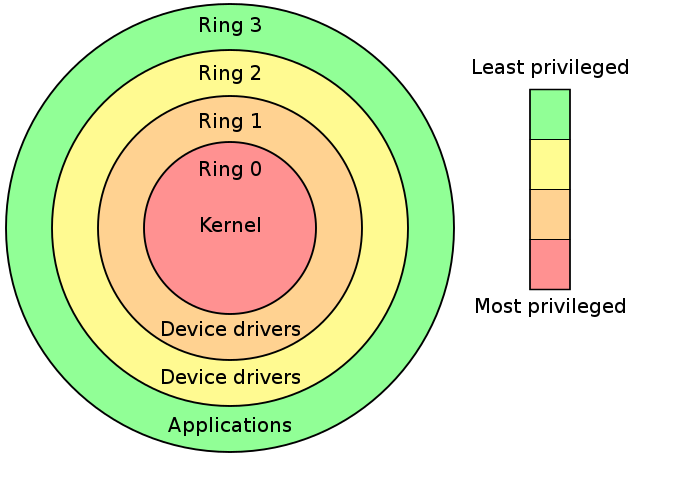
在系统虚拟化的经典架构「Trap & Emulate」中, Guest OS 全部运行在 ring3,当涉及到一些敏感指令时,VM 触发 General Protection 异常,由 VMM 进行截获并处理,但不是所有敏感指令都是特权指令,不是所有的敏感指令都有触发异常以让 VMM 介入的机会, x86 架构中一共有 17 条非特权敏感指令:

这些指令直接违反了 Popek and Goldberg virtualization requirements ,从而使得 x86 不是一个可以虚拟化的架构
例如在 x86 下我们想要用 popf 修改 eflags 的中断开关位(IF)时,若我们在用户态下进行这样的操作,则会直接被硬件所忽视,而不会引起异常,这令 VMM 无法介入
“硬件不够,软件来凑”。因此在硬件还未提供对虚拟化的足够支持之前,Hypervisor 只能从软件层面下功夫,于是出现了两种纯软件虚拟化技术:「模拟执行」(VMWare)与「直接源代码改写」(Xen)
在软件虚拟化技术已经发展成熟多年之后,x86 架构对虚拟化的支持才姗姗来迟:「硬件辅助虚拟化」(Intel VT)开始出现在人们的视野当中
三、实现方案
I.完全虚拟化(Full-virtualization)
完全虚拟化技术提供一个完整的虚拟化硬件环境,允许未经修改的 Guest OS 直接在 VM 上运行,在 Guest OS 的视角,其与运行在真实的物理平台上一般无二
完全虚拟化意味着 Guest OS 会将操作正常的处理器、内存、I/O 设备那样在虚拟化硬件环境中操作,因此这需要 VMM 能够正确处理 Guest OS 所有可能的行为,因此这需要对应的架构满足 Popek and Goldberg virtualization requirements
由于 x86 架构的硬件在最初并没有对虚拟化提供很好的支持,因此完全虚拟化经历了两个阶段:
1)「软件辅助的完全虚拟化」
纯软件实现的完全虚拟化主要依赖两个技术:
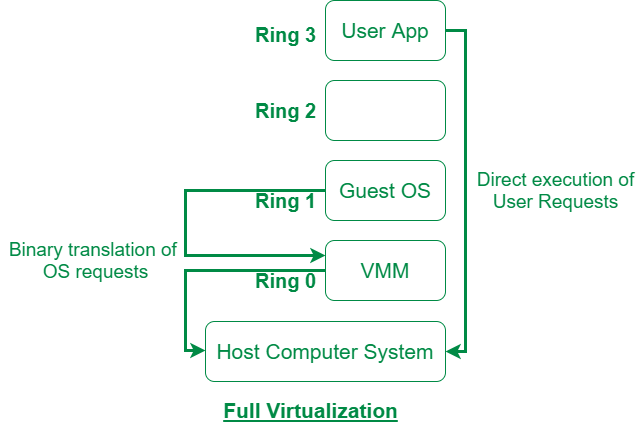
- 「优先级压缩」(Ring Compression):即 VMM 与 GUest VM 运行在不同的特权级上。例如
VMM 运行在 ring0、Guest OS kernel 运行在 ring1、Guest APP 运行在 ring3,当 Guest OS 想要尝试执行特权指令时,便会触发异常,此时 VMM 便能截获该特权指令并进行模拟执行。但正如我们前面所说,不是所有敏感指令都是特权指令,这使得部分敏感指令无法被 VMM 截获并处理,从而导致了虚拟化平台与物理平台表现的行为不一致 - 「二进制代码翻译」(Binary Translation):二进制代码翻译被引入来处理对虚拟化不友好的指令,其思想便是扫描并修改 Guest VM 的二进制代码,将难以虚拟化的指令转化为支持虚拟化的指令(例如显式地触发异常让 VMM 得以介入),对于非敏感指令则仍是直接执行。这在确保了性能的情况下实现了完全虚拟化
VMware 与 Qemu 便都是采用了二进制代码翻译的支持完全虚拟化的虚拟机软件,不过最初的 Qemu 更类似于【解释执行】的模式
虽然在优先级压缩与二进制代码翻译技术的配合下 x86 架构成功地实现了完全虚拟化,但是这种“打补丁”的方式很难在架构上保证完整性,因此 x86 厂商最终在硬件上加入了对虚拟化的支持,从硬件架构层面实现了完全虚拟化
2)「硬件辅助的完全虚拟化」
在纯软件虚拟化技术发展多年后,x86 架构对虚拟化的支持终于姗姗来迟:Intel 与 AMD 分别推出了自家的硬件虚拟化技术 Intel VT 与 AMD-v,在硬件层面添加了对虚拟化的支持,使得 x86 架构终于成为一个符合 Popek and Goldberg virtualization requirements的 ISA(Infrastructure Set Architecture),从而得以实现完全虚拟化
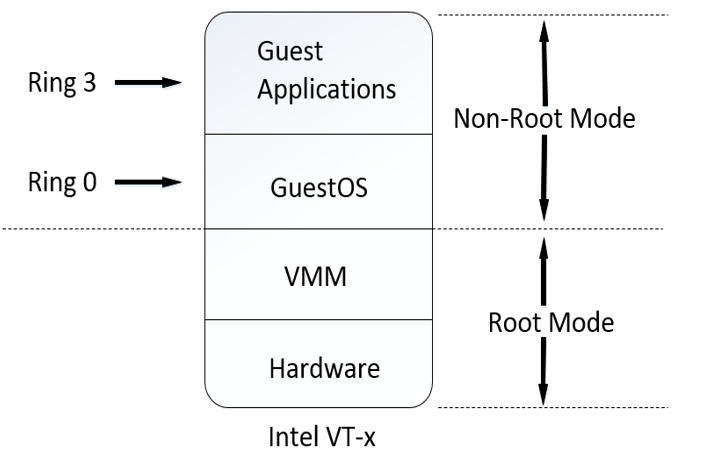
硬件辅助虚拟化本质上是通过在 Guest OS 与硬件中间再添加一个 VMM 中间层来实现的,由硬件负责截获 OS 对敏感指令的执行与对敏感资源的访问,并通过异常的方式报告给 VMM,从而从硬件层面实现了 Popek and Goldberg virtualization requirements
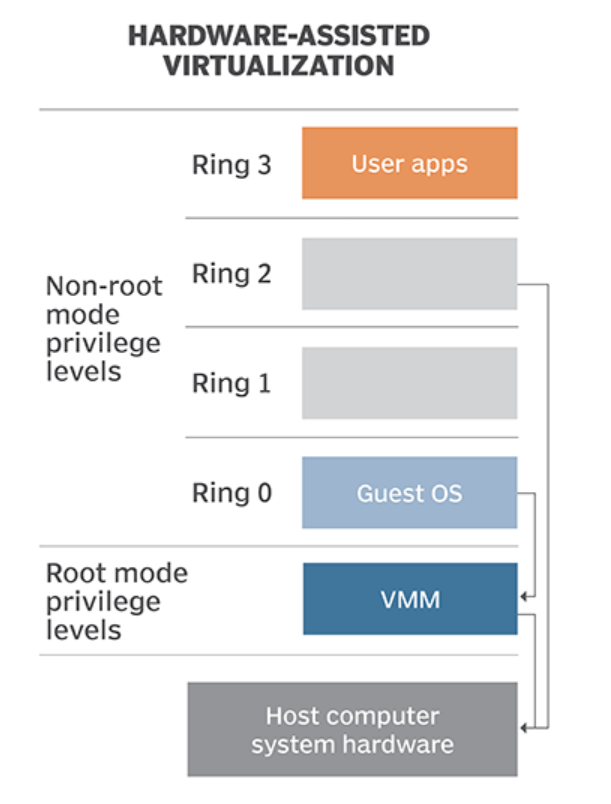
以 Intel VT-x 技术为例,其在硬件架构上将 CPU 的运行模式分为两种:「Non-Root Mode」与「Root Mode」,这两个运行模式都有着各自的分级保护环,其中 Host OS 与 VMM 运行在 Root Mode 下而 Guest OS 则运行在 Non-Root Mode 下
Root Mode 与原有的运行模式一般无二,在 Non-Root Mode下非敏感指令可以直接在硬件上执行,当 Guest OS 运行了敏感指令时,硬件便会捕获到这一行为,切换到 Root Mode 并将之报告给 VMM,由 VMM 处理好后再恢复到 Non-Root Mode 中继续 Guest OS 的运行,这从硬件层面实现了「Trap & Emulate」模型
II.半虚拟化(Para-virtualization)
