【CVE.0x06】CVE-2022-0847 漏洞分析及利用
本文最后更新于:2025年4月21日 凌晨
我超,管人痴!
0x00.一切开始之前
CVE-2022-0847 是这两天刚爆出来的一个热乎的内核漏洞,漏洞主要发生在对管道进行数据写入时,由于未对原有的 pipe_buffer->flags 进行清空,从而导致了可以越权对文件进行写入;由于这样的漏洞形式类似于“脏牛”(CVE-2016-5195),但更加容易进行利用,因此研究人员将该漏洞称之为「Dirty Pipe」
据研究者描述,目前 5.8 版本以上的内核均会收到该漏洞的影响,在 5.16.11、5.15.25、5.10.102 版本中才被修复,影响范围不可谓不大,因此这个漏洞也得到了高达 7.8 的 CVSS 评分(CVSS 评分好像改版了,2.0 的标准只有 7.2分)
这个漏洞的发现源自于一次 CRC 校验失败,感兴趣的可以看原作者的博客,是一段十分奇妙的旅程(笑)
本次选用进行分析的内核源码为 Linux 5.13.19(因为笔者前些天刚好编译了一个这个版本的内核,刚好受到该漏洞影响,就直接拿来用了)
在开始分析之前,我们先来补充一些前置知识
pipe:管道
稍微接触过 Linux 的同学应该都知道「管道」这一 IPC 神器。而在 Linux 内核中,管道本质上是创建了一个虚拟的 inode (即创建了一个虚拟文件节点)来表示的,其中在节点上存放管道信息的是一个 pipe_inode_info 结构体(inode->i_pipe),其中包含了一个管道的所有信息
当我们创建一个管道时,内核会创建一个 VFS inode 、一个 pipe_inode_info 结构体、两个文件描述符(代表着管道的两端)、一个 pipe_buffer 结构体数组,下图是一张叙述管道原理的经典图例
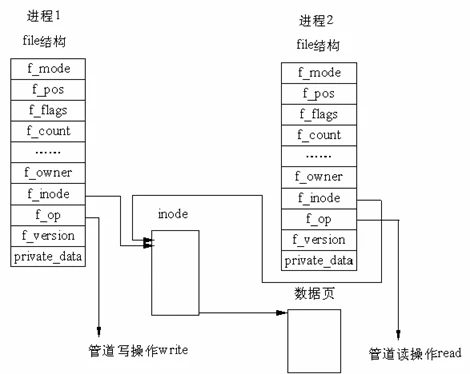
用来表示管道中数据的是一个 pipe_buffer 结构体数组,单个 pipe_buffer 结构体用来表示管道中单张内存页的数据:
1 | |
创建管道使用的 pipe 与 pipe2 这两个系统调用最终都会调用到 do_pipe2() 这个函数,不同的是后者我们可以指定一个 flag,而前者默认 flag 为 0
存在如下调用链:
1 | |
最终调用 kcalloc() 分配一个 pipe_buffer 数组,默认数量为 PIPE_DEF_BUFFERS (16)个,即一个管道初始默认可以存放 16 张页面的数据
1 | |
管道形成的核心结构如下图所示
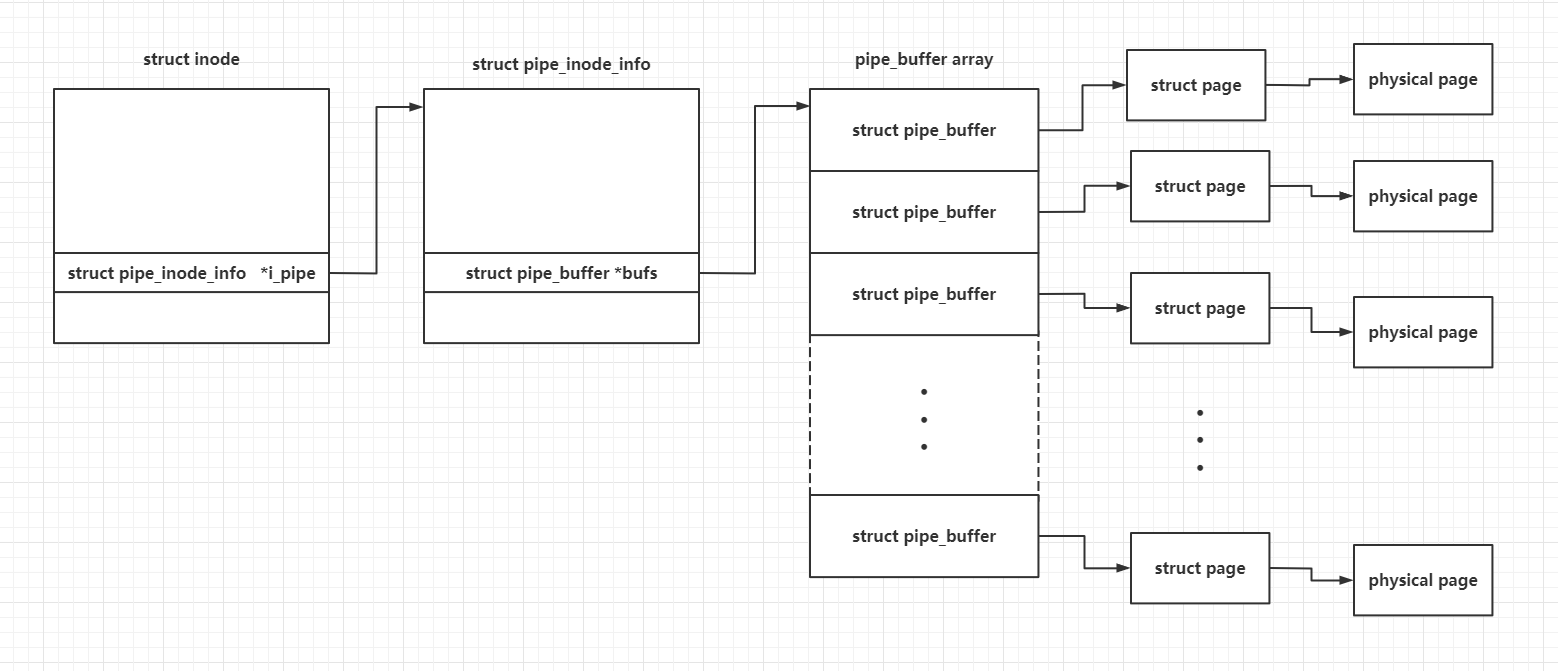
page 结构体用以唯一标识一个物理页框,参见 https://arttnba3.cn/2021/11/28/NOTE-0X07-LINUX-KERNEL-MEMORY-5.11-PART-I/
管道的本体是一个 pipe_inode_info 结构体,其管理 pipe_buffer 数组的方式本质上是一个循环队列,其 head 成员标识队列头的 idx,tail 成员标识队列尾的 idx,头进尾出
1 | |
管道函数表:
阅读 pipe 系统调用源码,注意到如下调用链:
1 | |
