【GLIBC.0x00】glibc2.23 malloc源码分析 - I:堆内存的基本组织形式
本文最后更新于:2023年10月27日 中午
让我们先从最简单的chunk讲起…
0x00.堆内存的组织形式
一、malloc_chunk
思来想去还是先从最简单的堆块的基本组织形式——malloc_chunk结构体开始讲起,同时也事先讲完一些通用宏定义,省得后面再不断的递归套娃回来看chunk相关的各种定义(←因为这个人真的遇到了这样的情况)
通常情况下,我们将向系统所申请得到的内存块称之为chunk,在ptmalloc的内部使用malloc_chunk结构体来表示,代码如下:
1 | |
首先我们先看一些相关的宏定义:
1 | |
大致如下:
- INTERNAL_SIZE_T宏展开后其实就是size_t,32位下为4字节,64位下为8字节,SIZE_SZ为其别名
- MALLOC_ALIGNMENT则定义了chunk在内存中对齐的字节数,一般来说算出来都是对2*SIZE_SZ对齐,即32位下8字节对齐,64位下16字节对齐
- MALLOC_ALIGEN_MASK的值则是MALLOC_ALIGENMENT - 1,笔者猜测其表示的是标志位全满的标志位值(掩码),用以进行后续的标志位清除运算等操作
The __alignof__ operator
The __alignof__ operator is a language extension to C99 and Standard C++ that returns the number of bytes used in the alignment of its operand. The operand can be an expression or a parenthesized type identifier. If the operand is an expression representing an lvalue, the number returned by alignof represents the alignment that the lvalue is known to have. The type of the expression is determined at compile time, but the expression itself is not evaluated. If the operand is a type, the number represents the alignment usually required for the type on the target platform.