半虚拟化技术最初的目的也是为了解决 x86 架构无法实现经典虚拟化架构的问题,其通过修改操作系统内核的代码,使得操作系统内核完全避免这些难以虚拟化的指令,从而在 x86 架构下实现虚拟化。在半虚拟化技术中,Guest OS 能够感知到自己运行在虚拟化环境中,当涉及到敏感指令的执行或是对敏感资源的访问时,Guest OS 通过名为 Hypercall 的 API 陷入 VMM 中(通常通过陷阱等方式实现),由 VMM 进行相应的操作后再重新返回 VM 中的 Guest OS 继续执行
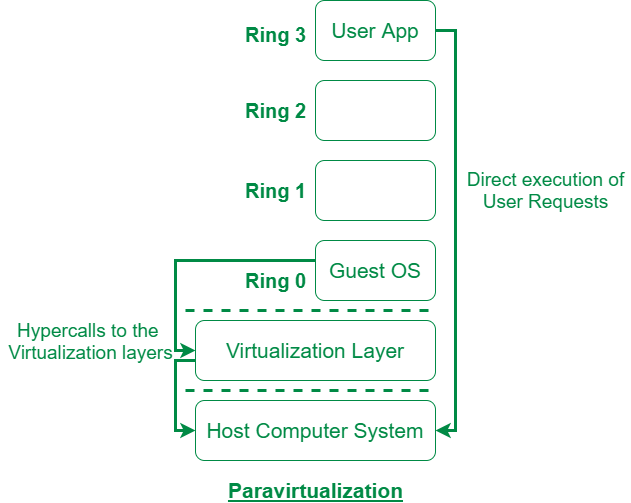
Xen 便是采用了这一模式的虚拟化软件
半虚拟化需要对 OS kernel 的代码进行大量的修改,从而使得其支持半虚拟化技术,因此 Windows 这样的闭源操作系统最初是不支持半虚拟化的
四、libvirt
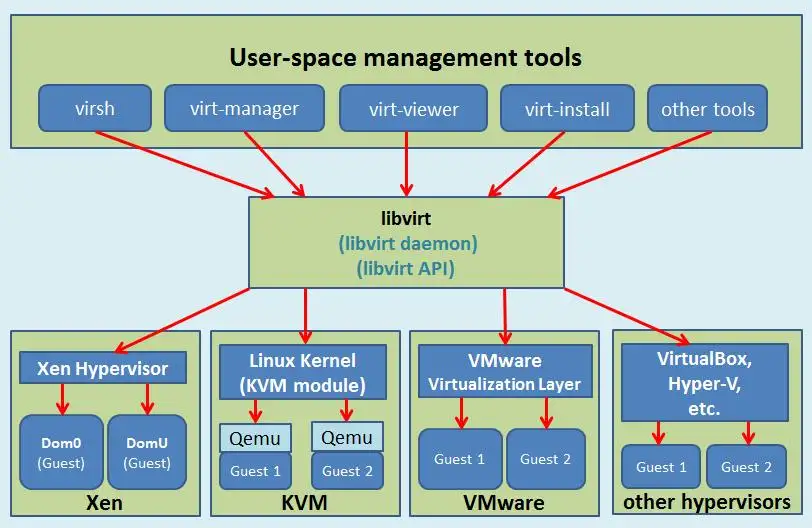
众所周知系统虚拟化平台不止一种(VMWare、Xen、KVM、…),管理起来较为麻烦,因此 libvirt 应运而生
libvirt 是一个专门用于管理虚拟化平台的工具包,其提供了用于管理硬件虚拟化的开源API(libvirt API)、守护进程(libvirtd)与管理工具(virsh),可以用于管理现在主流的大部分 VMM:
0x03. CPU 虚拟化
CPU 虚拟化是系统虚拟化技术中最核心的部分,因为 CPU 是计算机中最核心的组件,直接控制着整个系统的运行,同时内存访问(内存虚拟化)与 I/O 操作(I/O虚拟化)也都直接依赖于 CPU,因此 CPU 虚拟化是系统虚拟化技术中的核心
在 Gerald J. Popek 与 Robert P. Goldberg 的合作论文《Formal Requirements for Virtualizable Third Generation Architectures》 中提出了满足虚拟化系统结构的 VMM 的三个充分条件:等价性,资源控制,效率性。为了满足这个条件, CPU 虚拟化使用的经典模型是「Trap & Emulate」,使用特权级压缩(Ring Compression)的方式来实现虚拟环境:
- Hypervisor 运行在最高特权级上,Guest VM 运行在低特权级上,Guest VM 在硬件上直接执行非敏感指令,当 Guest VM 执行到敏感指令时,其便会陷入位于最高特权级的 Hypervisor ,此时便能由 Hypervisor 模拟敏感指令的行为
- 当发生 virtual CPU 调度时,我们将 vCPU 的状态保存,恢复 Hypervisor 状态,Hypervisor 完成其行为后进行下一 virtual CPU 的调度,恢复下一 vCPU 的状态并恢复执行
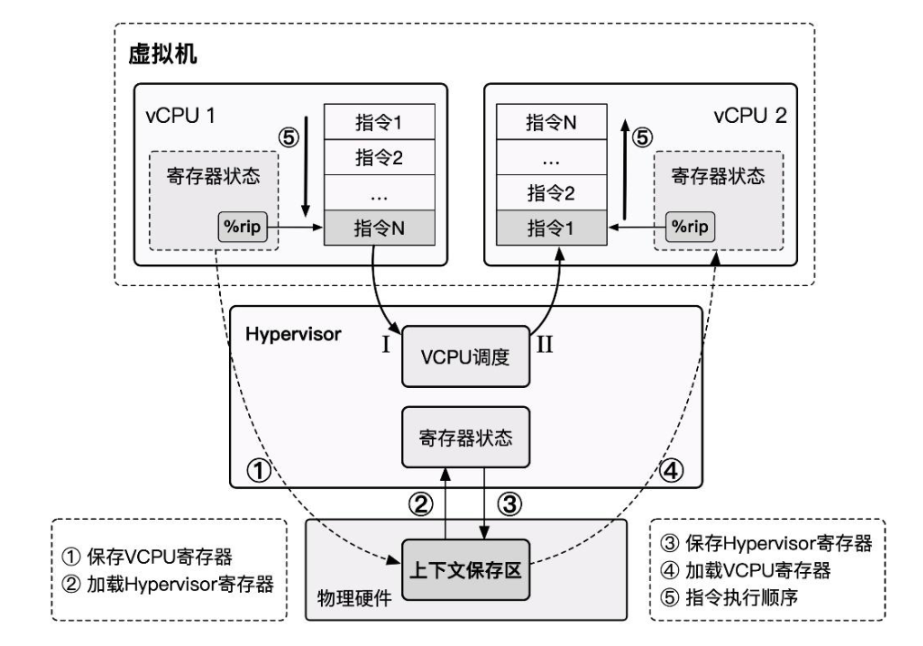
一、纯软件实现虚拟化
前文我们已经指出 x86 架构存在非特权敏感指令,直接导致 VMM 无法截获 x86 VM 的敏感行为,这违反了Popek and Goldberg virtualization requirements,因此在硬件对虚拟化的支持出现之前,虚拟化厂商只好先从软件层面下手
I. 模拟 & 解释执行
「模拟」(Emulate)技术的出现其实早于虚拟化,纯软件的模拟本质上就是通过编写能够呈现出与被模拟对象相同行为的应用程式从而达到运行非同构平台应用程序的效果
模拟技术不仅能够应用于程序级别的模拟,还能应用于系统级别的模拟:CPU 运行的本质行为其实就是从 PC 寄存器所指内存区域中不断取出指令解码执行,我们不难想到的是,实现一个虚拟机最简单粗暴的方法便是通过模拟每一条指令对应的行为,从而使得 VM 的行为对 VMM 而言是完全可控的
例如,对于
mov rax, rbx这样的指令,我们可以使用下面的程序来模拟:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16struct x86_regs{
uint64_t rax;
uint64_t rbx;
uint64_t rcx;
uint64_t rdx;
};
void inline mov_regs(uint64_t *to, uint64_t *from)
{
*to = *from;
}
void inline mov_rax_rbx(struct x86_regs *regs)
{
mov_regs(®s->rax, ®s->rbx);
}
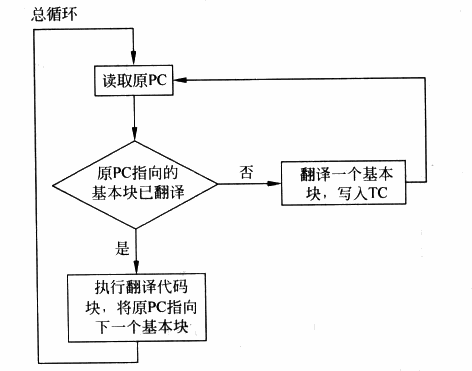
实现模拟技术的原理也是最简单的——我们可以通过「解释执行」的方式来实现模拟技术:
- 模拟器程序不断地从内存中读取指令,并模拟出每一条指令的效果,周而复始
这样,从某种程度而言,每一条指令在执行时都完成了“陷入”,因此我们可以使用模拟技术解决虚拟化的漏洞,同时还能模拟与物理机不同架构的虚拟机
Qemu——Quick Emulator 本质上便是一个模拟器,其完整地模拟了一套包括各种外设在内的计算机系统
例如以下便是笔者实现的一个最最最最简陋的模拟器架构,实际的架构会比这复杂得多:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32struct CPU {
struct regs regs;
};
struct VM{
struct cpu *cpu[];