在创建管道文件的函数 create_pipe_files() 中,传入 alloc_file_pseudo() 的函数表为 pipefifo_fops,这便是管道相关的操作的函数表
1 | |
该函数表中定义了我们对管道的相关操作会调用到的函数
1 | |
管道的写入过程
查表 pipefifo_fops 可知当我们向管道内写入数据时,最终会调用到 pipe_write 函数,大概流程如下:
- 若管道非空且上一个 buf 未满,则先尝试向上一个被写入的 buffer写入数据(若该 buffer 设置了
PIPE_BUF_FLAG_CAN_MERGE标志位) - 接下来开始对新的 buffer 进行数据写入,若没有
PIPE_BUF_FLAG_CAN_MERGE标志位则分配新页面后写入 - 循环第二步直到完成写入,若管道满了则会尝试唤醒读者让管道腾出空间
这里我们可以看出 PIPE_BUF_FLAG_CAN_MERGE 用以标识一个 pipe_buffer 是否已经分配了可以写入的空间,在大循环中若对应 pipe_buffer 没有设置该 flag(刚被初始化),则会新分配一个页面供写入,并设置该标志位
1 | |
管道的读出过程
从管道中读出数据则是通过 pipe_read,主要是读取 buffer 对应 page 上的数据,若一个 buffer 被读完了则将其出列
原理还是比较简单的,这里就不深入分析了
1 | |
这里我们可以总结:对于一个刚刚建立的管道,其 buffer 数组其实并没有分配对应的页面空间,也没有设置标志位;在我们向管道内写入数据时会通过 buddy system 为对应 buffer 分配新的页框,并设置 PIPE_BUF_FLAG_CAN_MERGE 标志位,标志该 buffer 可以进行写入;而当我们从管道中读出数据之后,纵使一个 buffer 对应的 page 上的数据被读完了,我们也不会释放该 page,而可以也会直接投入到下一次使用中,因此会保留 PIPE_BUF_FLAG_CAN_MERGE 标志位
splice:文件与管道间数据拷贝
当我们想要将一个文件的数据拷贝到另一个文件时,比较朴素的一种想法是打开两个文件后将源文件数据读入后再写入目标文件,但这样的做法需要在用户空间与内核空间之间来回进行数据拷贝,具有可观的开销
因此为了减少这样的开销, splice这一个非常独特的系统调用应运而生,其作用是在文件与管道之间进行数据拷贝,以此将内核空间与用户空间之间的数据拷贝转变为内核空间内的数据拷贝,从而避免了数据在用户空间与内核空间之间的拷贝造成的开销
glibc 中的 wrapper 如下:
1 | |
splice 系统调用本质上是利用管道在内核空间中进行数据拷贝,毫无疑问的是,管道是一个十分好用的内核缓冲区,于是 splice 系统调用选择使用管道作为中间的数据缓冲区
当你想要将数据从一个文件描述符拷贝到另一个文件描述符中,只需要先创建一个管道,之后使用 splice 系统调用将数据从源文件描述符拷贝到管道中、再使用 splice 系统调用将数据从管道中拷贝到目的文件描述符即可。这样的设计使得我们只需要两次系统调用便能完成数据在不同文件描述符间的拷贝工作,且数据的拷贝都在内核空间中完成,极大地减少了开销
splice 系统调用正式操作前都是一些基础的检查工作,这一块不深入分析,存在如下调用链:
1 | |
最终文件与管道间的分流发生在 do_splice() 函数:
- 从管道读取到管道,调用
splice_pipe_to_pipe() - 从文件读取到管道,调用
splice_file_to_pipe() - 从管道读取到文件,调用
do_splice_from()
从文件读取到管道
从文件读取数据到管道的核心原理是:将 pipe_buffer 对应的 page 设置为文件映射的 page
存在如下调用链:
1 | |
在 do_splice_to 中最终会调用到内核文件结构体函数表的 splice_read 指针,对于不同的文件系统而言该函数指针不同,以 ext4 文件系统为例,查表 ext4_file_operations,对应调用的函数应为 generic_file_splice_read,存在如下调用链:
1 | |
该函数是文件函数表中 read_iter() 的 wrapper,对 ext4 而言对应调用 ext4_file_read_iter,源码比较多,这里只贴出核心调用链,最终调用到核心函数是 filemap_read():
1 | |
最终在 copy_page_to_iter_pipe() 中,将对应的 pipe_buffer->page 设为文件映射的页面集的对应页框,将页框引用计数 + 1(get_page()),这样就完成了一个从文件读取数据到管道的过程,因为是直接建立页面的映射,所以每次操作后都会将 head +1
1 | |
这里我们注意到——该操作缺失了对 pipe_buffer->flags 的重新赋值操作
从管道读取到文件
do_splice_from 最终会调用对应内核文件结构的函数表中的 splice_write() 指针,将 pipe_buffer 数组对应页面上内容读出,写入到文件中,对于不同的文件系统而言该函数指针不同
1 | |
以 ext4 文件系统为例,最终会调用到 iter_file_splice_write 函数,之后存在如下调用链:
1 | |
call_write_iter 是文件函数表中 write_iter() 的 wrapper,对 ext4 而言对应调用 ext4_file_write_iter,这里最终只是常规的将 buf 上数据拷贝到文件上的操作,也并非本篇的重点,就不展开分析了
0x01.漏洞分析
我们咋一看好像并没有什么问题,但让我们思考这样一个情景:
- 我们将管道整个读写了一轮,此时所有的 pipe_buffer 都保留了
PIPE_BUF_FLAG_CAN_MERGE标志位 - 我们利用 splice 将数据从文件读取一个字节到管道上,此时 pipe_buffer 对应的 page 成员指向文件映射的页面,但在 splice 中并未清空 pipe_buffer 的标志位,从而让内核误以为该页面可以被写入
- 在 splice 中建立完页面映射后,此时 head 会指向下一个 pipe_buffer,此时我们再向管道中写入数据,管道计数器会发现上一个 pipe_buffer 没有写满,从而将数据拷贝到上一个 pipe_buffer 对应的页面——即文件映射的页面,由于
PIPE_BUF_FLAG_CAN_MERGE仍保留着,因此内核会误以为该页面可以被写入,从而完成了越权写入文件的操作
漏洞点便是在于 splice 系统调用中未清空 pipe_buffer 的标志位,从而将管道页面可写入的状态保留了下来,这给了我们越权写入只读文件的操作