(from IBM Knowledge Center)
大意是说__alignof__运算符是对C99及标准C++的拓展,用以返回运算对象所占用空间的字节数
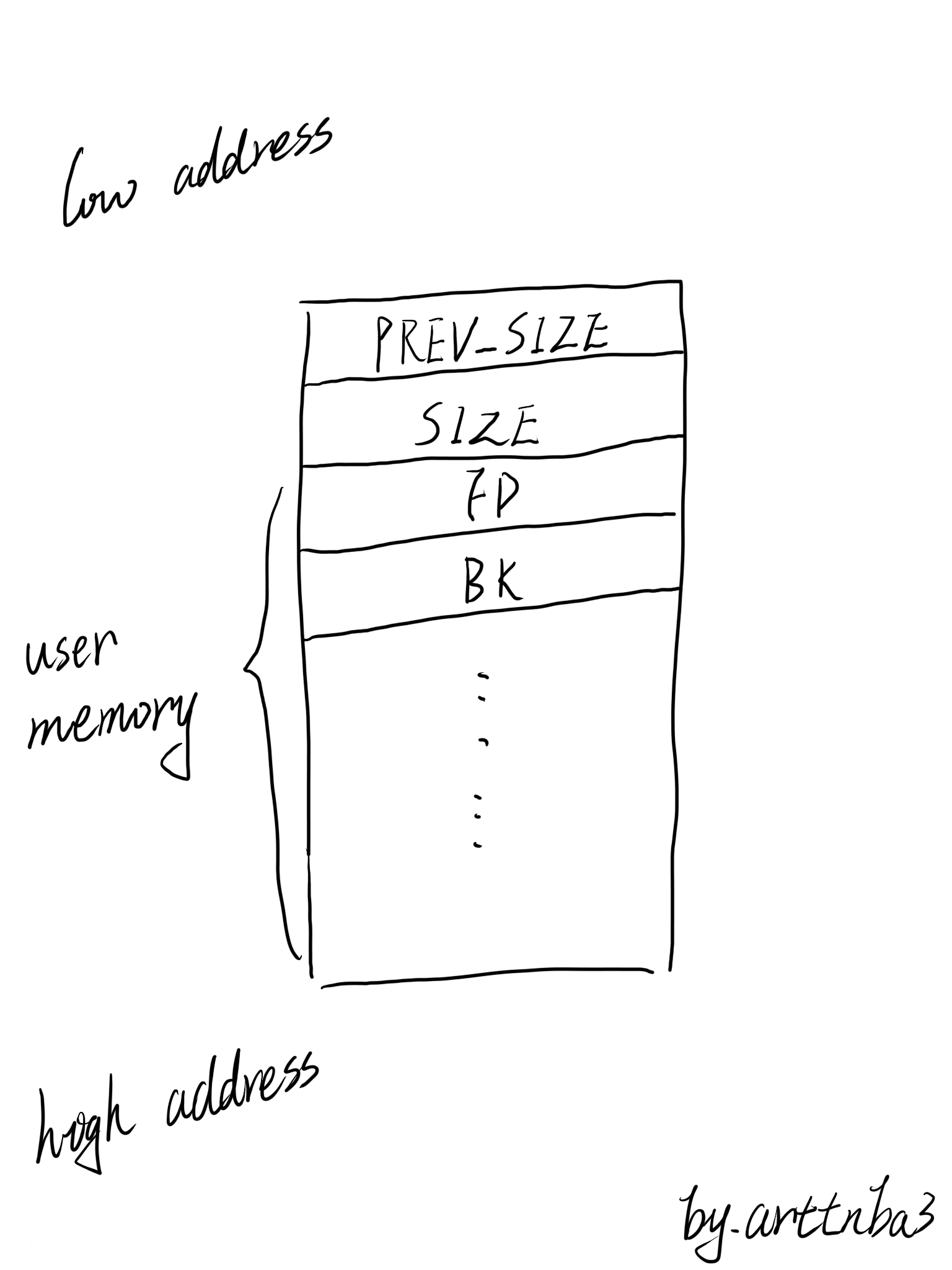
结构体中一共有六个变量,大致如下:
- prev_size:用以保存前一个内存物理地址相邻的chunk的size,仅在该chunk为free状态时会被使用到
- size:顾名思义,用以保存这个chunk的总的大小,即同时包含chunk头(prev_size + size)和chunk剩余部分的大小
- fd&&bk:仅在在chunk被free后使用,用以连接其他的chunk,也就是说当chunk处于被使用的状态时该字段无效,被用以存储用户的数据
- fd_nextsize&&bk_nextsize:仅在在chunk被free后使用,用以连接其他的chunk
后面我们还会再详细讲解这几个变量的相关内容,这里仅作一简览
由于最后的两个变量仅用于较大的free的chunk,故我们先暂且忽略
那么我们便可以知道:一个chunk在内存中大概是长这个样子的:
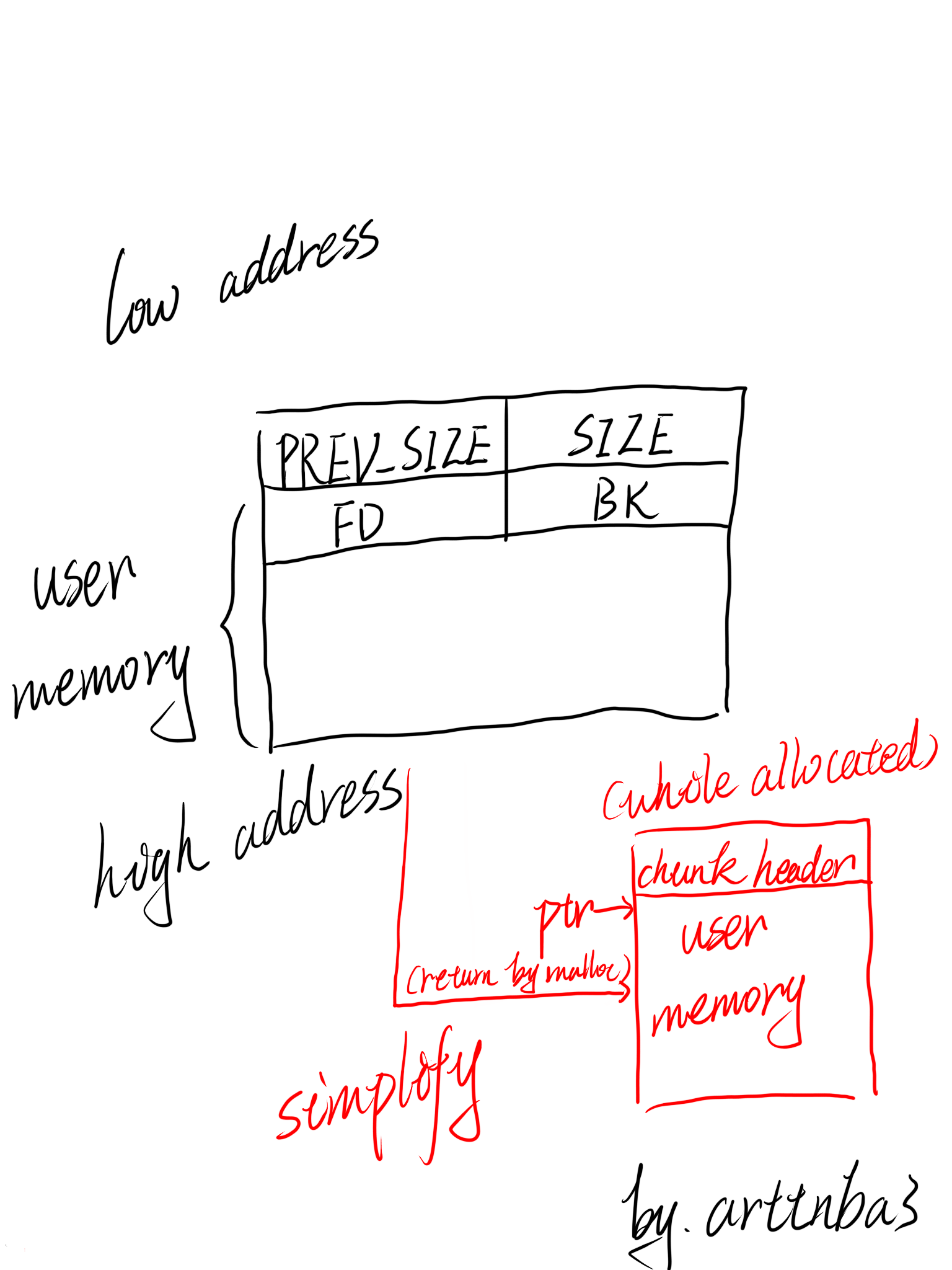
当然,我个人更喜欢用如下的结构来表示,问就是👴喜欢和MALLOC_ALIGNMENT对齐的感觉
二、chunk相关宏
malloc.c中还定义了一些和malloc_chunk相关的宏,如下:
1.chunk size相关宏
1 | |
大致如下:
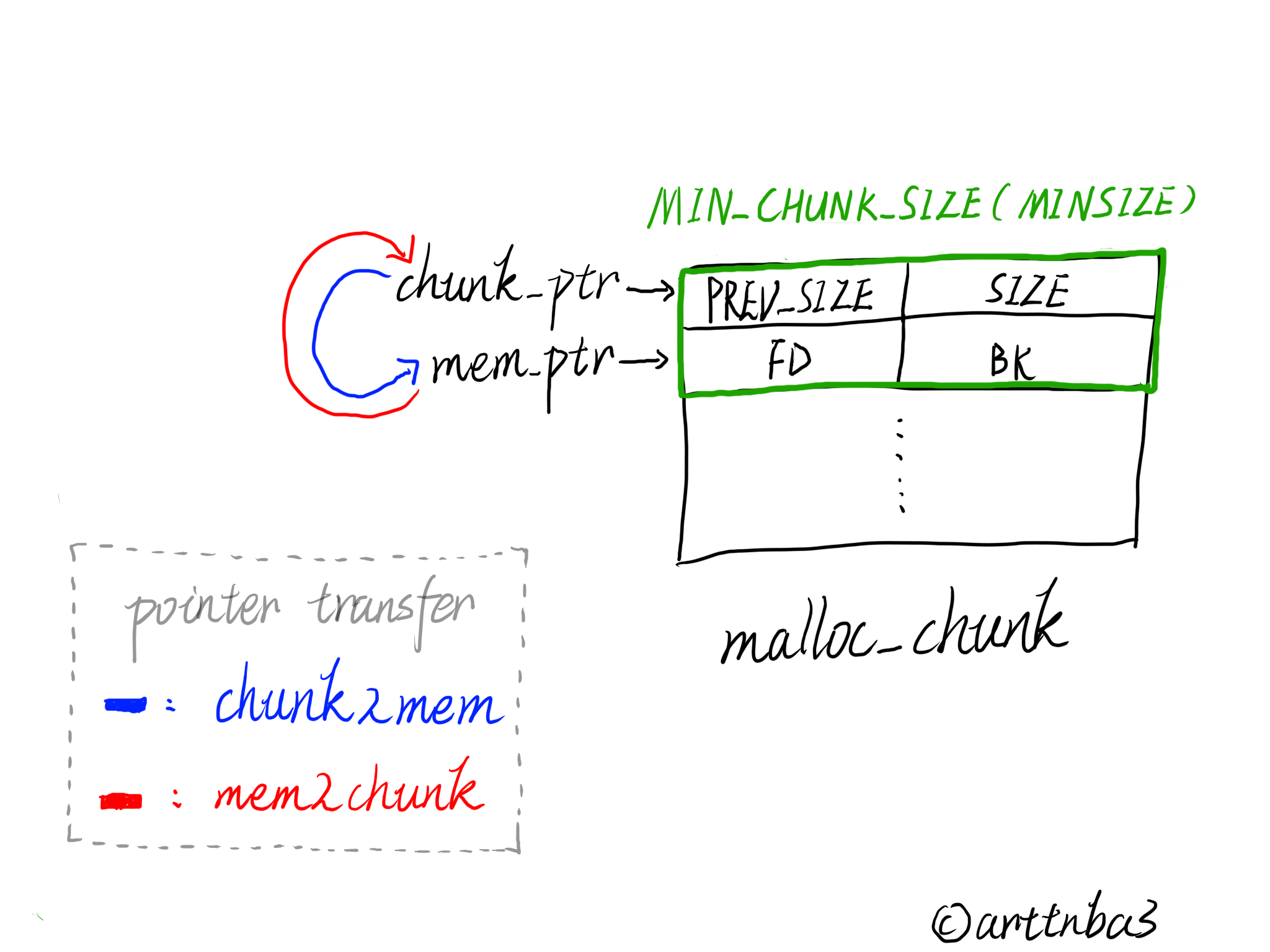
- chunk2mem:将指向chunk的指针转为指向memory的指针,即指针由指向chunk header(刚好是prev_size的位置)移动到指向fd
- mem2chunk:将指向memory的指针转换为指向chunk的指针,即指针由指向fd移动到指向chunk header,与chunk2mem互为逆操作
- MIN_CHUNK_SIZE:所可分配的最小的chunk的size,为由prev_size到fd_nextsize的偏移量,32位下是0x10,64位下是0x20,即一个最小的chunk应当包含有chunk header和fd、bk