struct memory *mm;
struct bus *bus;
};
void start_a_new_vm(struct disk *disk)
{
struct VM vm = new_vm("x86", disk);
while (1) {
struct instruction insn;
struct exec_result res;
fetch_next_insn(vm, &insn);
vm_exec_insn(vm, &insn, &res);
switch (res.type) {
case EXIT_VM:
vm_stop(vm);
break;
case RESOURCE_ACCESS:
vm_access_resource(vm, &res);
default:
break;
}
}
}
不过基于解释执行的模拟技术有着一个非常致命的缺点——性能极差,因为每一条指令都需要经过 VMM 的解析后再由 VMM 模拟执行,哪怕最简单的一条指令也可能需要分解成多个步骤与多次内存访问,效率极低
让我们重新审视我们为什么需要在 x86 架构上使用模拟技术来实现虚拟机:非特权敏感指令的存在打破了 Popek and Goldberg virtualization requirements,但非特权敏感指令仅是少数,大部分指令我们仍能直接在物理硬件上运行,因此基于模拟技术进行改进的虚拟化技术出现了:扫描 & 修补 与 二进制翻译
II. 扫描 & 修补
虚拟化场景下的虚拟机大都是与物理机有着相同的 ISA,因此我们并没有必要采用纯模拟的技术实现虚拟机,而是可以让非敏感指令直接在硬件上执行,通过某种方式让非特权敏感指令陷入 VMM,从而重新实现 Trap & Emulate 模型
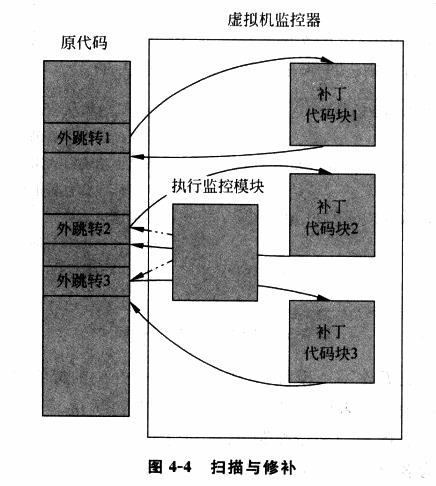
「扫描 & 修补」便是这样的一种技术,其让非敏感指令直接在硬件上执行,同时将系统代码中的敏感指令替换为跳转指令等能陷入 VMM 中的指令,从而让 VM 在执行敏感指令时能陷入 VMM,使得 VMM 能够模拟执行敏感指令的效果
「扫描 & 修补」的基本执行流程如下:
- VMM 在 VM 执行每段代码之前对其进行扫描,解析每一条指令,查找特权与敏感指令
- VMM 动态生成相应指令的补丁代码,并将原敏感指令替换为一个外跳转以陷入 VMM,从而在 VMM 中执行动态生成的补丁代码
- 补丁代码执行结束后,再跳转回 VM 中继续执行下一条代码
例如这是 VirtualBox 中对
cli指令进行模拟的代码:

在「扫描 & 修补」技术当中大部分的代码都可以直接在物理 CPU 上运行,其性能损失较小,但「扫描 & 修补」同样存在着一定的缺陷:
特权指令与敏感指令仍通过模拟执行的方式完成,仍可能造成一定的性能损失
代码补丁当中引入了额外的跳转,这破坏了代码的局部性
局部性原理:CPU存取指令/数据的内存单元应当趋向于聚集在一个较小的区域
VMM 需要维护一份补丁代码对应的原始代码的副本,这造成了额外的开销
III. 二进制翻译
为了进一步地提高虚拟化的性能,「二进制代码翻译」(Binary Translation)技术应运而生,类似于「扫描 & 修补」技术,二进制代码翻译同样会在运行时动态地修改代码,不过不同的是 BT 技术以基本块(只有一个入口和一个出口的代码块)作为翻译的单位:
- Emulator 对读入的二进制代码翻译输出为对应 ISA 的一个不包含特权指令与敏感指令的子集所构成的代码,使其可以在用户态下安全运行
- Emulator 动态地为当前要运行的基本块开辟一块空间,称之为翻译缓存(translation cache),在其中存放着翻译后的代码,每一块 TC 与原代码以某种映射关系(例如哈希表)进行关联
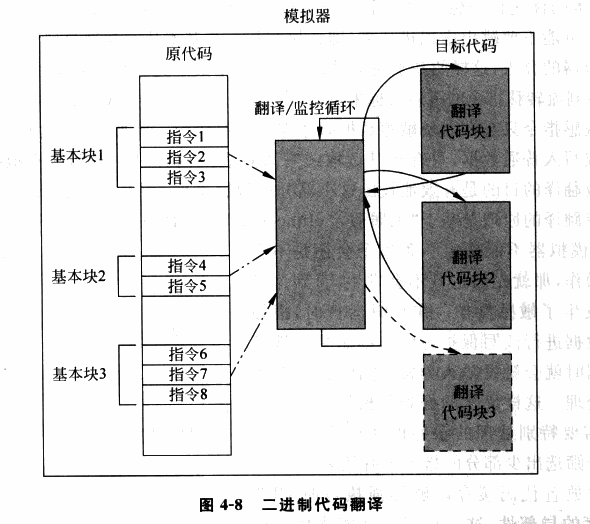
我们可以看出二进制代码翻译技术与扫描修补技术的原理大体上是非常类似的,但是二进制代码翻译技术会对所有的代码进行翻译,而扫描与修补技术则只会 patch 掉敏感指令与特权指令;同时扫描&修补技术不会改变代码的整体结构,而仅是将敏感与特权指令替换为能触发陷入 VMM 的指令,但是二进制代码翻译技术会直接改变一个基本块的代码整体结构(例如翻译前基本块可能长度 40B,翻译后变成100B,内部代码的相对位置也会发生变化)
Emulator 的翻译方法大致分为两类:简单翻译与等值翻译:
- 简单翻译可以直接理解为等效代码模拟。这种方法实现较为简单,但是会让指令数量大幅膨胀
- 等值翻译则是原代码与结果代码相同。理论上大多数指令都可以使用等值翻译直接在硬件上执行,但这需要更复杂的动态分析技术
在相同 ISA 架构上大部分指令都是可以直接进行等值翻译的,除了以下几种:
- PC 相对寻址指令。这类指令的寻址与 PC 相关,但在进行二进制翻译后更改了代码基本块的结构,因此这类指令需要额外插入一些补偿代码来确保寻址的准确,这造成了一定的性能损失
- 直接控制转换。这类指令包括函数调用与跳转指令,其目标地址需要被替换为生成代码的地址
- 间接控制转换。这类指令包括间接调用、返回、间接跳转,其目标地址是在运行时动态得到的,因此我们无法在翻译时确定跳转目标
- 特权指令。对于简单的特权指令可以直接翻译为类似的等值代码(例如 cli 指令可以直接翻译为置 vcpu 的 flags 寄存器的 IF 位为0),但对于稍微复杂一点的指令,则需要进行深度模拟,利用跳转指令陷入 VMM 中,这通常会造成一定的性能开销