我们不难发现这个漏洞与脏牛十分类似,都是能越权对文件进行写入,不同的是脏牛需要去撞条件竞争的概率,而该漏洞可以稳定触发,但是脏牛可以直接写整个文件,而该漏洞不能在管道边界上写入
当然,如果这个文件甚至都是不可读的,那自然是没法利用的(笑),但在主流 Linux 发行版中有着大量的可作为我们攻击目标的文件,例如 suid 程序或
/etc/passwd等
0x02.漏洞利用
漏洞利用的步骤其实我们在前面都已经叙述得差不多了,主要就是分三步走:
Step.I 写、读管道,设置 PIPE_BUF_FLAG_CAN_MERGE flag
为了保证利用能够稳定成功,我们首先新建一个管道,将管道写满后再将所有数据读出,这样管道的每一个 pipe_buffer 都会被设置上 PIPE_BUF_FLAG_CAN_MERGE 标志位
Step.II splice 建立 pipe_buffer 与文件的关联(漏洞产生点)
接下来我们使用 splice 系统调用将数据从目标文件中读入到管道,从而让 pipe_buffer->page 变为文件在内存中映射的页面,为了让下一次写入数据时写回文件映射的页面,我们应当读入不多于一个数据的页面,这里笔者选择读入 1 个字节,这样我们仍能向文件上写入将近一张页面的数据
当我们完成读入之后,管道的 head 指向下一个 pipe_buffer,因此我们若要写入文件则应当走入到 pipe_write 开头写入上一个 pipe_buffer 的分支,这也是为什么我们在这里只读入一个字节的缘故
Step.III 向管道中写入恶意数据,完成越权写入文件
接下来我们直接向管道中写入数据就能完成对只读文件的越权写入。在 splice 中建立完页面映射后,此时 head 会指向下一个 pipe_buffer,此时我们再向管道中写入数据,管道计数器会发现上一个 pipe_buffer 没有写满,从而将数据拷贝到上一个 pipe_buffer 对应的页面——即文件映射的页面,由于 PIPE_BUF_FLAG_CAN_MERGE 仍保留着,因此内核会误以为该页面可以被写入,从而完成了越权写入文件的操作
poc
我们使用 qemu 起一个测试环境,看看是否能够利用该漏洞对只读文件进行写入,最终的 poc 如下:
1 | |
运行,发现我们成功地覆写了只读文件
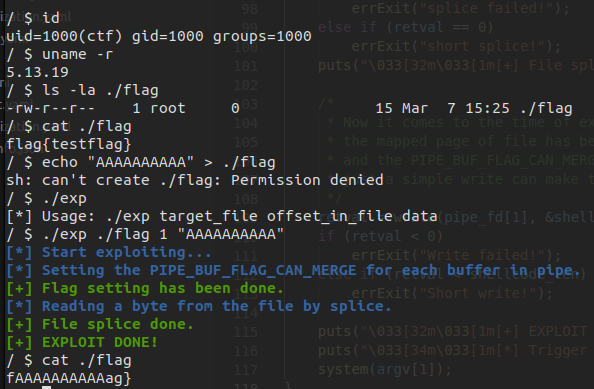
0x03.提权
漏洞的利用形式与“脏牛”基本上是一样的:覆写 /etc/passwd 或者覆写一些 suid 程序进行提权,这里就不过多赘叙了
suid 提权
笔者现给出一个修改指定 suid 程序进行提权的 exp,使用 msfvenom 生成运行 /bin/sh 的 shellcode:
1 | |
在 Ubuntu 21.10 、内核版本 5.13.0-28 上测试的结果如下,成功完成提权:
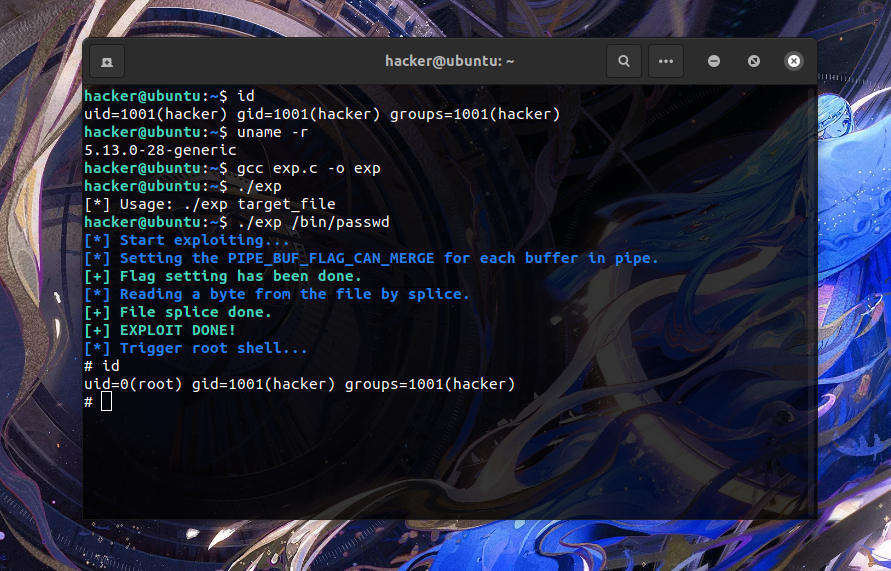
0x04.漏洞修复
漏洞的修复方式比较简单,只需要在对应的涉及到 pipe_buffer->flags 的代码添加上将 flag 置 0 的代码即可,除了 copy_page_to_iter_pipe 以外在 push_pipe 中也缺失了置 0 的代码,补充上即可:
1 | |