- MINSIZE:所能分配的最小chunk的size;我们所能分配的最小的size的chunk应当为一个内存对其的最小的chunk,这里算出来其实就是MIN_CHUNK_SIZE,MIN_CHUNK_SIZE加上MALLOC_ALIGN_MASK以后再和做了取反操作的MALLOC_ALIGN_MASK做与运算猜测实际上是为了消除掉标志位
- aligned_OK:该宏用以检查是否与MALLOC_ALIGNMENT对齐,因为若是与MALLOC_ALIGNMENT不对其的话,其与MALLOC_ALIGN_MASK进行与运算的结果必然不为0(这里应该就不需要我再说明为什么了…)
- misaligned_chunk:该宏用以检测一个chunk是否为未对齐的chunk,若是则返回未对齐的字节数
简单的图示如下:
宏:offsetof
也是一个在很多文件中都有着定义的一个宏,如下:
2
3
4/* Some compilers, like SunOS4 cc, don't have offsetof in <stddef.h>. */
#ifndef offsetof
# define offsetof(type,ident) ((size_t)&(((type*)0)->ident))
#endif该宏的作用是求出某个类型中某个成员的偏移,大致过程如下:
- 将0转换为指向某个类型的指针
- 取地址符取出0->ident的地址
- 转换成size_t类型
由于是以0作为地址基底来取地址的,因此便可以很方便地计算出某个成员的偏移
2.memory request相关宏
接下来这些宏用以对请求的堆块大小进行检查,代码如下:
1 | |
大致如下:
- REQUEST_OUT_OF_RANGE:宏如其名,用以检查用户请求的内存大小是否大于规定的最大内存大小,这个值被定义为4字节整型能表示的最大值再减去两个最小chunk的size所求得的值,为的是避免当有人真的尝试去分配了这样的一个大chunk时malloc内部将这个值加上MINSIZE后会发生整型上溢而变成0附近的一个较小的值
- request2size:作用是将用户请求的内存大小转换为内存对齐的大小,这个转换后的大小便是实际分配给用户的chunk的size;若是请求的内存大小小于MINSIZE得到的size直接为MINSIZE,否则则会得到一个与MALLOC_ALIGNMENT对齐的chunk size
