【CODE.0x01】简易 Linux Rootkit 编写入门指北
本文最后更新于:2024年7月1日 凌晨
「I’M A PENGUIN」
后门?👴直接重装系统给你扬了(
0x00.概述
「Rootkit」即「root kit」,直译为中文便是「根权限工具包」的意思,在今天的语境下更多指的是一种被作为驱动程序、加载到操作系统内核中的恶意软件,这一类恶意软件的主要用途便是「驻留在计算机上提供 root 后门」——当攻击者再次拿到某个服务器的 shell 时可以通过 rootkit 快速提权到 root
Linux 下的 rootkit 主要以「可装载内核模块」(LKM)的形式存在,作为内核的一部分直接以 ring0 权限向入侵者提供服务;当攻击者拿到某台计算机的 shell 并通过相应的漏洞提权到 root 之后便可以在计算机中留下 rootkit,以为攻击者后续入侵行为提供驻留的 root 后门
但是作为内核的一部分,LKM 编程在一定意义上便是内核编程,与内核版本密切相关,只有使用相应版本内核源码进行编译的 LKM 才可以装载到对应版本的 kernel 上,这使得 Linux rootkit 显得有些鸡肋(例如服务器管理员某天升级内核版本你就被扬了),且不似蠕虫病毒那般可以在服务期间肆意传播,但不可否认的是 LMK 仍是当前 Linux 下较为主流的 rootkit 技术之一
本篇博客仅为最基础的 rootkit 编写入门指南,不建议大家做一些违法犯罪的事情:)
本篇引用的内核源码来自于 Linux 内核版本 5.11
Linux 下尝试装载不同版本的 LKM 会显示如下错误信息:
insmod: ERROR: could not insert module hellokernel.ko: Invalid module format
0x01. 最简单的 LKM
这里不会叙述太多 Linux 内核编程相关的知识,主要以 rootkit 编写所会用到的一些技术为主
基本的 LKM 编写入门见这里
以下给出了一个最基础的 LKM 模板,注册了一个字符型设备作为后续使用的接口
rootkit.c
1 | |
functions.c
1 | |
rootkit.h
1 | |
makefile
1 | |
我们接下来将以该模块作为蓝本进行修改
0x02.进程权限提升
cred 结构体
对于 Linux 下的每一个进程,在 kernel 中都有着一个结构体 cred 用以标识其权限,该结构体定义于内核源码include/linux/cred.h中,如下:
1 | |
我们主要关注 uid ,一个cred结构体中记载了一个进程四种不同的用户ID:
- 真实用户ID(real UID):标识一个进程启动时的用户ID
- 保存用户ID(saved UID):标识一个进程最初的有效用户ID
- 有效用户ID(effective UID):标识一个进程正在运行时所属的用户ID,一个进程在运行途中是可以改变自己所属用户的,因而权限机制也是通过有效用户ID进行认证的
- 文件系统用户ID(UID for VFS ops):标识一个进程创建文件时进行标识的用户ID
权限提升
Linux kernel 进程权限相关细节不在此赘叙,可以参见这里
cred 结构体中存储了进程的 effective uid,那么我们不难想到,若是我们直接改写一个进程对应的 cred 结构体,我们便能直接改变其执行权限
而在 Linux 中 root 用户的 uid 为 0,若是我们将一个进程的 uid 都改为 0,该进程便获得了 root 权限
方法I.调用commit_creds(prepare_kernel_cred(NULL))
pwn 选手应该都挺熟悉这个hhhh
在内核空间有如下两个函数,都位于kernel/cred.c中:
struct cred* prepare_kernel_cred(struct task_struct* daemon):该函数用以拷贝一个进程的cred结构体,并返回一个新的cred结构体,需要注意的是daemon参数应为有效的进程描述符地址或NULLint commit_creds(struct cred *new):该函数用以将一个新的cred结构体应用到进程
查看prepare_kernel_cred()函数源码,观察到如下逻辑:
1 | |
在prepare_kernel_cred()函数中,若传入的参数为NULL,则会缺省使用init进程的cred作为模板进行拷贝,即可以直接获得一个标识着root权限的cred结构体
那么我们不难想到,只要我们能够在内核空间执行commit_creds(prepare_kernel_cred(NULL)),那么就能够将进程的权限提升到root
我们来简单测试一下:修改 write 函数,在用户向设备写入时将其提权到 root:
1 | |
简单测试一下,可以看到当我们向设备内写入任意内容后便提权到了 root

方法II.直接修改 cred 结构体
前面我们讲到,commit_creds() 函数用以将一个新的 cred 应用到当前进程,我们来观察其源码相应逻辑:
1 | |
在该函数开头直接通过宏 current 获取当前进程的 task_struct,随后修改的是其成员 real_cred,那么我们在内核模块中同样可以直接通过该宏获取当前进程的 task_struct 结构体,从而直接修改其 real_cred 中的 uid 以实现到 root 的提权
那么我们的代码可以修改如下:
1 | |
这里需要注意的是 uid 与 gid 的类型为封装为结构体的 kuid_t 与 kgid_t 类型,应当使用宏 KGIDT_INIT() 与 KUIDT_INIT() 进行赋值
可以看到当我们向设备写入之后便提权到了 root,不同的是我们只修改了几个 uid 和 gid,所以原有的其他信息依旧会保留,这里也可以选择把其他的一并改掉

current:CPU 局部变量保存当前进程 task_struct 结构体
这里简单讲一下宏
current的是如何获取当前进程的 task_struct 的:该宏定义于内核源码arch/x6/include/asm/current.h中,展开后为函数static __always_inline struct task_struct *get_current(void),该函数只有一句return this_cpu_read_stable(current_task);:其中
current_task为 CPU 局部变量,在头文件开头使用宏DECLARE_PER_CPU从外部引入该变量,该宏定义于include/linux/percpu-defs.h中,展开后为DECLARE_PER_CPU_SECTION(type, name, ""),该宏再度展开为extern __PCPU_ATTRS(sec) __typeof__(type) name,该宏再度展开为__percpu __attribute__((section(PER_CPU_BASE_SECTION sec))) PER_CPU_ATTRIBUTES,其中宏PER_CPU_BASE_SECTION定义于include/asm-generic/percpu.h中,SMP(多对称处理)下展开为字符串".data..percpu"。最终展开为__attribute__((section(".data..percpu"))) (type) name,其中__attribute__宏为 gcc 的特殊机制,具体的参见手册那么我们可以知道该宏最终便是外部引用了一个位于 .data..percpu 这一数据段中的 task_struct 类型的变量 current_task
接下来看宏
this_cpu_read_stable,该宏定义于arch/x86/include/asm/percpu.h中,展开为__pcpu_size_call_return(this_cpu_read_stable_, pcp),再度展开为如下:
2
3
4
5
6
7
8
9
10
11
12
13
14#define __pcpu_size_call_return(stem, variable) \
({ \
typeof(variable) pscr_ret__; \
__verify_pcpu_ptr(&(variable)); \
switch(sizeof(variable)) { \
case 1: pscr_ret__ = stem##1(variable); break; \
case 2: pscr_ret__ = stem##2(variable); break; \
case 4: pscr_ret__ = stem##4(variable); break; \
case 8: pscr_ret__ = stem##8(variable); break; \
default: \
__bad_size_call_parameter(); break; \
} \
pscr_ret__; \
})开头先定义了一个变量
pscr_ret__,使用typeof(GNU C 扩展关键字)获取 variable 的类型其中宏
__verify_pcpu_ptr()同样定义于该文件中,如下:
2
3
4
5#define __verify_pcpu_ptr(ptr) \
do { \
const void __percpu *__vpp_verify = (typeof((ptr) + 0))NULL; \
(void)__vpp_verify; \
} while (0)其中
do...while(0)结构为约定熟成的「只执行一次的语句」的宏的书写形式,该宏中定义了一个 void 指针通过强制类型转换获取 NULL 转成 ptr 的类型给到该指针(好像没什么用…?),然后下一句再转为 NULL(空转,没有做任何其他诸如赋值一类的事情,笔者才疏学浅暂时不理解这么做的理由)接下来根据变量 variable 的 size 进行宏拼接,前面我们传入的
current_task变量为struct task_struct *指针类型,这里以 64 位系统为例,最终得到的拼接结果为宏this_cpu_read_stable_8,定义于arch/x86/include/asm/percpu.h中(绕了一圈又回来了),展开为percpu_stable_op(8, "mov", pcp),再度展开为如下形式:
2
3
4
5
6
7
8
9#define percpu_stable_op(size, op, _var) \
({ \
__pcpu_type_##size pfo_val__; \
asm(__pcpu_op2_##size(op, __percpu_arg(P[var]), "%[val]") \
: [val] __pcpu_reg_##size("=", pfo_val__) \
: [var] "p" (&(_var))); \
(typeof(_var))(unsigned long) pfo_val__; \
})其中
__pcpu_type_8展开为u64,在多个头文件中都有定义,最终展开为unsigned long long的 typedef 别名下一行使用了内联汇编,其中拼接后得到的宏
__pcpu_op2_8(op, src, dst)同样位于这个头文件,展开为op "q " src ", " dst;__percpu_arg(x)展开为__percpu_prefix "%" #x, 再展开为"%%"__stringify(__percpu_seg)":":__stringify展开为__stringify_1(x)展开为#x,__percpu_seg展开为gs,合起来便是%%gs:%P[var];拼接宏__pcpu_reg_8(mod, x)展开为mod "r" (x)最终展开为如下形式:
2
3
4
5unsigned long long pfo_val__;