例如这是 Qemu 中的一个基本块代码翻译的例子:
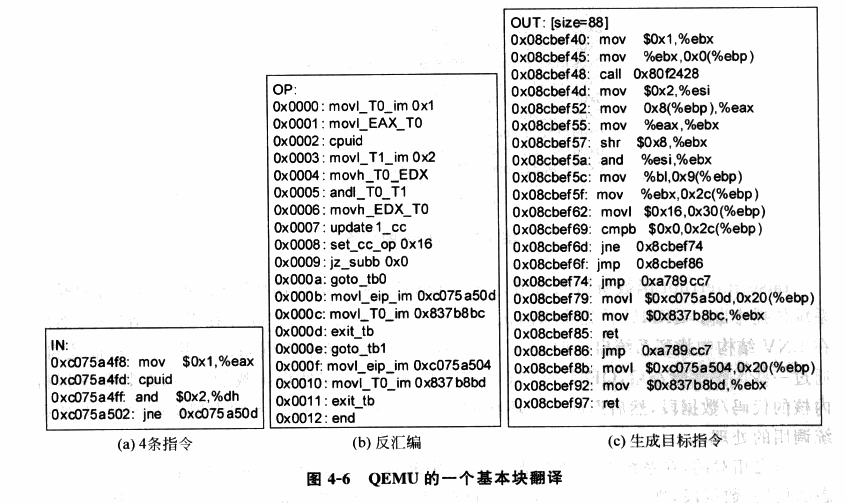
由于二进制代码翻译技术使用了更为复杂的过程,由此也会引入更多的问题,对于以下情形则需要额外的处理:
- 自修改代码(Self Modifying Code)。这类程序会在运行时修改自身所执行的代码,这需要我们的 Emulator 对新生成的代码进行重翻译
- 自参考代码(Self Referential Code)。这类程序会在运行中读取自己的代码段中内容,这需要我们额外进行处理,使其读取原代码段中内容而非翻译后的代码
- 精确异常(Precise Exceptions)。即在翻译代码执行的过程中发生了中断或异常,这需要将运行状态恢复到原代码执行到异常点时的状态,之后再交给 Guest OS 处理。BT 技术暂很难很好地处理这种情况,因为翻译后的代码与原代码已经失去了逐条对应的关系。一个可行的解决方案就是在发生异常时进行回滚,之后重新使用解释执行的方式
- 实时代码。这类代码对于实时性要求较高,在模拟环境下运行会损失时间精确性,目前暂时无法解决
二、硬件辅助虚拟化 - Intel VT-x
听说硬件辅助虚拟化一出来 Xen 就没人用了
I. 概述
Intel VT 技术是 Intel 为 x86 虚拟化所提供的硬件支持,其中用于辅助 CPU 虚拟化的是 Intel VT-x 技术,其扩展了传统的 IA32 处理器架构,为 IA32 架构的 CPU 虚拟化提供了硬件支持
VT-x 技术为 Intel CPU 额外引入了两种运行模式,统称为「VMX 操作模式」(Virtual Machine eXtensions),通过 vmxon 指令开启,这两种运行模式都独立有着自己的分级保护环:
VMX Root Operation:Hypervisor 所工作的模式,在这个模式下可以访问计算机的所有资源,并对 VM 进行调度VMX Non-Root Operation:VM 所工作的模式,在这个模式下仅能访问非敏感资源,对于敏感资源的访问(例如 I/O 操作)会使得 CPU 退出 Non-Root 模式并陷入 Hypervisor 中,由 Hypervisor 处理后再重新进入 Non-Root 模式恢复 VM 的运行
由此,我们对 Root 模式与 Non-Root 模式间的切换行为进行定义:
VM-Entry:Hypervisor 保存自身状态信息,切换到 VMX Non-Root 模式,载入 VM 状态信息,恢复 VM 执行流VM-Exit:VM 运行暂停并保存自身状态信息,切换到 VMX Root 模式,载入 Hypervisor 状态信息,执行相应的处理函数
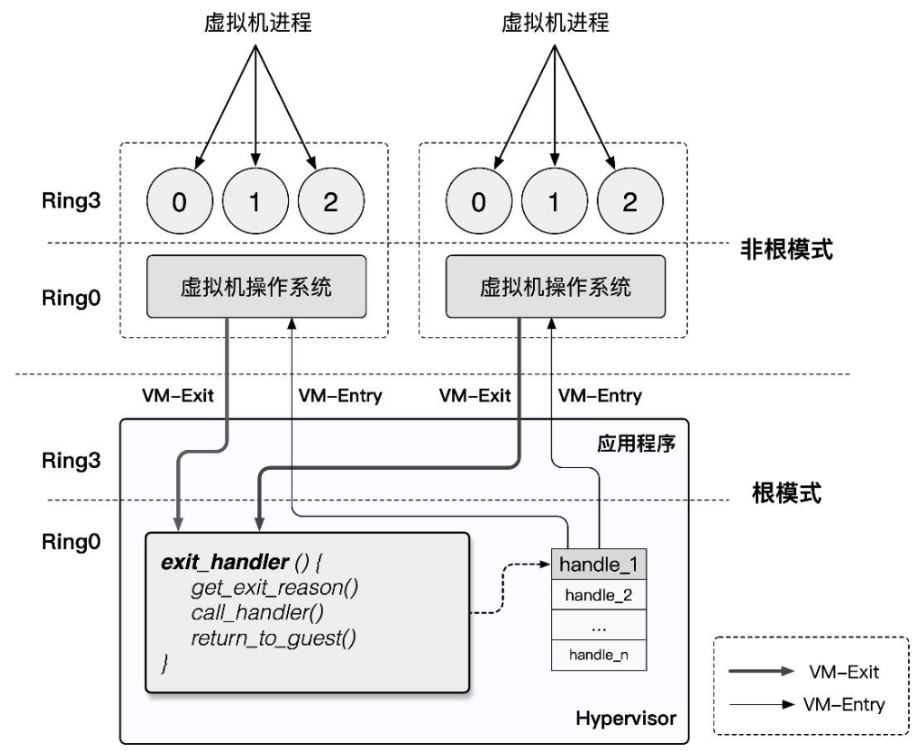
由于 Non-Root 模式与 Root 模式都各自有着自己的分级保护环,因此 Host OS 与 Guest OS 都可以不加修改地在自己对应的模式下直接在硬件上运行,仅有当 Guest OS 涉及到敏感资源的访问及 Host OS 对 VM 的调度时才会发生切换,这在确保了 VM 高性能的同时满足了「Trap & Emulate」模型实现,也解决了 x86 架构的虚拟化漏洞
II. VMCS
在 Intel VT-x 技术引入了VMCS(Virtual-Machine Control Structure),用以保存 CPU 虚拟化所需要的相关状态,每个 virtual CPU 对应有一个 VMCS
VMCS 与物理 CPU 是一一对应的绑定关系,即在同一时刻一个物理 CPU 只能与一个 VMCS 绑定,反之亦然,但在不同的时刻我们可以将 VMCS 绑定到不同的物理 CPU 上,称之为 VMCS 的迁移(Migration)
与 VMCS 的绑定与解绑相关的是以下两条指令:
| Instruction | Description |
|---|---|
| VMPTRLD <VMCS 地址> | 将指定的 VMCS 与执行该指令的 CPU 进行绑定 |
| VMCLEAR | 将执行该指令的 CPU 与其 VMCS 进行解绑 |
VT-x 中将 VMCS 定义为一个最大不超过 4KB 的内存块,且应与 4KB 对齐,其内容格式如下:
来自 Linux kernel
/arch/x86/kvm/vmx/vmcs.h,注释来自笔者
1 | |
VMCS 数据域 存放着 VMCS 主要的信息,分为以下六个子域:
Guest-state area:保存 VM 寄存器状态,在 VM-entry 时加载,在 VM-exit 时保存
Host-state area:保存 Hypervisor 寄存器状态,在 VM-exit 时加载
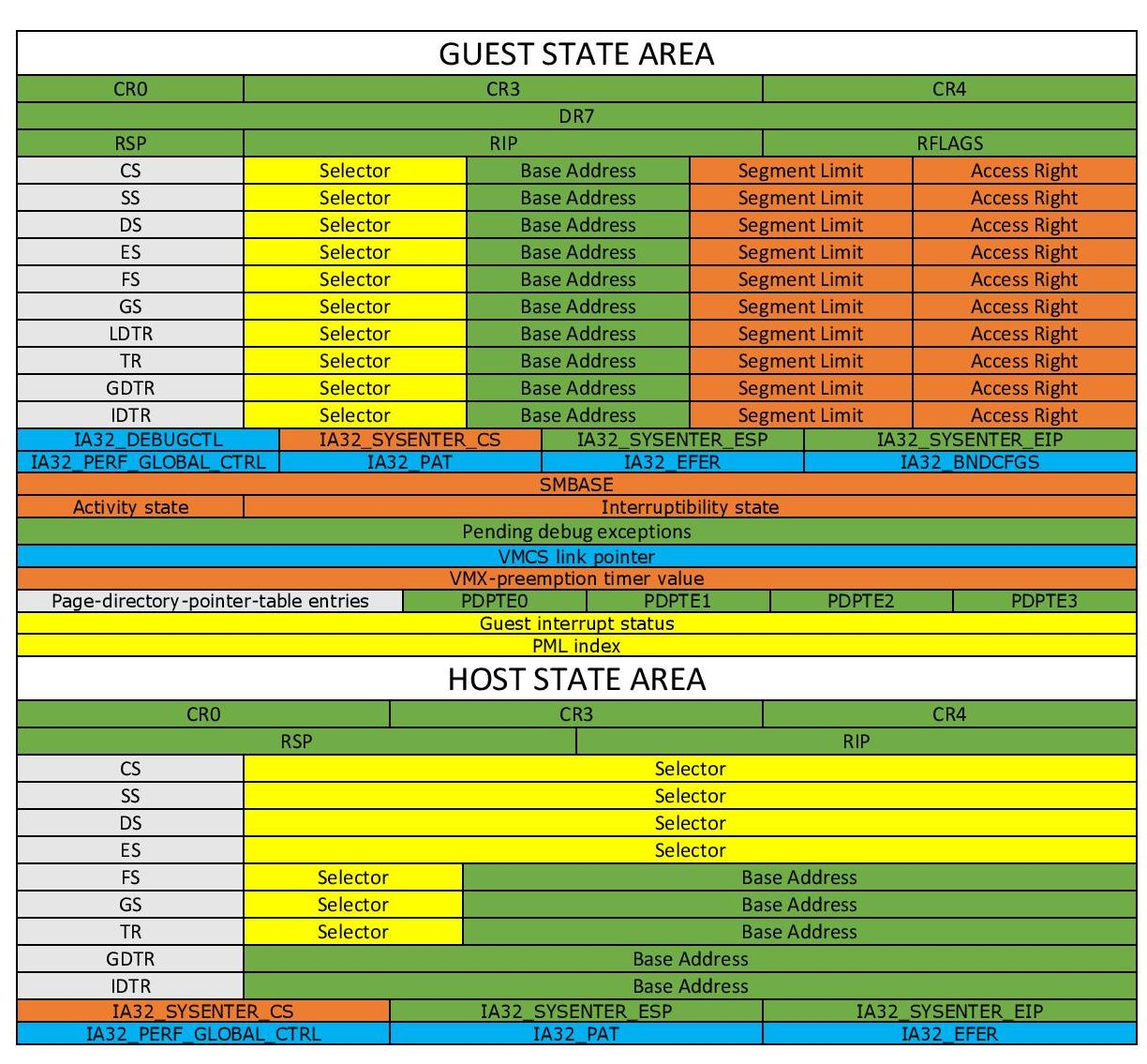
VM-execution control fileds:控制
Non-Root模式下的处理器行为VM-entry control fileds:控制
VM-Entry过程中的某些行为VM-exit control fileds:控制
VM-Exit过程中的某些行为VM-exit information fields:保存
VM-Exit的基本原因及其他详细信息,在一些处理器上该域为只读域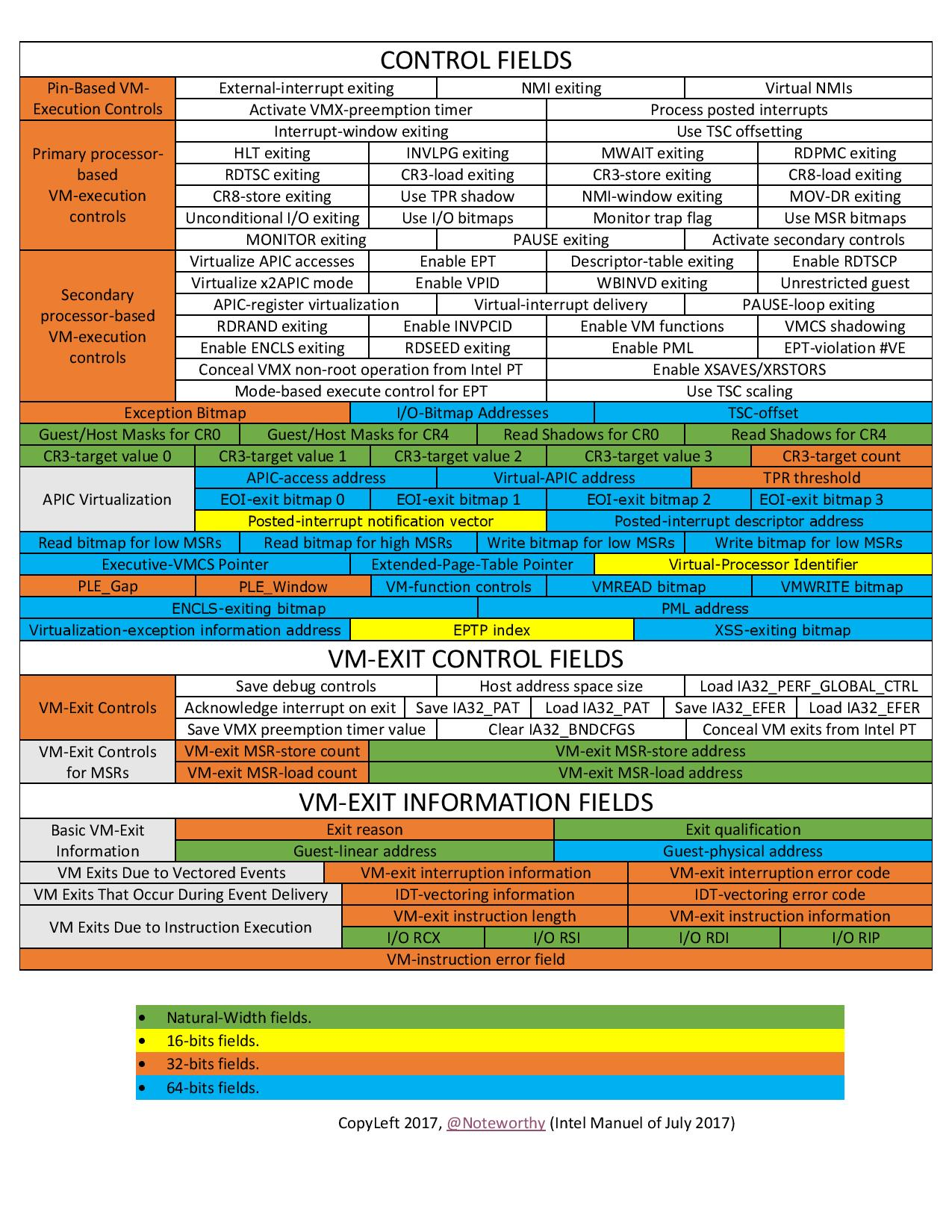
我们通过以下两条指令读写 VMCS:
| Instruction | Description |