- checked_request2size:可以理解为request2size宏封装上了size检查的宏,需要注意的是若是REQUEST_OUT_OF_RANGE则该宏则会在设置errno标志位为ENOMEM后直接return 0,终止其调用函数的执行
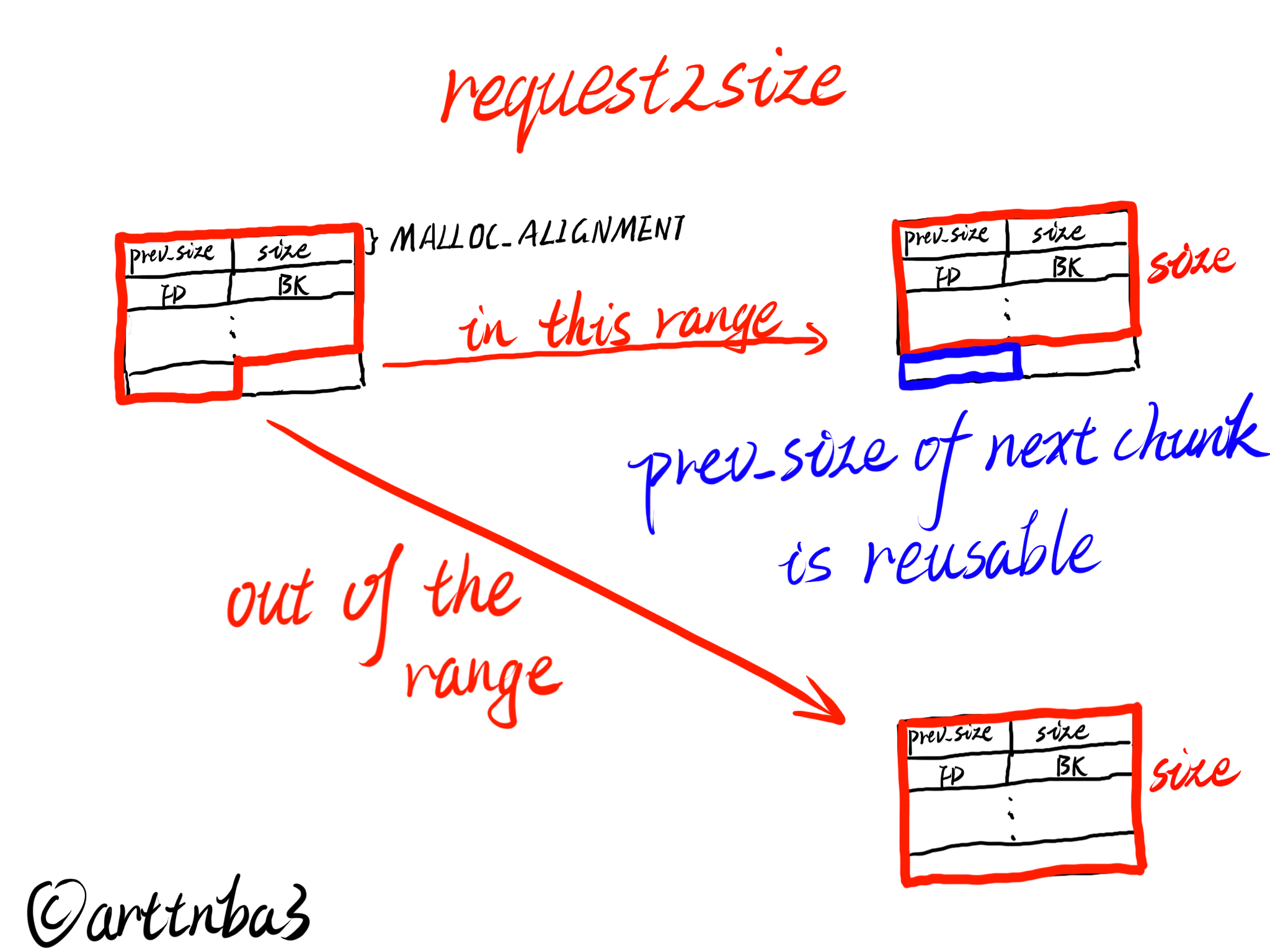
关于chunk间的内存复用及request2size计算相关事项
众所周知·,ptmalloc在组织各chunk时允许一个chunk复用其物理相邻的下一个chunk的prev_size字段作为自己的储存空间,这也是为什么当一个chunk的物理相邻的前一个chunk处在被分配状态时该chunk的prev_size字段无效的原因,大致图示如下:
因此,基于这样的一种空间复用的思想,request2size宏计算出来的size便如图右侧所示了
3.chunk标志位相关宏
①标志位定义及相关宏
我们知道对于一个malloc_chunk而言其size字段应当与MALLOC_ALIGNMENT对齐,而在这样的情况下一个chunk的size字段的低3/4(32/64位系统)位将会永远为0,无法得到充分的利用,因此出于能压榨一点空间是一点空间的思想一个chunk的size字段的低三位用以保存相关的三个状态,代码如下:
1 | |
从低位到高位依次如下:
- PREV_IN_USE:该chunk内存物理相邻的上一个chunk是否处于被分配状态
- IS_MAPPED:该chunk是否是由mmap()进行内存分配得到的
- NON_MAIN_ARENA:该chunk是否是一个不属于main_arena的chunk
因而有三个用以检测标志位的宏:prev_inuse()、chunk_is_mapped、chunk_non_main_arena(),这里便不再过多赘叙了
②标志位操作相关宏及其他宏
malloc.c中这些宏的代码如下:
1 | |
大致如下:
- SIZE_BITS:该宏用以表示三个标志位全为1
- chunksize ():该宏用以清除size字段的标志位,得到原始的chunk size
- next_chunk ():该宏用以获得指向该chunk的物理相邻的下一个chunk的指针
- prev_chunk ():该宏用以获得指向该chunk的物理相邻的上一个chunk的指针,需要注意的是prev_size字段必须有效,即上一个chunk必须为free状态