asm("movq %%gs:%P[var], %[val]" \
: [val] "=r" (pfo_val__) \
: [var] "p" (&(current_task)));
(struct task_struct *)(unsigned long) pfo_val__;反人类的AT&T汇编语法什么时候能滚出地球(恼)
拨开 Linux 内核源码中的 114514 层嵌套之后我们大抵能够明白该段代码的核心便是以 gs 寄存器作为基址,取 current_task 变量偏移处值赋给 pfo_val__ 变量,随后返回 pro_val__ 变量
那么为什么 gs 寄存器中存的地址在这个偏移上便是该进程的 task_struct 结构呢?这个和 percpu 机制有关,这里先🕊了()
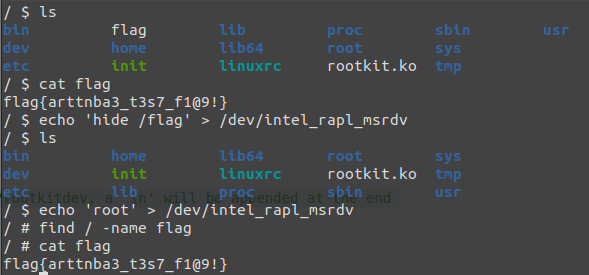
0x03.模块隐藏
当我们将一个 LKM 装载到内核模块中之后,用户尤其是服务器管理员可以使用 lsmod 命令发现你在服务器上留下的rootkit
1 | |
虽然说我们可以把 rootkit 的名字改为「very_important_module_not_root_kit_please_donot_remove_it」一类的名字进行伪装从而通过_社会工程学手段_让用户难以发现异常,但是哪怕看起来再“正常”的名字也不能够保证不会被发现,因此我们需要让用户无法直接发现我们的 rootkit
PRE.内核中的内核模块:module 结构体
这里仅简要叙述,在内核当中使用结构体 module 来表示一个内核模块(定义于 /include/linux/module.h),多个内核模块通过成员 list (内核双向链表结构list_head,定义于/include/linux/types.h 中,仅有 next 与 prev 指针成员)构成双向链表结构
在内核模块编程中,我们可以通过宏 THIS_MODULE (定义于 include/linux/export.h)或者直接用其宏展开 &__list_module 来获取当前内核模块的 module 结构体,
Step-I. /proc/modules 信息隐藏
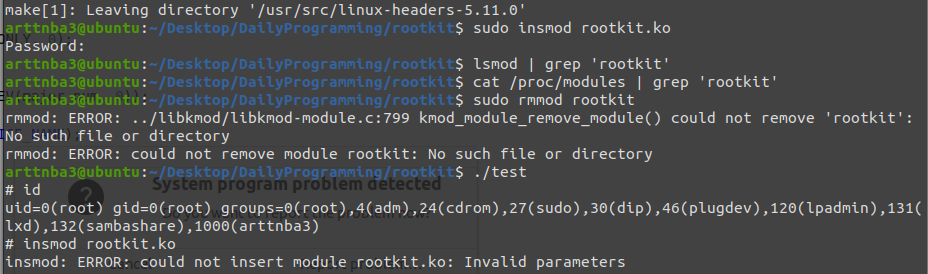
Linux 下用以查看模块的命令 lsmod 其实是从 /proc/modules 这个文件中读取并进行整理,该文件的内容来自于内核中的 module 双向链表,那么我们只需要将 rootkit 从双向链表中移除即可完成 procfs 中的隐藏
熟悉内核编程的同学应该都知道 list_del_init() 函数用以进行内核双向链表脱链操作,该函数定义于 /include/linux/list.h 中,多重套娃展开后其核心主要是常规的双向链表脱链,那么在这里我们其实可以直接手写双向链表的脱链工作
我们还需要考虑到多线程操作的影响,阅读 rmmod 背后的系统调用 delete_module 源码(位于 kernel/module.c 中),观察到其进入临界区前使用了一个互斥锁变量名为 module_mutex,我们的 unlink 操作也将使用该互斥锁以保证线程安全(毕竟我们进来不是直接搞破坏的hhh)
在模块初始化函数末尾添加如下:
1 | |
将我们的 rootkit 重新 make 后加载到内核中,我们会发现 lsmod 命令已经无法发现我们的 rootkit,在 /proc/modules 文件中已经没有我们 rootkit 的信息,与此同时我们的 rootkit 所提供的功能一切正常
但同样地,无论是载入还是卸载内核模块都需要对双向链表进行操作,由于我们的 rootkit 已经脱链故我们无法将其卸载(不过 rootkit 一次载入后应当是要长久驻留在内核中的)
Step-II. /sys/module/ 信息隐藏
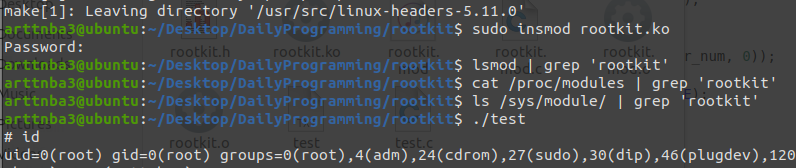