|---|---|
| VMREAD <索引> | 读 VMCS 中“索引”指定的域 |
| VMWRITE <索引> <数据> | 向 VMCS 中“索引”指定的域写入数据 |
这里的索引并非偏移值,而是 Intel 为数据域中每个字段都定义了一个独特的索引值,例如 Guest State Area 中 ES 段选择子的索引值便是
0x00000800当然,要把所有域的索引都背下来并不现实,最好的办法还是多多查表:)推荐阅读:Intel SDM 的 Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3C: System Programming Guide, Part 3
III. VMX 操作模式
作为传统的 IA32 架构的扩展,VMX 操作模式在默认下是关闭的,只有当 VMM 需要使用硬件辅助虚拟化功能时才会使用 Intel 提供的两条新指令来开关 VMX 操作模式:
VMXON:开启 VMX 操作模式VMXOFF:关闭 VMX 操作模式
在 Intel SDM 中描述的 VMX 生命周期如下:
- 软件通过
VMXON指令进入 VMX 操作模式 - VMM 可以通过
VM entries进入 Guest VM(单次只能执行一个 VM),VMM 通过VMLAUNCH(第一次进入 VM)与VMRESUME(从 VMM 中恢复到 VM)指令来使能VM entry,通过VM exits重获控制权 VM exits通过 VMM 指定的入口点移交控制权,VMM 对 VM 的退出原因进行响应后通过VM entry返回到 VM 中- 当 VMM 想要停止自身运行并退出 VMX 操作模式时,其通过
VMXOFF指令来完成
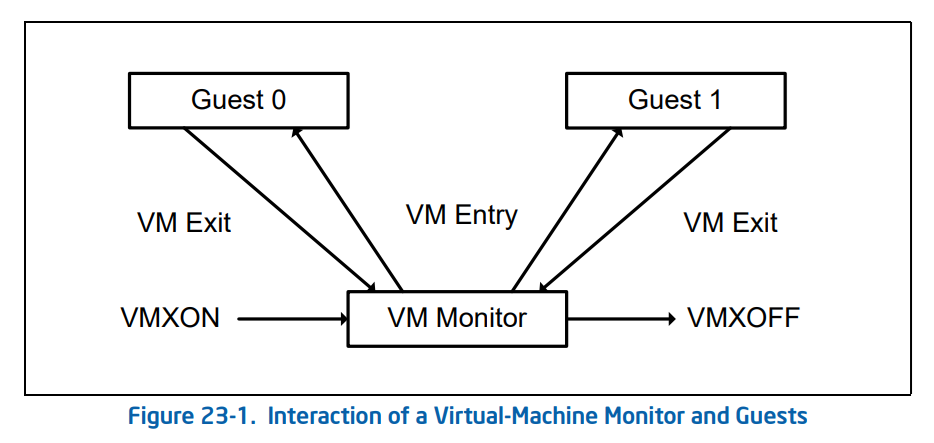
现在我们来深入 VM entry 与 VM exit 这两个行为的实现细节中,在其流程中他们分别进行了如下动作:
- VM entry:从 Hypervisor 切换到 VM
- 检查 VMCS 合法性(各字段值是否合法)
- 加载 VMCS 的
Guest-state area中的各字段到对应的寄存器 - 加载指定的 MSR
- 设置 VMCS 的状态为
launched - 根据需要通过写 VMCS 的
VM-entry Interrucption-Information向 VM 进行事件注入(如异常、异步中断等)
- VM exit:从 VM 切换到 Hypervisor
- 将 VM 退出的原因与详细信息写入 VMCS 的
VM-exit information fields - 将 VM 的寄存器保存至 VMCS 的
Guest-state area - 从 VMCS 的
Host-state area中恢复 Host 寄存器 - 加载指定 MSR
- 将 VM 退出的原因与详细信息写入 VMCS 的
这里笔者为大家补充一个概念:Model Specific Register,简称 MSR,是 x86 下的一组用来控制CPU运行、功能开关、调试、跟踪程序执行、监测CPU性能等方面的寄存器
例如
syscall指令便是通过 MSR 寄存器来获取到内核系统调用的入口点每个 MSR 寄存器都会有一个 id,称之为
MSR Index,我们可以通过这个 id 来利用RDMSR与WRMSR指令读写指定的 MSR 寄存器我们可以在 Intel SDM 的 Volume 4 中获取到到 MSR 寄存器的详细信息
三、KVM & QEMU-KVM
下面我们来介绍 KVM——Kernel-based Virtual Machine,是一个自 Linux 2.6.20 后集成在 kernel 中的一个开源系统虚拟化内核模块,本质上是一个依赖于硬件辅助虚拟化的位于 kernel 中的 Hypervisor,或者说KVM 将 Linux kernel 变成了 Hypervisor,并提供了相应的用户态操作 VM 的接口: /dev/kvm ,我们可以通过 ioctl 指令来操作 KVM
但 KVM 本身仅提供了 CPU 与内存的虚拟化,不能构成一个完整的虚拟化环境,那么我们不难想到的是我们可以复用现有的全虚拟化方案,将模拟 CPU 与内存的工作交由 KVM 完成,这样便能直接通过 KVM 来借助硬件辅助虚拟化以提高虚拟机性能
那么我们有这样的一个现成的完备的全虚拟化实现方案吗?答案是有的——QEMU 本身便完整模拟了一整套虚拟机环境,我们不难想到的是我们可以修改 QEMU 的代码,使其通过 KVM 来创建与运行虚拟机,而设备模拟等依旧复用原有的框架,这样我们就实现了一个高性能的全虚拟化平台:KVM + QEMU
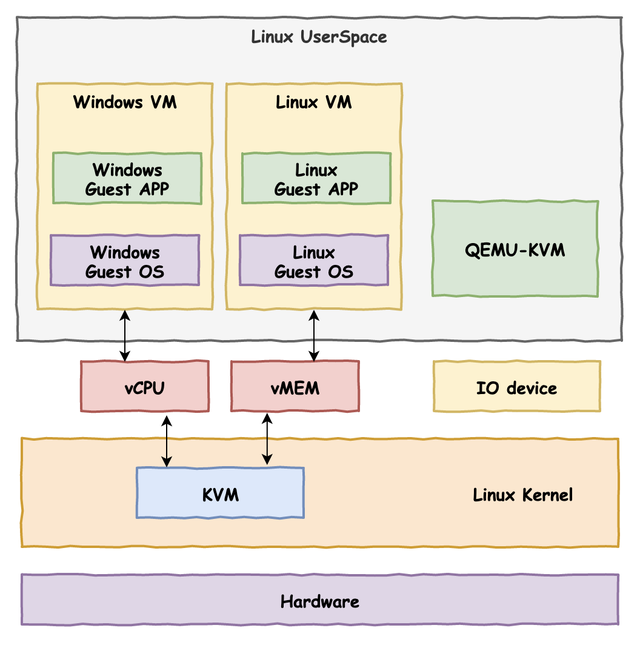
利用QEMU + KVM 进行虚拟化的方案如下:
- QEMU 通过 ioctl 进入内核态将控制权移交 KVM,KVM 进行 VM 的运行
- 产生 VM-Exit,KVM 接管,判断原因并决定继续运行还是交由 QEMU 处理
- 若是后者,恢复到用户态 QEMU 中的处理代码进行相应的处理,之后退出或回到第一步
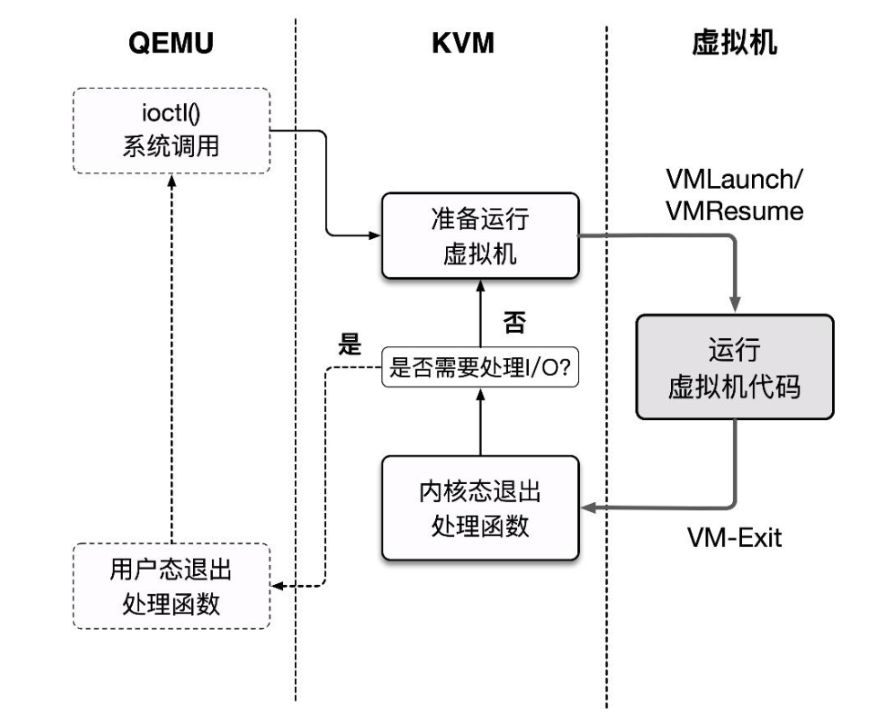
这个基本执行框架实际上为 QEMU 源码 accel/kvm/kvm-all.c 中的 kvm_cpu_exec():
1 | |
0x04.中断虚拟化