- chunk_at_offset ():该宏用以将ptr + offset位置作为一个chunk来对待,获得一个指向ptr + offset位置的chunk指针(大意是假设ptr + offset上有一个chunk,然后我们用这个宏得到指向这个chunk的chunk指针,后面讲到top_chunk时会用到)
- inuse()、set_inuse()、clear_inuse ():检测、设置、清除chunk的PREV_INUSE标志位
- inuse_bit_at_offset()、set_inuse_bit_at_offset()、clear_inuse_bit_at_offset ():将ptr + offset位置视为一个chunk并检测、设置、清除该chunk的PREV_INUSE标志位
- set_head_size ():该宏用以在不改变标志位的情况下改变一个chunk的size字段
- set_size ():该宏用以改变一个chunk的size字段,是前者的简化版本
- set_foot ():该宏用以在将ptr + s视为一个chunk的地址的情况下将这个chunk的prev_size字段置为s
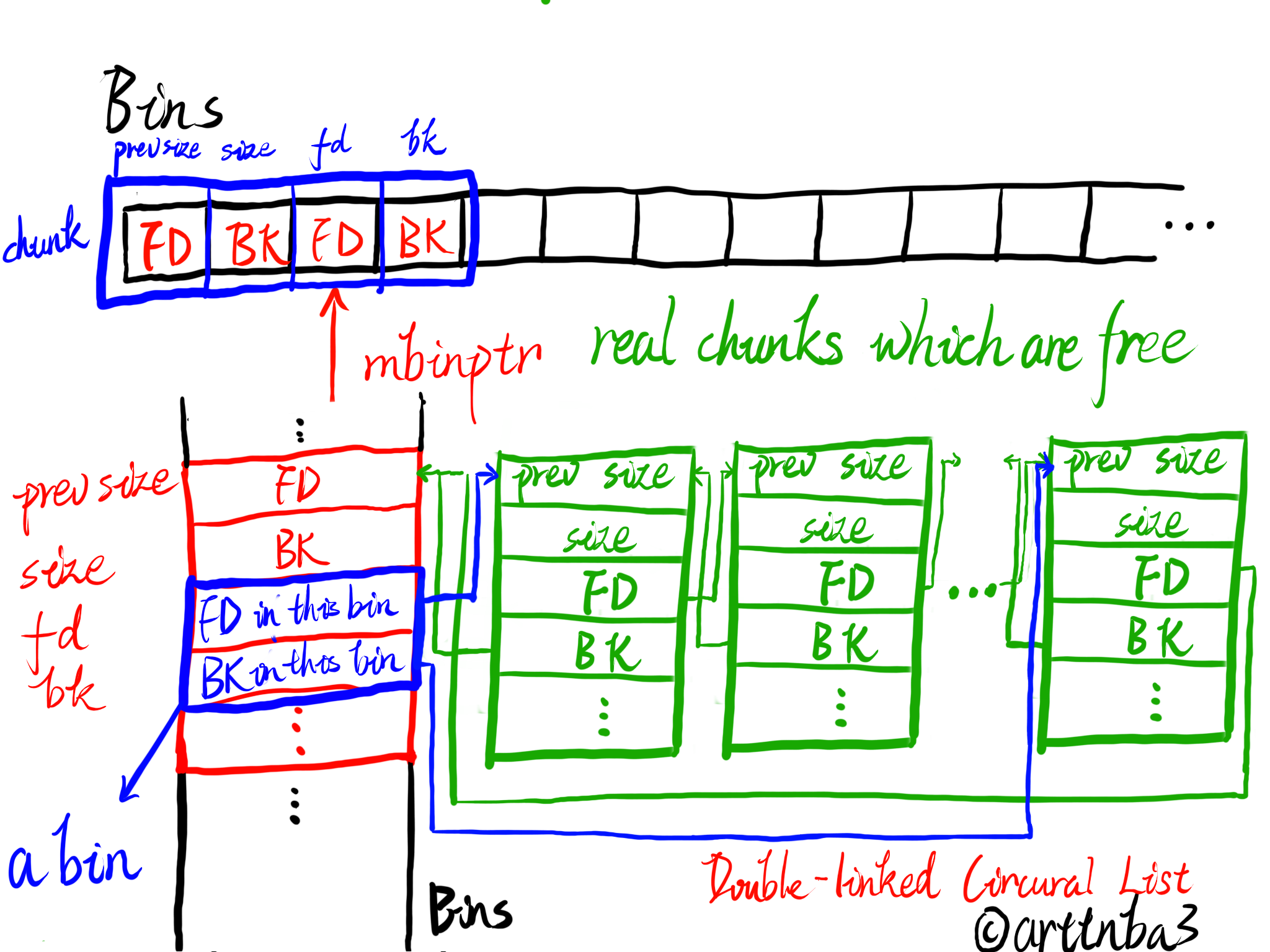
三、Bins:存放闲置chunk的数组
对于闲置的chunk,ptmalloc会根据size的不同将之存放到不同的bins中进行统一的调度,而不会马上返还给系统,这样一来在用户再次进行请求时,ptmalloc便可从bins中挑选出合适的chunk给予用户,这样一来便能大幅度地减少系统调用的次数及其带来的巨大开销
malloc.c中对于bins的说明如下:
1 | |
大意是说bins是一个用以存放闲置的chunk的数组,chunk按照size来存放在不同的下标的bin中,每个bin中的chunk都是使用双向链表进行链接的
一共有着128个bin,其中对于small size chunk而言其存放于存放着相同size的chunk中,因此其每个bin内也就不需要排序,但这也有助于更大的chunk达到最佳的分配机制
被free的chunk会放置于双向链表的头部,而在分配chunk时则是从链表的尾部取chunk,即bin中的chunk链表采取FIFO机制
为了简化双向链表的使用,每一个bin header都被如同malloc_chunk一般使用,同时为了节省空间,在chunk中仅会使用FD/BK字段
同时还typedef了一个mbinptr类型,为指向malloc_chunk结构体的指针