sysfs 与 procfs 相类似,同样是一个基于 RAM 的虚拟文件系统,它的作用是将内核信息以文件的方式提供给用户程序使用,其中便包括我们的 rootkit 模块信息,sysfs 会动态读取内核中的 kobject 层次结构并在 /sys/module/ 目录下生成文件
这里简单讲一下 kobject:Kobject 是 Linux 中的设备数据结构基类,在内核中为 struct kobject 结构体,通常内嵌在其他数据结构中;每个设备都有一个 kobject 结构体,多个 kobject 间通过内核双向链表进行链接;kobject 之间构成层次结构
kobject 更多信息参见https://zhuanlan.zhihu.com/p/104834616
熟悉内核编程的同学应该都知道我们可以使用 kobject_del() 函数(定义于 /lib/kobject.c中)来将一个 kobject 从层次结构中脱离,这里我们将在我们的 rootkit 的 init 函数末尾使用这个函数:
1 | |
简单测试,我们可以发现无论是在 procfs 中还是 sysfs 中都已经没有了我们的 rootkit 的身影,而提权的功能依旧正常,我们很好地完成了隐藏模块的功能
Step-III. 文件隐藏
前面我们讲到我们注册了一个字符型设备作为我们用户进程的接口,但是无论命名得再怎么好,一个陌生的设备仍容易被管理员发现;同样地,我们的 rootkit 既然要长久驻留在系统上,那么在系统每一次开机时都应当载入我们的 rootkit,这就要求我们的 rootkit 文件还需要保留在硬盘上
因此接下来我们还要完成相关文件的隐藏的工作
文件遍历过程
在 Linux 中最常用的遍历文件的指令为 ls,我们使用 strace 来观察其所使用到的系统调用,去除掉前面的载入 glibc 库所使用的系统调用以外,我们会发现其调用了一个名为 getgetdents64 的系统调用:
1 | |
其代码位于内核源码文件 /fs/readdir.c,如下:
1 | |
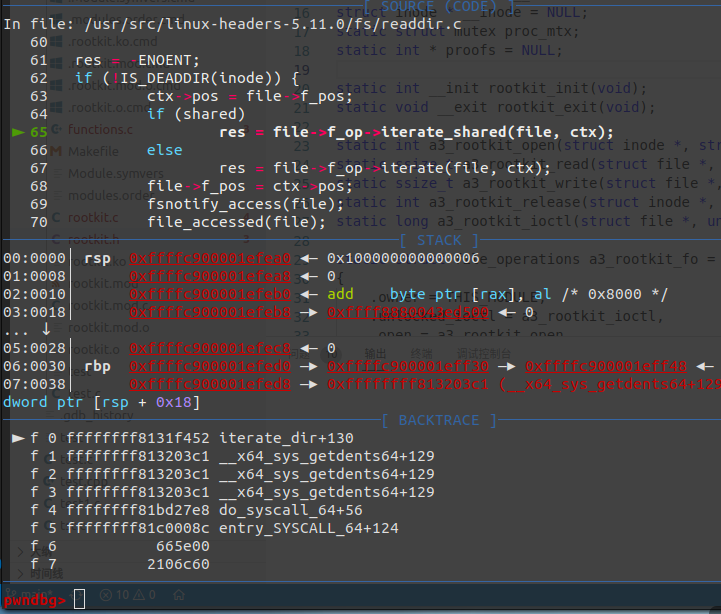
在 ls 命令调用该系统调用时传入的第一个参数为文件描述符 3——对应的文件是 .,即当前目录;代码中的 fdget_pos() 与 fdput_pos() 函数用以对文件进行加/解锁操作,该系统调用的核心操作是 iterate_dir() 函数,定义于 /fs/readdir.c 中,观察代码我们可以发现如下逻辑:
1 | |
在 Linux 内核中使用 VFS 统一不同的文件系统,其中使用 file 结构体来表示一个文件,而每个文件都有一张函数表 file_operations 函数表对应相应的对该文件的相关操作(例如 read、write),该函数表取自该文件对应的 inode,最终取自相应的文件系统提供的具体函数
在这里会调用表中的函数指针 iterate_shared 或 iterate,用 gdb 简单调试一下内核,可以发现在 5.11.0 版本的内核中调用的是 iterate_shared
EXT4:(未完成)
笔者的机子用的是 ext4 文件系统,这也是目前 Linux 机器最常见的文件系统之一,我们来看内核源码中对应函数的实现,在 /fs/ext4/dir.c 中有如下定义:
1 | |
即 ext4 文件系统中 iterate_shared 便是 ext4_readdir,该函数定义于 /fs/ext4/dir.c 中,
🕊🕊🕊
ramVFS:d_child 链表脱链隐藏文件
我们都知道在 VFS 中 dentry (目录项)用以表示一个文件/文件夹,对于 dentry 而言,其构成如下图所示拓扑结构
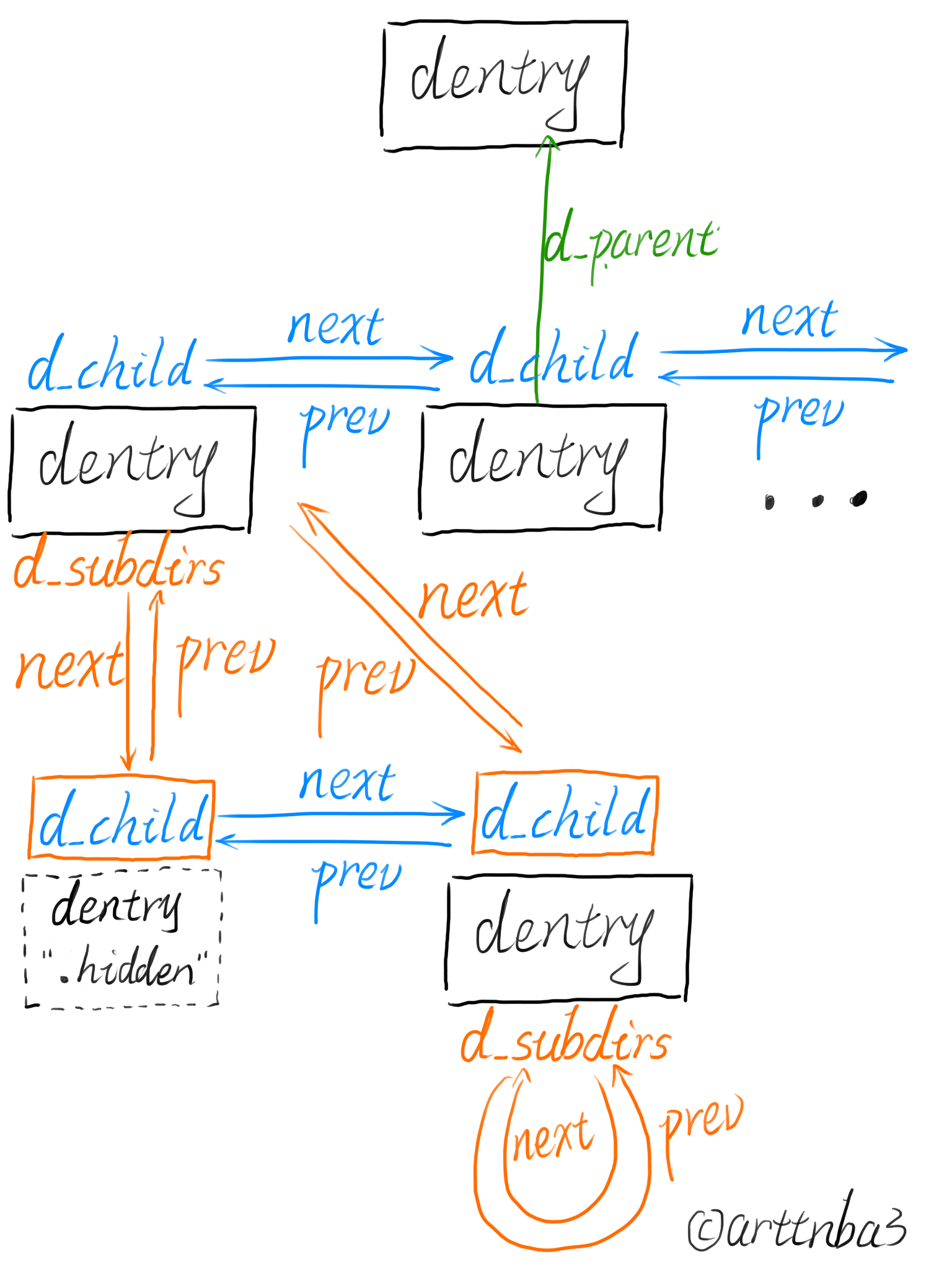
由此拓扑结构我们不难看出:在 VFS 中基于 dentry 的 d_child 链表遍历一个目录。由此我们不难想到的是只要我们将一个文件的 dentry 从其 d_child 链表中脱链,就能成功隐藏该文件