中断(Interrupt)机制是一种用来通知 CPU 发生了需要处理的事件的机制,按照发生的位置分为外部中断(来自外部的中断,INTR 引脚传来的为可屏蔽中断,NMI 引脚传来的为不可屏蔽中断)与内部中断(软中断、异常、陷阱等),实模式下 CPU 根据中断向量表来寻找对应的处理程序,保护模式下则通过中断描述符表来寻找处理程序
现代 X86 处理器使用的中断控制器称之为 APIC(Advanced Programmable Interrupt Controller),所有的核心共用一个 I/O APIC ,用于接收外部中断,同时每个核独立有着一个 Local APIC,用于接收来自 I/O APIC 的中断信息、内部时钟中断、来自其他核心的中断(Inter-Processor Interrupt,IPI)等
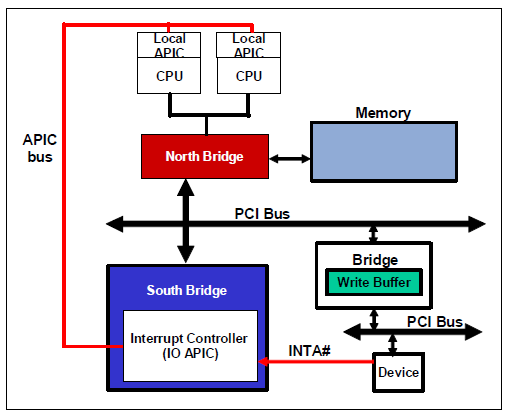
在虚拟化环境当中,每个 vCPU 都对应需要有一个 virtual LAPIC,所有的核心则需要共享一个 virtual I/O APIC,这都是需要 Hypervisor 进行模拟与维护的
一、基本模型
0x05. 内存虚拟化
内存虚拟化本质上是需要达成以下两个目的:
- 提供一个在 Guest 感知中的从零开始的连续物理内存空间
- 在各个 VM 之间进行有效的隔离、调度、共享内存资源
一、纯软件实现虚拟化
I.虚拟机内存访问原理及遇到的问题
为了实现内存空间的隔离,Hypervisor 需要为 Guest VM 准备一层新的地址空间:Guest Physical Address Space,从 Guest 侧其只能看到这一层地址空间,Hypervisor 需要记录从 GPA 到 HVA 之间的转换关系
下图为 Qemu 的内存架构:
1 | |
当我们要访问 Guest 中某个虚拟地址上的数据时,我们需要:
- 首先得先通过 Guest 的页表将
Guest Virtual Address(GVA)转换为Guest Physical Address(GPA) - GPA 在 Qemu 的实现当中实际上是对应映射到 Host 中一大块 mmap 的内存上的,所以我们还需要将 GPA 再转换为
Host Virtual Address(HVA) - 最后再通过 Host 上的页表将 HVA 转化为
Host Physical Address(HPA) - 在 Guest 多级页表的寻址当中同样也要多次经过
GPA->HPA的转换查询过程
这一整套流程非常繁重,从而使得虚拟机中内存访问的性能极为低下
在 QEMU 当中访问内存的核心函数是
address_space_rw(),感兴趣的同学可以看一下其内部实现,虽然说只是 GPA->HVA(笑)
II.影子页表 (shadow page table)
在早期的时候 Intel 硬件对虚拟化并没有很好的支持,因此 Hypervisor 只能先在软件层面进行优化——影子页表(Shadow Page Table)应运而生
以 Intel 为例,由于读写 CR3 寄存器(存放页顶级表指针)的操作是敏感指令,我们的 Hypervisor 可以很轻易地截获 VM 的这个操作,并将页表替换为存放 GVA→HPA 映射关系的影子页表,这样就能直接完成由 GVA 到 HPA 的转换过程
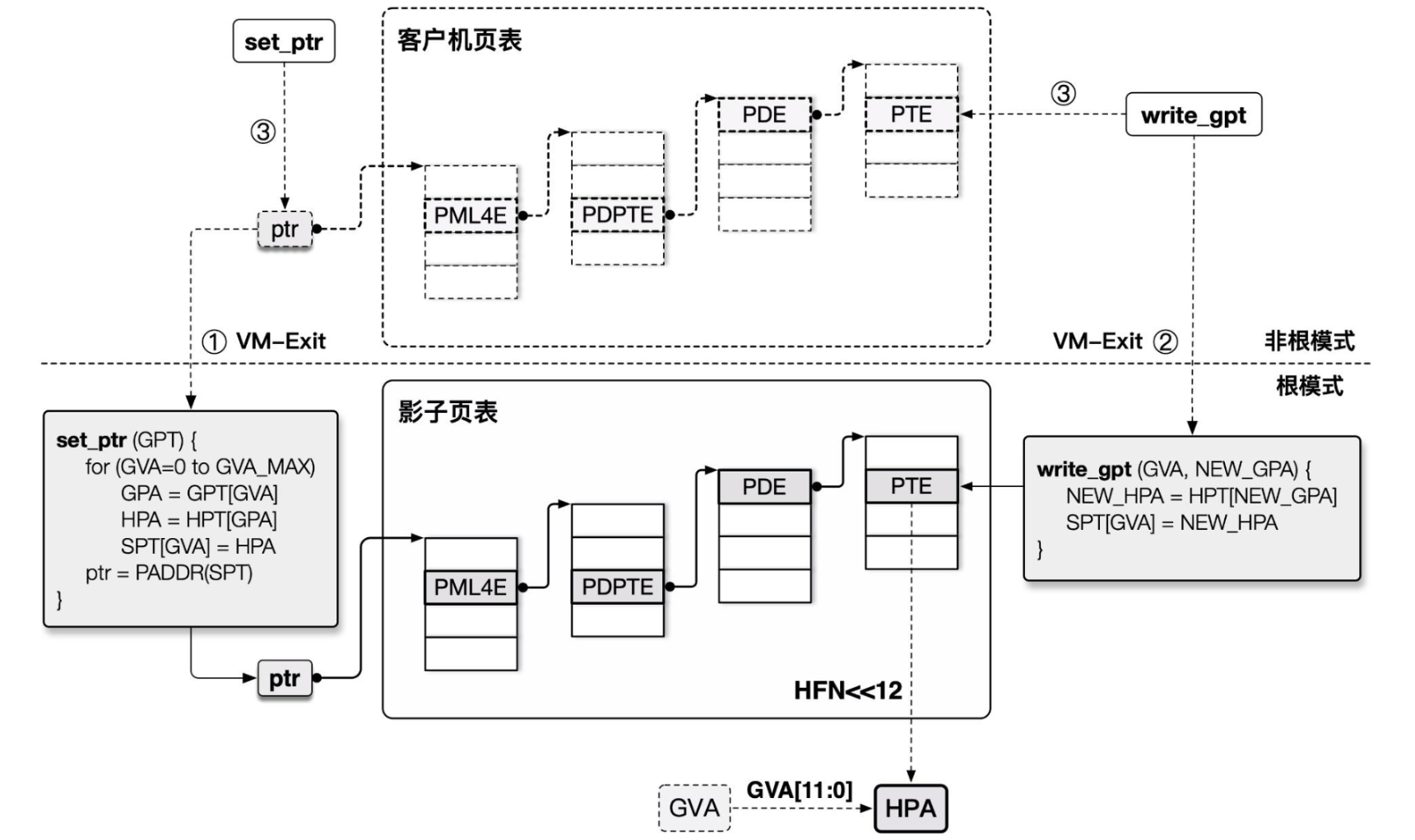
为了实现影子页表,我们本质上需要实现MMU 虚拟化:
- Guest VM 所能看到与操作的实际都上是虚拟的 MMU,真正载入 MMU 的页表是由 Hypevisor 完成翻译后所产生的影子页表
- 影子页表中的访问权限为只读的,当 Guest 想要读写页表时便能被 Hypervisor 捕获到这个操作并代为处理
不过这种方法的缺点就是我们需要为 Guest VM 中的每套页表都独立维护一份影子页表,且需要多次在 VMM 与 VM 间进行切换,这具有一定的开销
二、硬件辅助虚拟化
III.扩展页表(Extend Page Table, EPT)
从软件层面似乎已经是难以有更好的优化的方案了,因此硬件层面的对内存虚拟化的支持便应运而生——EPT 即 Extend Page Table,是 Intel 为实现内存虚拟化而新增的特性,目的是为了减少内存访问的开销
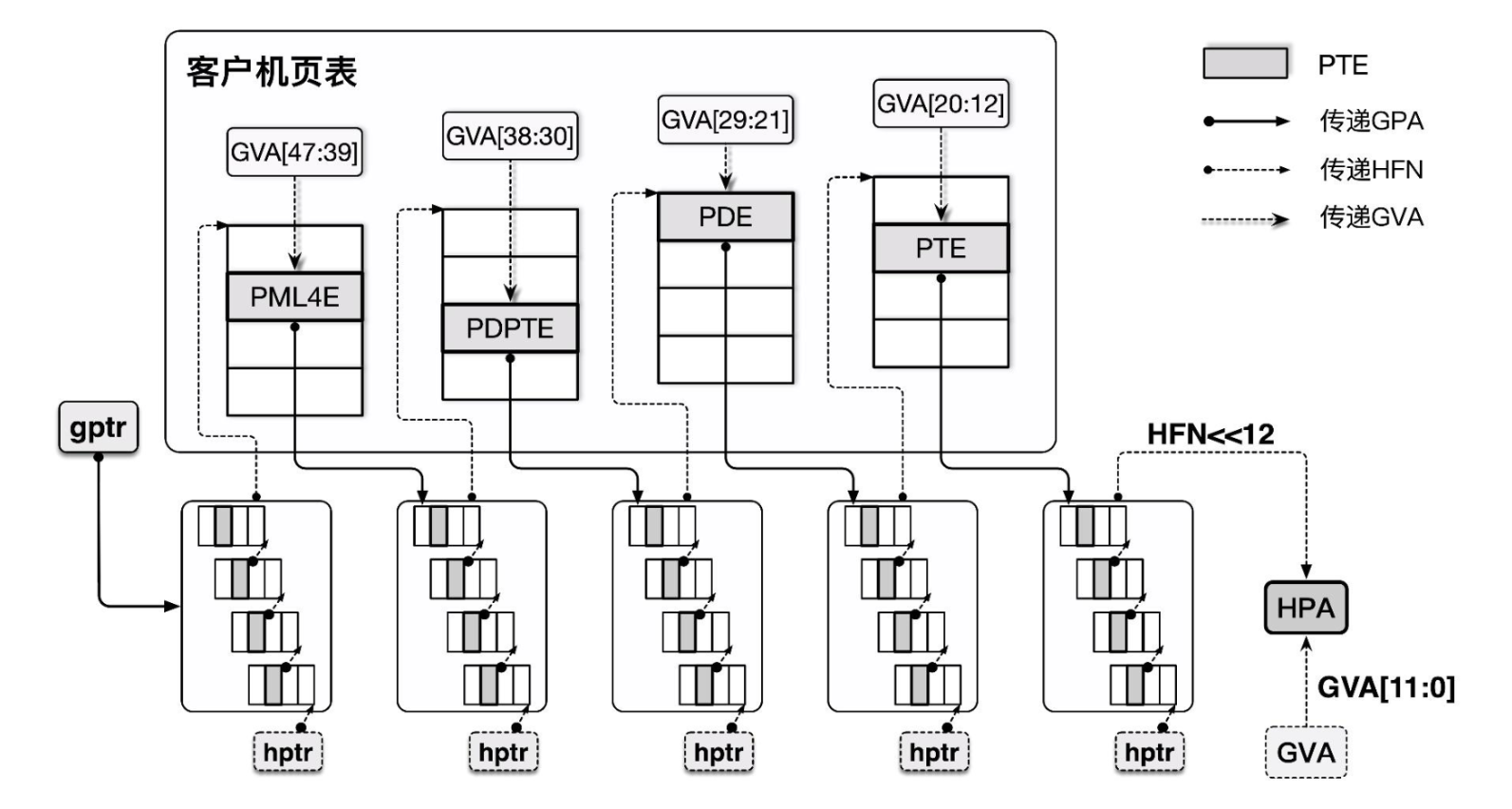
EPT 并不干扰 Guest VM 操作自身页表的过程,其本质上是额外提供了一个 Guest 物理地址空间到 Host 物理地址空间转换的页表,即使用一个额外的页表来完成 GPA→HPA 的转换
EPT 方案虽然相比起影子页表而言多了一层转换,但是并不需要干扰 Guest 原有的页表管理,GVA→GPA→HPA 的过程都由硬件自动完成,同时 Hypervisor 仅需要截获 EPT Violation 异常(EPT 表项为空),效率提高了不少
IV. VPID:TLB 资源优化
Translation Lookaside Buffer为用以加快虚拟地址到物理地址转换的页表项缓存,当进行地址转换时 CPU 首先会先查询 TLB,TLB 根据虚拟地址查找是否存在对应的 cache,若 cache miss 了才会查询页表
由于 TLB 是与对应的页表进行工作的,因此在切换页表时 TLB 原有的内容就失效了,此时我们应当使用 INVLPG 使 TLB 失效,类似地,在 VM-Entry 与 VM-Exit 时 CPU 都会强制让 TLB 失效,但这么做仍存在一定的性能损耗