在ptmalloc中bins数组中的bin一共可以划分为三类:unsorted bin、small bin、large bin,将会在后面进行说明
1.bins通用宏
malloc.c中定义了一些和bins相关的宏,如下:
1 | |
- bin_at:取出位于下标 i 的bin chunk,需要注意的是在这里获得的指针为原始存在bin中的指针再减去了chunk header的大小所得到的值,这是由于在bins数组中存放的为fd/bk,需要减去chunk header的大小才能获得一个指向chunk的指针而不是指向mem的指针;从这里我们也可以看出一个bin占据bins数组两格的空间
- next_bin:获取下一个bin
- first && last:获得bin chunk的fd/bk
简单的简析一下关于bin_at宏的这样一个看起来迷惑的操作:Bins数组中的每一个bin都被视作free chunk构建的双向循环链表中的一个特殊的chunk,而每个bin会在数组中存放FD && BK,同时将物理相邻的上一个bin空间复用作为自己的chunk header
关于bin chunk的内存复用思想如下图所示:
同时有一个宏用以根据chunk的size获取相对应的bin下标,笔者在后面会展开讲这个宏里面的东西
2.bins相关定义宏
如下:
1 | |
对于装载着size小于512(0x200)的chunk的bin而言,每个bin中都存放着相同大小的chunk,而存放更大size的chunk的bin(large bin)中每个bin中chunk的大小并不一致,而是处于一定范围内,被分为7组,(32位下)每组bin中chunk size间公差如上表所示(64位直接 * 2即可)
同时,bin 0不存在,bin 1则是一个无序的链表(unsorted bin)
宏定义了NBIINS为128,也就是说理应有着128个bin存放不同类型的chunk,但是bin 0 不存在,因此实际上只有127个bin,在后续arena的定义中我们也能看出这一点
①unsorted bin相关宏
如下:
1 | |
对于在chunk分割过程中所剩余的chunk、以及所有回归闲置的chunk都会首先被存放在unsorted bin当中;当调用malloc时其中的chunk会有机会被放回到常规的bins中;因此通常情况下unsort bin就像一个队列一样,在free/malloc_consolidate中chunk会被放置其中,而在malloc时其中的chunk又会被重新拿走;unsorted bin中的chunk永远不会设置NON_MAIN_ARENA标志位