我们在 VFS 中隐藏文件的代码如下:
1 | |
这里用 qemu 起一个虚拟机跑我们的 rootkit,用 busybox 构建一个文件系统
简单测试一下,当我们将要隐藏的文件在 VFS 中对应的 dentry 从其 d_child 链表中摘除之后,我们便无法通过 ls 或是 find 命令找到这个文件,但是该文件仍能被正常访问,由此我们成功地将一个文件隐藏了起来
/dev 设备文件隐藏
同样地,我们用以与 rootkit 进行通信的设备文件基于 devtmpfs,为基于 ram 的文件系统,因此我们可以直接在 VFS 中将其 dentry 从其 d_child 链表脱链,完成该设备文件的隐藏
简单测试一下,我们在 /dev 目录下已经无法找到该设备文件,但是我们仍能与我们的 rootkit 正常通信

这里简单讲一下 Linux 内核中的 VFS——Virtual File System,VFS 为对文件系统的操作提供了统一的接口,将对 ext2、ext3、ntfs…之类的文件系统的操作在 VFS Layer 中统一,由 VFS 向用户及内核的其他部分提供文件操作的统一 API
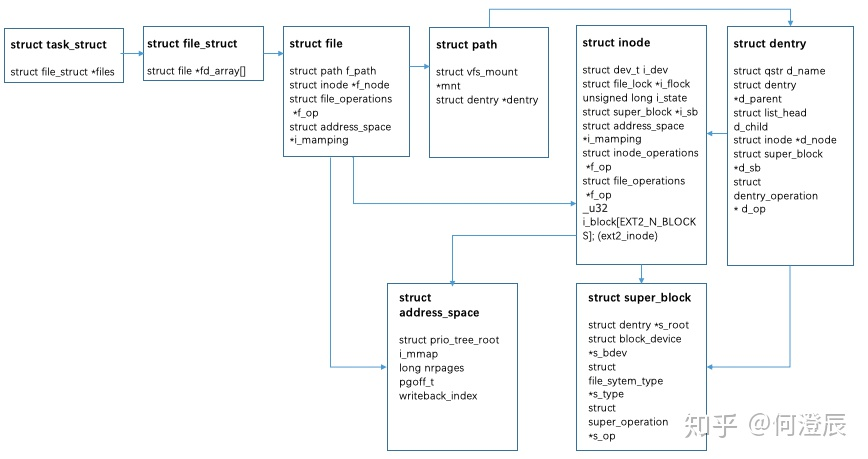
VFS 中的文件为如下结构(此图来自于知乎):
简单讲一下这张图中涉及到的内核数据结构:
- task_struct:内核中的进程描述符
- file_struct:每个进程打开的文件的文件描述符表
- file:内核 VFS 中的文件描述符,用以描述一个文件对象
- path:
- inode:文件索引项,用以索引硬盘上的文件,一个 inode 对应一个文件
- dentry:目录项,仅会在内存中被创建,用以加快索引,一个目录项对应一条路径上的一个组件(例如路径
/a3dir/a3pro.c对应三个 dentry:/、a3dir、a3proc.c)- address_space:
- super_block:用以描述一个文件系统的相关信息(如 inode 等),一个文件系统对应一个 super_block
在内核中每次打开文件都会创建一个 file 对象,因而一个文件在内核中可以对应多个 file 对象,但是只能对应一个 inode 和一个 dentry
我们来简单观察文件在内核中创建的过程,观察到如下调用链:
2
3
4
5
6
7
8
9
10
11
12
13
14>sys_open() // fs/open.c
do_sys_open() // fs/open.c
do_sys_openat2() // fs/open.c,获取文件名字,在 PCB 中分配空闲 fd
do_filp_open() // fs/namei.c
set_nameidata() // fs/namei.c,获取 nameidata结构体(辅助搜索结构)
path_openat() // fs/namei.c
alloc_empty_file() // 分配 file 结构体空间
do_open() // fs/namei.c
audit_inode() // include/linux/audit.h
__audit_inode() // kernel/auditsc.c,获取文件对应 inode 存到 nameidata
vfs_open() // fs/open.c
d_backing_inode() // include/linux/dcache.h,取得 nameidata 中 inode
do_detry_open() // fs/open.c,初始化 file 结构体各项属性观察
do_dentry_open()代码,我们可以发现如下逻辑:
2
3
4
5
6
7
8
9>static int do_dentry_open(struct file *f,
struct inode *inode,
int (*open)(struct inode *, struct file *))
{
...