Virtual Processor Identifier(VPID)则是一种硬件级的对 TLB 资源管理的优化,其在硬件上为每个 TLB 表项打上一个 VPID 标识(VMM 为每个 vCPU 分配一个唯一的 VPID,存放在 VMCS 中,逻辑 CPU 的 VPID 为 0),在 CPU 查找 TLB cache 时会先比对 VPID,这样我们就无需在每次进行 VM entry/exit 时刷掉所有的 cache,而可以继续复用之前保留的 cache
0x06. I/O 虚拟化
现实的外设资源往往是有限的,同时我们有的时候并不需要让 VM 直接接触到现实存在的外设资源,有的时候我们还想为 VM 提供一些不存在实体设备的设备,因此 Hypervisor 需要通过 IO 虚拟化的方式来为 VM 提供虚拟的设备资源
从处理器的角度而言,我们与外设之间的交互主要是通过 MMIO 与 Port IO 来完成的,因而针对外设的虚拟化称之为 I/O 虚拟化
I/O 虚拟化需要实现以下三个任务:
- 访问截获:Hypervisor 需要截获 VM 对外设的访问操作
- 提供设备接口:Hypervisor 需要为 VM 提供虚拟/直通设备的接口
- 实现设备功能:Hypervisor 需要实现虚拟设备的功能
一、I/O 虚拟化基本模型
这一节其实是笔者不记得不知道什么时候出于什么目的从https://developer.ibm.com/tutorials/l-pci-passthrough/上翻译了一段存在草稿箱里,最近翻草稿箱发现之前居然还留存有这种东西,所以修改一下就放上来了XD
I.平台设备模拟(Platform device emulation)
QEMU 和 VMWare 都选择了仿真出一个虚拟设备,不同在于其模拟设备的实现方式。
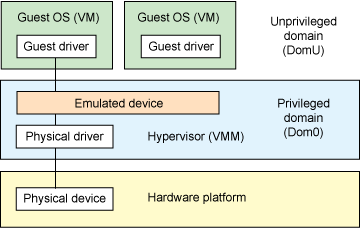
基于虚拟机管理程序的设备模拟(Hypervisor-based device emulation)
在 hypervisor (虚拟机管理程序)中对设备进行仿真是 VMware workstation 系列产品较为常用的一种方式:在 hypervisor 中有着对一般设备的仿真供 guest OS 进行共享,包括虚拟磁盘、虚拟网络适配器与其他的必要元素,这种模型如下图所示:
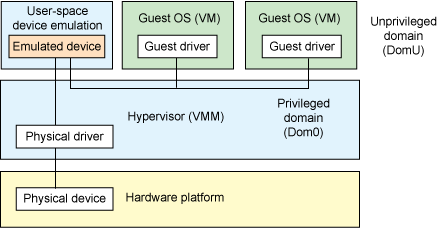
在用户空间进行设备模拟(User space device emulation)
第二种架构称为用户空间设备模拟,正如其名,相比于在 hypervisor 中进行模拟,其选择了在用户空间进行模拟的方式。QEMU(不仅提供了设备模拟同时还有一个 hypervisor)在用户空间中独立模拟了一个设备,该模拟设备被其他的 VM 通过 hypervisor 提供的接口进行调用。由于设备的模拟是独立于 hypervisor 的,因此我们可以模拟任何设备,且该模拟设备可以在其他 hypervisor 间进行共享。
II.设备直通(Device passthrough)
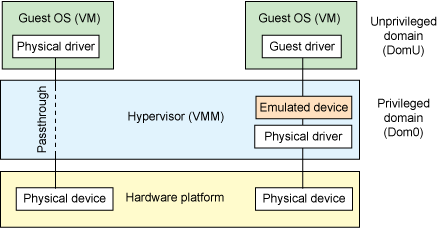
上面的这两种模型或多或少都存在着一定的性能开销,如果该设备需要被多个 VM 共享,那这种开销或许是值得的,但如果该设备并不需要共享,那么我们其实可以使用一种更为高效的方法——设备直通(Device passthrough)。
通过虚拟机管理程序进行直通(Passthrough within the hypervisor)
设备直通可以理解为设备独占的设备模拟:直接将设备隔离给到指定的 VM 上,以便该设备可以由该 VM 独占使用。这提供了接近于原生设备的性能,例如对于一些需要大量 IO 的设备(例如网络设备等),使用设备直通能提供相当完美的性能。
下图左半部分便为设备直通
二、软件半虚拟化 - virtio
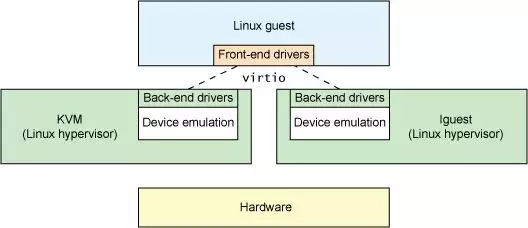
virtio 这个概念来自于一篇非常古老的虚拟化领域的论文:virtio: towards a de-facto standard for virtual I/O devices,主要是为了解决设备虚拟化的问题而提供了一套通用的虚拟化设备模型,Guest OS 只需要实现一套统一的 virtio 驱动便能以统一的方式访问虚拟化设备,从而避免了各种虚拟化驱动分裂的问题
I. VirtQueue:传输层抽象
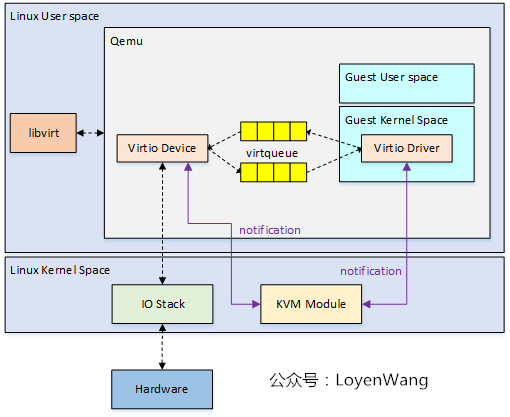
virtqueue 为 virtio 中用以进行数据传输的关键结构,其本身表示一个数据队列:由一方向队列中添加 buffer,另一方从队列中取出 buffer——通过这样的方式实现了 Guest 与 Host 之间基本的数据传输模型
为了减少模型的复杂性,通常我们使用 virtqueue 的传输都是单向的,因此一个最简单的模型就是我们就可以使用两个 virtqueue 来实现 Guest 与 Host 之间的双向通信:tx queue(发送队列) & rx queue(接收队列)
对于 virtqueue 的操作,在论文中抽象成一个函数表 virtqueue_ops:
1 | |
add_buf:向 virtqueue 中添加一个 bufferkick:通知另一方新到达了一个 bufferget_buf从 virtqueue 中获取一个 bufferdisable_cb:通知另一方关闭 buffer 到达的提示enable_cb:通知另一方开启 buffer 到达的提示