同时我们也可以得知对于存放在unsorted bin中的chunk的size并没有做限制
定义了宏unsorted_chunks()用以获得unsorted bin,我们可以看到unsorted bin在bins数组中占用了下标0与下标1,也就是说其为bins中的第一个bin
②small bins相关宏
bin 0不存在, 而bin 1 是unsorted bin, 故small bins应当从bin 2 开始存放
相关宏如下:
1 | |
- NSMALLBINS:small bins位于bins下标的终止,即从bin1开始到bin63一共62个bin是属于small bins的,这里需要注意的是不要直接理解为small bins的数量,后面会说明为什么是62个
- SMALLBIN_WIDTH:每个 small bin 之间所储存的chunk的size差值
- SMALLBIN_CORRECTION:查阅了一下
指谷歌,有一种说法是这个宏是用以检查bin是否被破坏的,若被破坏则针对后续的下标相关操作进行修正这个宏一般来说都为0所以我也不懂有什么用,大概可以直接忽视掉,嗯x - MIN_LARGE_SIZE:最小的large bin范围内的chunk的size,只有小于这个size的chunk才属于small bin的范围内,32位下为512,64位下为1024
- in_smallbin_range ():用以检查一个chunk的size是否属于small bin范围内
- smallbin_index ():用以获得一个small bin chunk处在bin中的index,由于bin 1是unsorted bin所以直接进行移位操作即可获得index
通过MIN_LARGE_SIZE我们可以知道最大的small bin的size在32位下为504, 64位下为1008(减去了一个MALLOC_ALIGNMENT),由此我们便可以得出small bins的数量为62
③large bins相关宏
如下:
1 | |
- largebin_index_32() && largebin_index_64 ():一般情况下用以获取large bin chunk位于bin中的index