f->f_op = fops_get(inode->i_fop);
...即初始时 file 结构体的 file_operations 函数表使用的是其对应 inode 的
i_fop成员
0x04.进程隐藏
在内核当中没有 glibc 库,若是想要进行一些常规的操作其实是较为困难的,相比之下一个 root 权限的进程比内核模块更适合也更方便去做这些事情,因此除了内核模块以外我们的 rootkit 还应当包含有一个用户态下的进程,但是这个进程同样很容易被发现,因此我们还需要完成进程隐藏的工作:
- 脱离 task_struct 链表
- 脱离 pid 链表
- 重分配 task_struct 内存空间
- 重分配 cred 内存空间
- 设置手动内存回收
当然,如下给出的进程隐藏的方法仍有风险:我们无法将该进程从运行队列中隐藏(不然没法跑),因此若是遍历运行队列仍有可能发现我们的恶意进程,因此我们后续的恶意进程的设计最好不要过于大张旗鼓
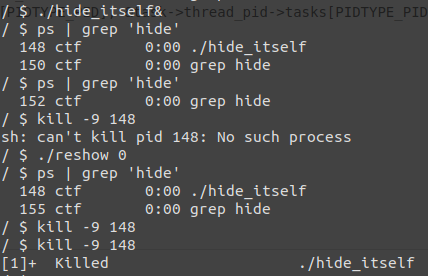
Step-I. 从 task_struct 链表与 pid 链表中摘除进程
我们都知道 Linux kernel 中的 PCB 为 task_struct 结构体,多个 task_struct 之间相互连接成双向链表结构,若是运维人员选择遍历 task_struct 链表便很容易发现我们的恶意进程,因此我们需要将我们的进程从 task_struct 链表中摘除
同样的,运维人员若是遍历 /proc/pid 、甚至是直接遍历所有进程号,则很容易发现我们的恶意进程,因此我们还需要将其从 pid 链表中摘除
为了预防万一,这里还写了一个将进程恢复至链表中的功能
1 | |
附上两个测试例程:
hide_itself.c
1 | |
reshow.c
1 | |
简单测试一下,可以发现我们很好地完成了进程隐藏的功能:当我们的进程被隐藏之后,我们无法使用 ps 命令找到她,也无法通过 kill 命令杀死她,只有当我们将其恢复之后才能正常找到并将其 kill 掉
Step-II. 重分配 PCB 相关内存空间(未完成)
我们简单看一下进程的创建方式:在 Linux 启动时会有一个 init 进程,接下来的进程都是 init 的子进程,故我们接下来阅读 fork 系统调用的源码,观察到如下调用链:
1 | |
在 copy_process() 函数中使用 dup_task_struct() 分配新的 task_struct 结构体,阅读内核源码观察到如下调用链:
1 | |