II. VRing:virtqueue 的基本结构
virtqueue 核心的数据结构便是 vring,这是一个环形缓冲区队列,其由三部分组成:
- 描述符表(Desc)
- 可用描述符数组(Avail)
- 已用描述符数组(Used)
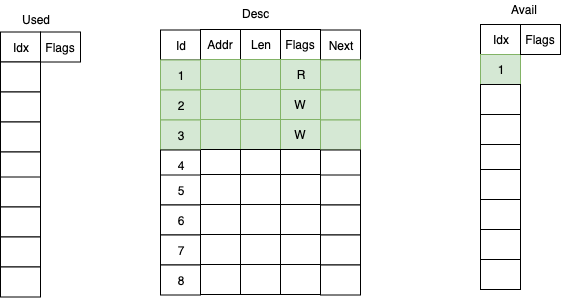
一个描述符(Descriptor)为如下结构,表示了一块 buffer 的基本属性,需要注意的是一个 Avail/Used 表项通常是多个 descriptor 串联的 buffer——这便是 next 域的作用:
1 | |
Avail 数组用来存储当前可用的描述符:
1 | |
Used 数组则用来存储已经被使用的描述符:
1 | |
Avail 数组与 Used 数组同样是一个环形队列,不过这两个数组分别由通信的两方进行使用:
- 数据发送方准备好数据后从
Avail 队列中获取可用的表项,更新描述符表,并在Used 队列中插入新的表项,通知接收方有数据到达 - 数据接收方从
Used 队列中取出表项,读取描述符表以获取数据,完成处理后将表项插入到Avail 队列中
下图为由 Guest 向 Host 发送数据的一个 vring 示例:
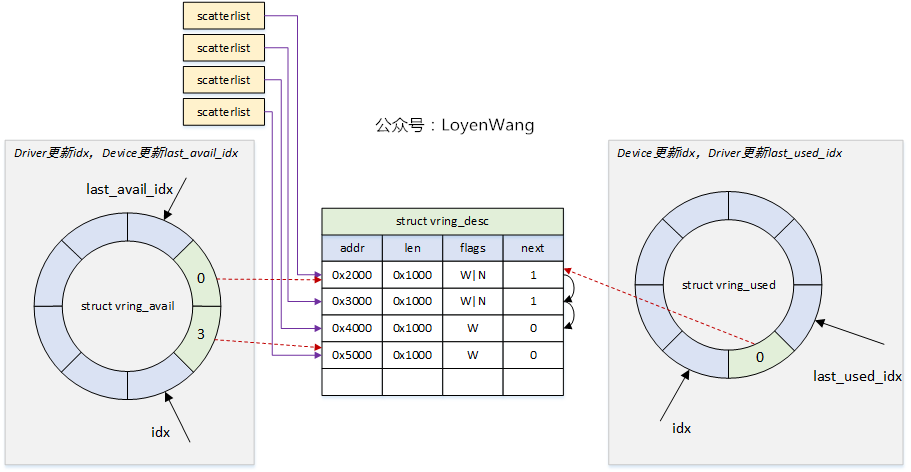
III. virtio 配置操作抽象
结合 virtqueue,我们现在可以抽象出一个虚拟 PCI 设备的基本操作:
- 获取 feature bits
- 读写配置空间
- 读写 status bits
- 设备重置
- 创建/销毁 virtqueue
我们将其抽象成一张函数表:virtio_config_ops
1 | |
feature:获取设备对应的 feature bitget & set:读写设备的配置空间get_status & set_status:读写设备的 status bitsreset:重置设备find_vq:获取/创建 virtqueuedel_vq:销毁 virtqueue
三、IOMMU
可以直接参见 Intel 的手册
IOMMU 即 Input/Output Memory Management Unit,其功能类似于 CPU 中的 MMU,是一个向设备侧提供地址翻译功能的单元
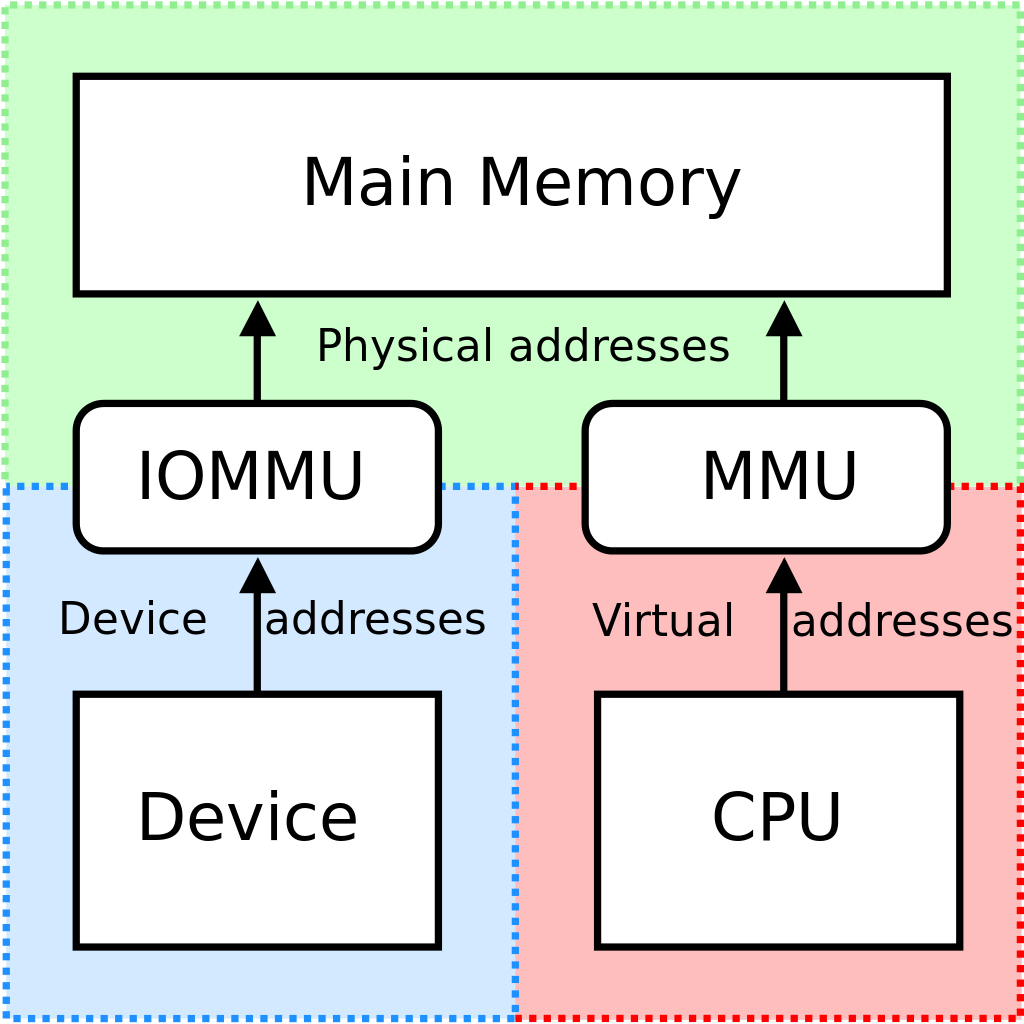
IOMMU 通常被集成于北桥中,其提供面向设备端的两个功能:
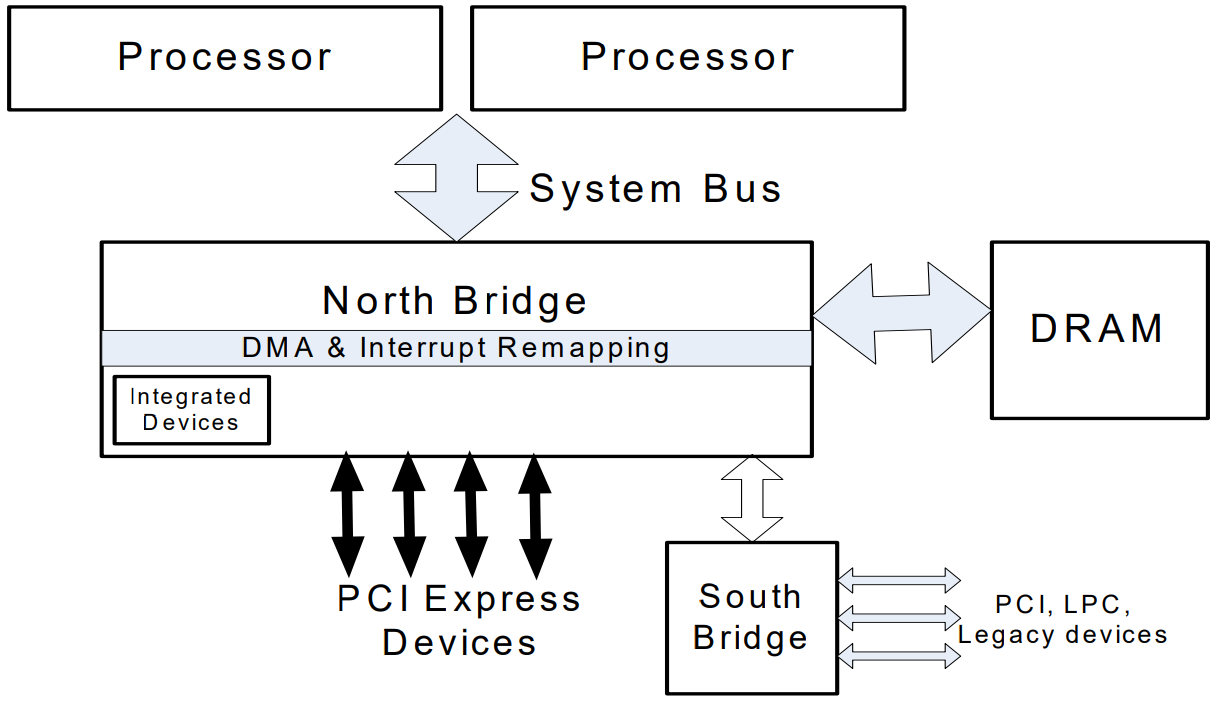
- DMA 重映射( DMA remapping):有着 DMA 功能的设备可以使用虚拟地址,通过 IOMMU 转换为物理地址进行直接内存访问
- 中断重映射(Interrupt remapping):IOMMU 会拦截设备产生的中断,根据中断重映射表产生新的中断请求发送给 LAPIC
I. DMA 重映射
DMA 重映射即面向设备侧的地址访问重翻译,如下图所示,左侧是 CPU 对内存的虚拟化:MMU 利用进程页表将进程要访问的虚拟地址翻译为物理地址,从而实现在两个进程中访问同一个虚拟地址实际上访问到不同的物理地址——DMA 重映射也是类似的原理,如下图右侧所示,当外设想要进行 DMA 时,IOMMU 会根据“设备页表”进行地址翻译,从而使得两个设备各自感知访问的是同一个地址,但实际上访问到了不同的物理地址
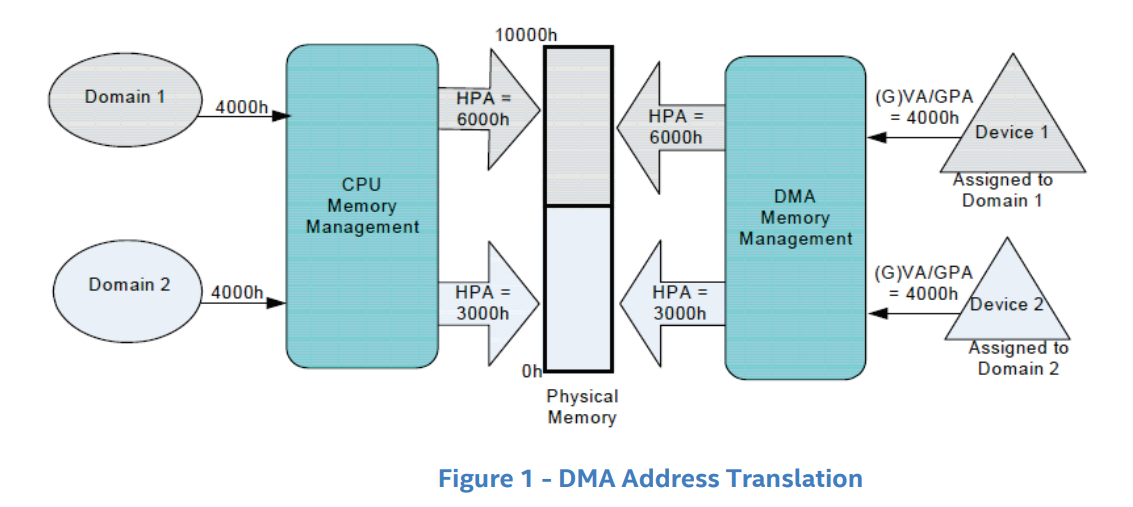
DMA 重映射有着以下的两种方式:
① Request-without-PASID
在 IOMMU 中使用了一个“二层页表 + 标准页表”结构来实现 DMA 重映射,需要占用部分物理内存空间:
- Root Table:存放各个 bus 的 DMA 重映射表地址,一个 entry 对应一个 bus
- Context Table:存放各个 domain 的 DMA 重映射表地址,一个 entry 对应一个 domain
- Address Translation Structure:实际的 DMA 重映射页表
在 IOMMU 中的寄存器 Root Table Address Register 用以存放指向 Root-table 的指针
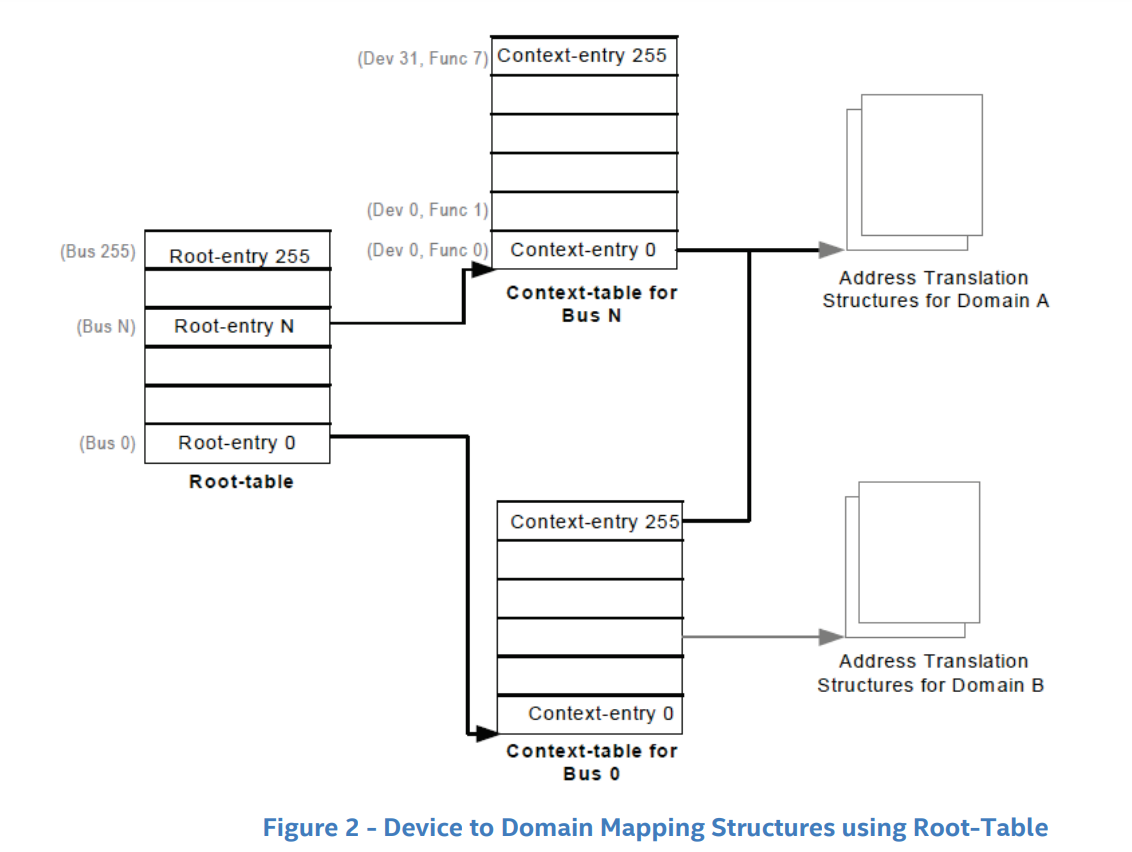
DMA 重映射还需要一个 id 来唯一标识一个设备,对于 PCI 设备而言便是其 BDF(Bus/Device/Function),因此实际的地址访问过程如下图所示:
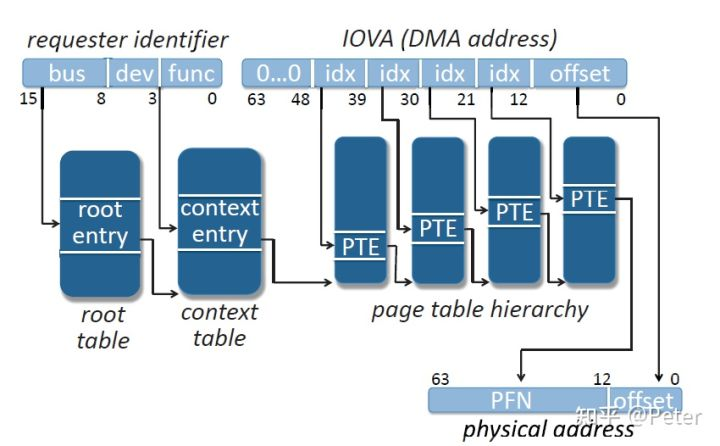
② Request-with-PASID
II.中断重映射
III. IOMMU 与虚拟化
虽然 IOMMU 的引入增加了与外设通信间的开销,但 IOMMU 解决了系统虚拟化技术的一个难点:对于非纯模拟的设备而言,其并不知道 GPA 与 HPA 之间的映射关系,当其按 Guest OS 提供的地址进行 DMA 时会直接访问到 Host 的内存
当引入了 IOMMU 之后,IOMMU 可以根据 Host 侧提供的 GPA 到 HPA 之间的地址转换表,进行DMA remapping,这样外设就能正常地访问到 Guest 的物理内存,而不会错误地访问到 Host 对应的物理内存区域