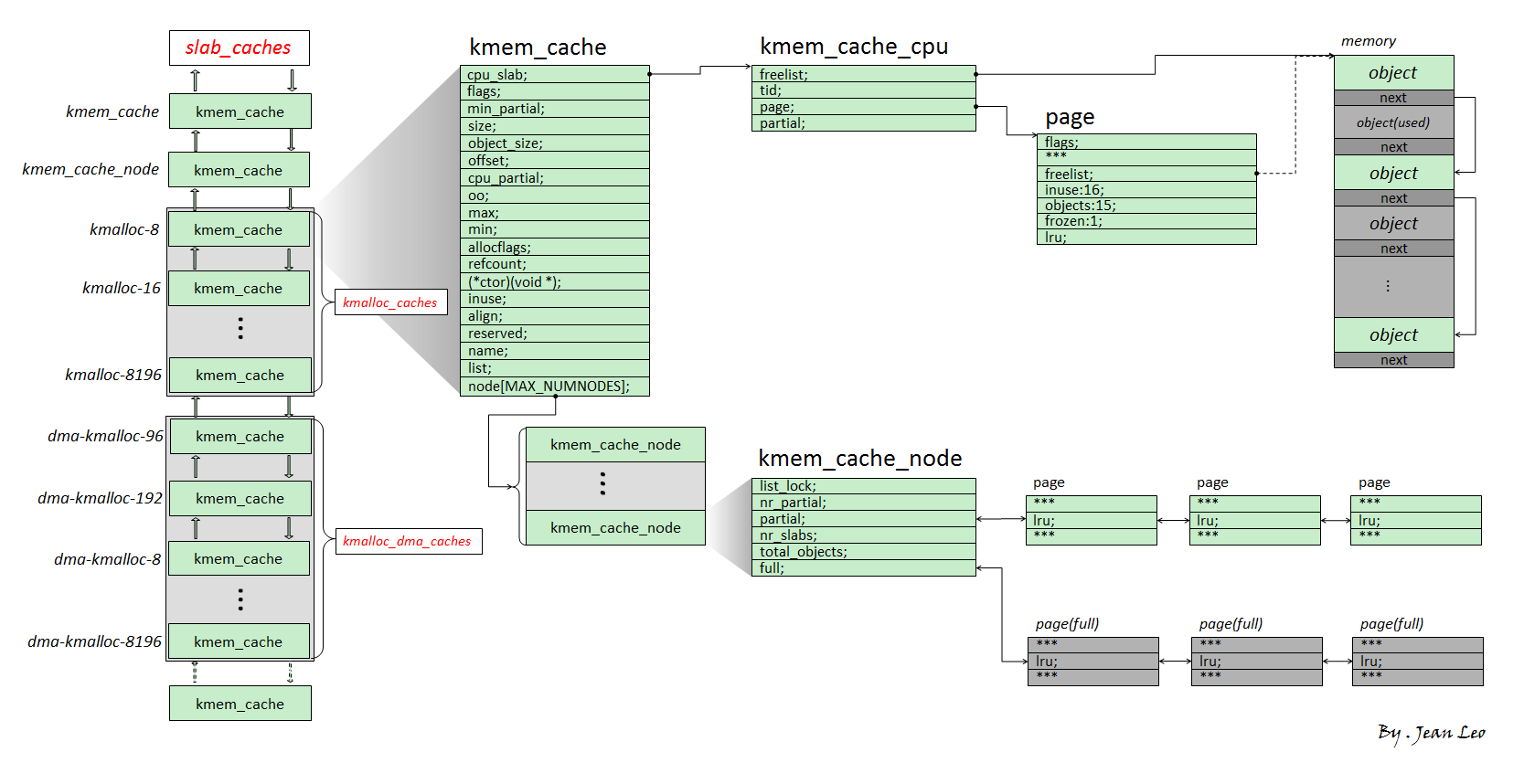
在 alloc_task_struct_node() 中调用 kmem_cache_alloc_node() 从 task_struct_cachep 这个 kmem_cache 中分配 task_struct 结构体所需内存,因此我们不难想到的是若是 rootkit 检测工具选择遍历 task_struct_cachep,我们的恶意进程将无处可逃
一个 kmem_cache 由多个 slub 组成,一个 slub 为由 buddy system 分配而来的一个或多个连续页框组成,划分为数个小 chunk 进行使用
图是偷的,侵删
同样地,在 copy_process() 函数中使用 copy_creds() 分配新的 cred 结构体,阅读内核源码观察到如下调用链:
1 | |
在 prepare_creds() 中调用 kmem_cache_alloc() 从 cred_jar 这个 kmem_cache 中分配 cred 结构体所需内存,因此我们不难想到的是若是 rootkit 检测工具选择遍历cred_jar,我们的恶意进程将无处可逃
因此我们需要重新分配其内存空间,为了保险起见,我们不直接向现有的 slub 申请空间,而是绕过 slub 直接向 buddy system 申请内存页来存放我们的隐藏进程的 task_struct 与 cred
但由于我们绕过了 slub 进行内存替换,此时内核已经无法通过正常途径回收该进程的 task_struct 与 cred,因此我们需要:
- 设置其引用计数器为大于
1的值,在进程退出之后操作系统便不会直接回收其内存 - 在 rootkit 中写一个回收函数,手动回收我们的恶意进程的内存(例如由另一个进程向 rootkit 发送回收的信号)
0x05.驻留
我们似乎在管理员不知情的情况下在他服务器中留下了一个 rootkit,但若是某一天服务器管理员闲着无聊 reboot 一下,我们的努力将全 部 木 大,因此我们还需要研究如何让 rootkit 在服务器能够长期驻留
我们不难想到的是,若是我们能够向一些开机便会自行启动的服务中写入加载我们的 rootkit 的指令,那么每一次系统启动的时候我们的 rootkit 便能被自动载入到内核当中
方法 I. 写入/etc/rc.modules
这也是大名鼎鼎的 Linux rootkit Raptile 所采用的操作
方法 II. 写入initrd
0x06.用户态进程
PRE.启动新进程
可以使用 _wake_up_new_task() 将一个 task_struct 加入运行队列