- largebin_index_32_big ():若是在32位下MALLOC_ALIGNMENT为16时才会启用的特殊宏用以获取index,这是因为常规情况下32位下MALLOC_ALIGNMENT为8,若是扩大到16的话自然计算large bin的index的策略也要改变
- largebin_index ():对前面三个宏的封装,用以获取large bin chunk位于bin中的index
可以看得出来,相较于small bin而言,由于large bin采用了更为特殊的策略,故其获取index的过程也更为复杂,具体可以参见这一节开头先前的关于large bin size的说明
通过这些宏定义我们也可以算出一共有63个large bin
3.unlink:从bins中取出chunk
由于从各种bins中取出一个chunk的操作十分频繁,若是使用函数实现则会造成较大的开销,故unlink操作被单独实现为一个宏,如下:
1 | |
大致的一个流程如下:
- P为要被unlink的chunk,FD、BK则是chunk:P->fd与P->bk
- 检查FD->bk与BK->fd是否都指向P,若否,则输出错误信息
- 将FD->bk指向BK,将BK->fd指向FD,这个时候这个chunk便已经不在该bin的双向循环链表中了
- 若是chunk size位于small bin的范围内,则unlink结束,否则标志着此时chunk的fd_nextsize与bk_nextsize字段是启用的,需要接着将之从nextsize链表中unlink(large bin特有)
- 检查P->fd_nextsize->bk_size与P->bk_nextsize->fd_nextsize是否指向P,和前面的过程类似这里便不再赘叙
- 若FD->fd_nextsize不为NULL,则将P从其所处nextsize链表中unlink
- 若FD->fd_nextsize为NULL时,若P->fd_nextsize指向自身,则将FD->fd_nextsize与FD->bk_nextsize都指向FD(代表该chunk不属于任何一个nextsize链表?),否则使用FD替换掉P所在的nextsize链表中的位置
大致过程如下图所示
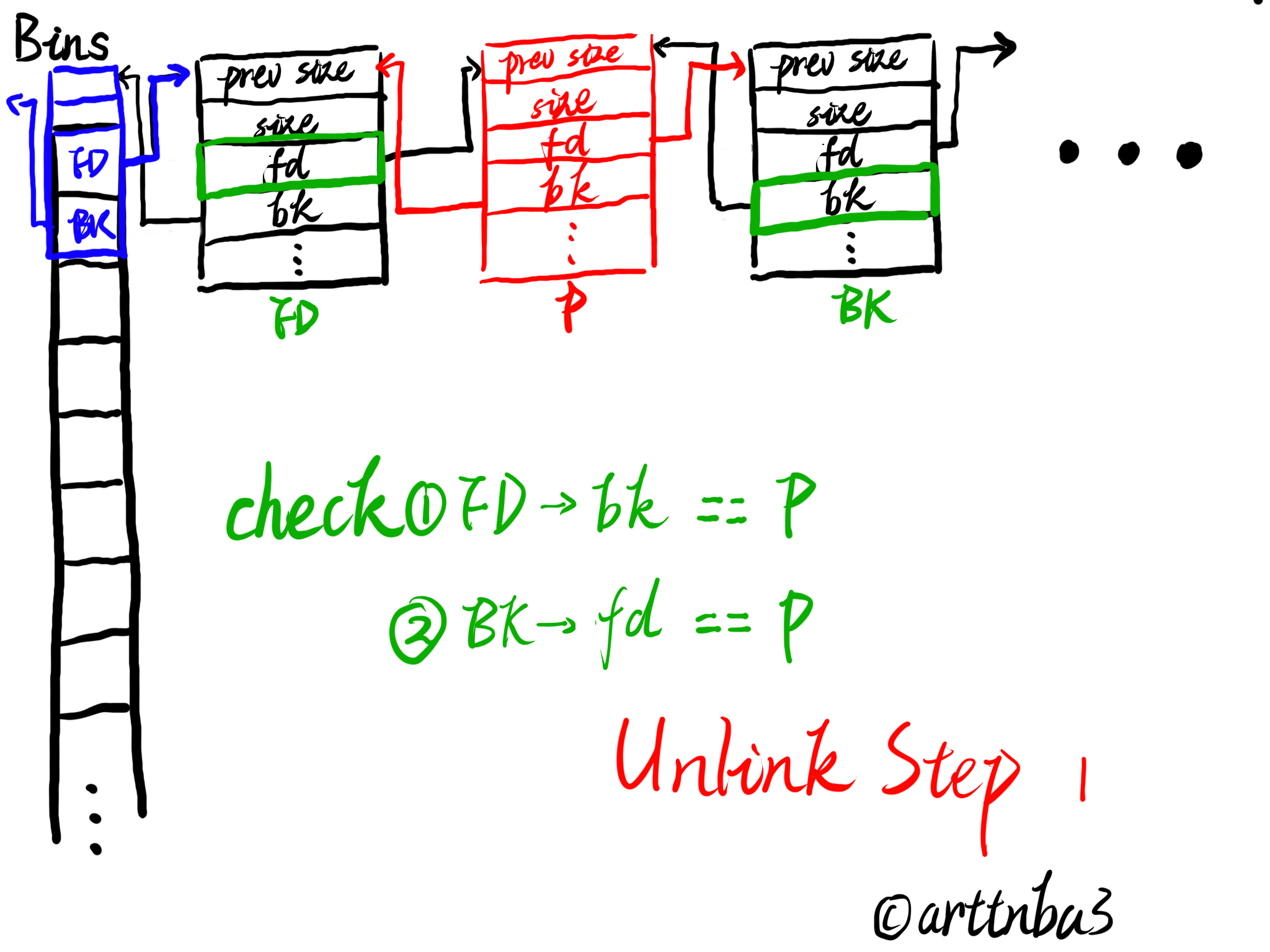
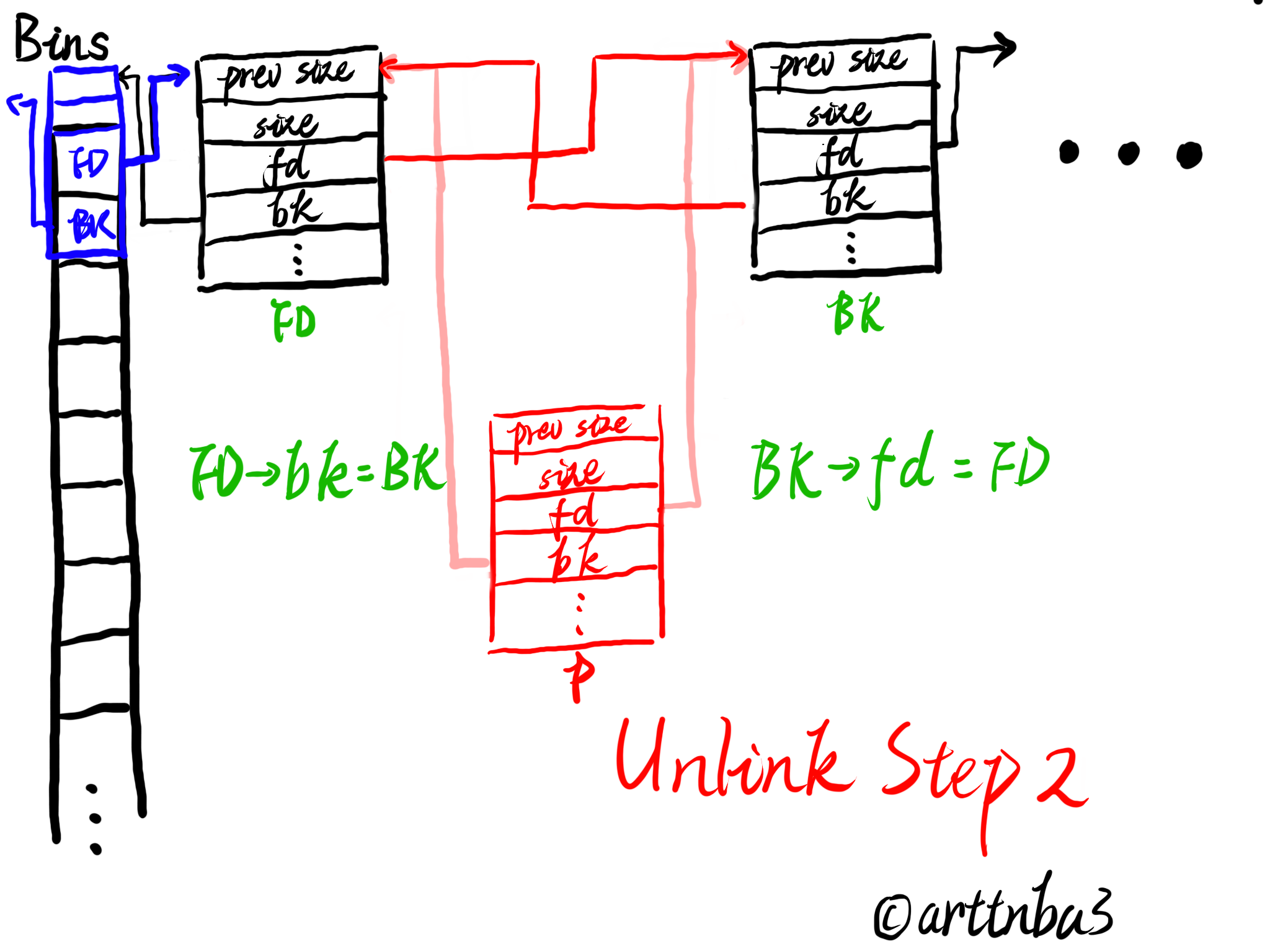
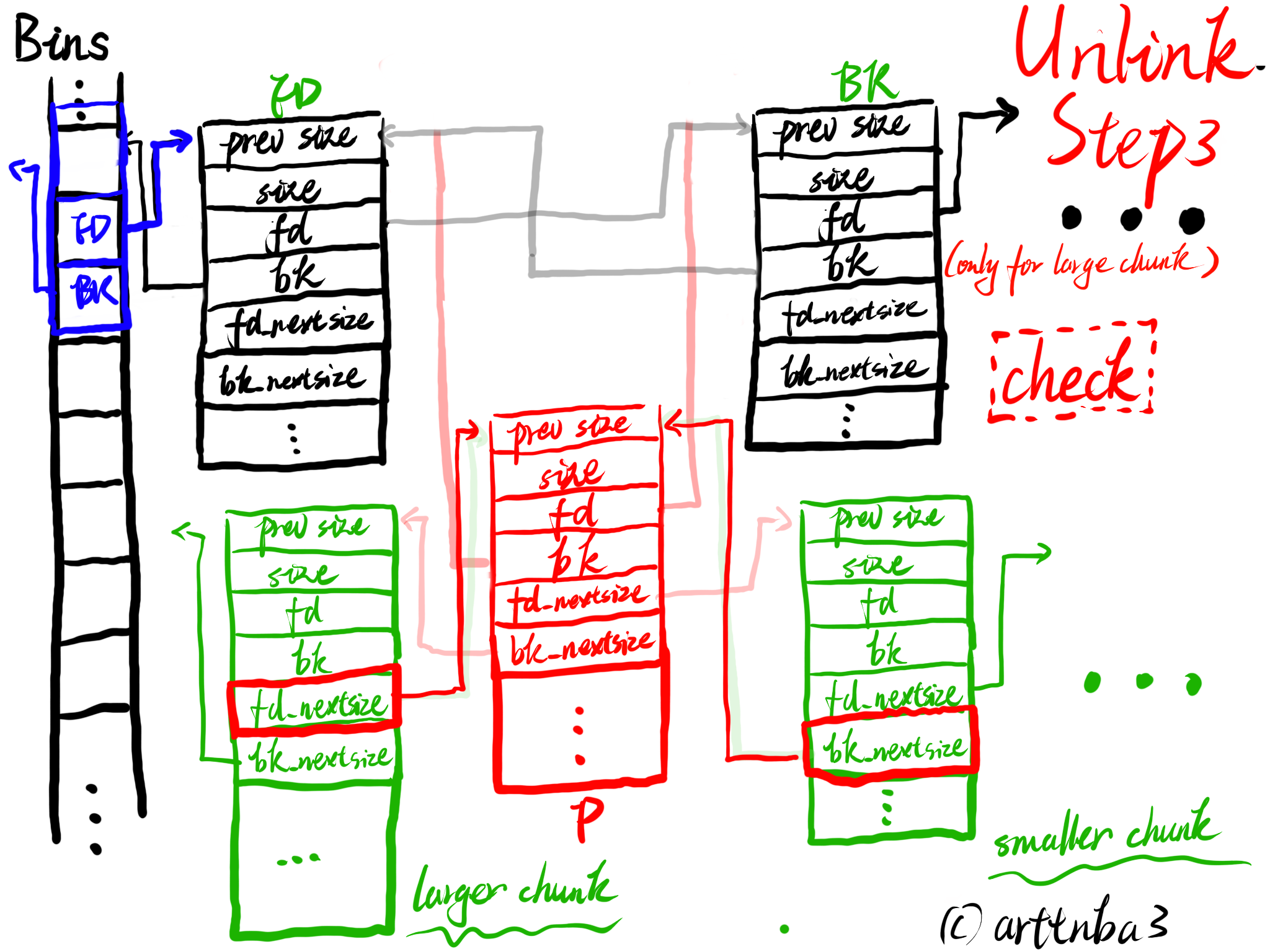
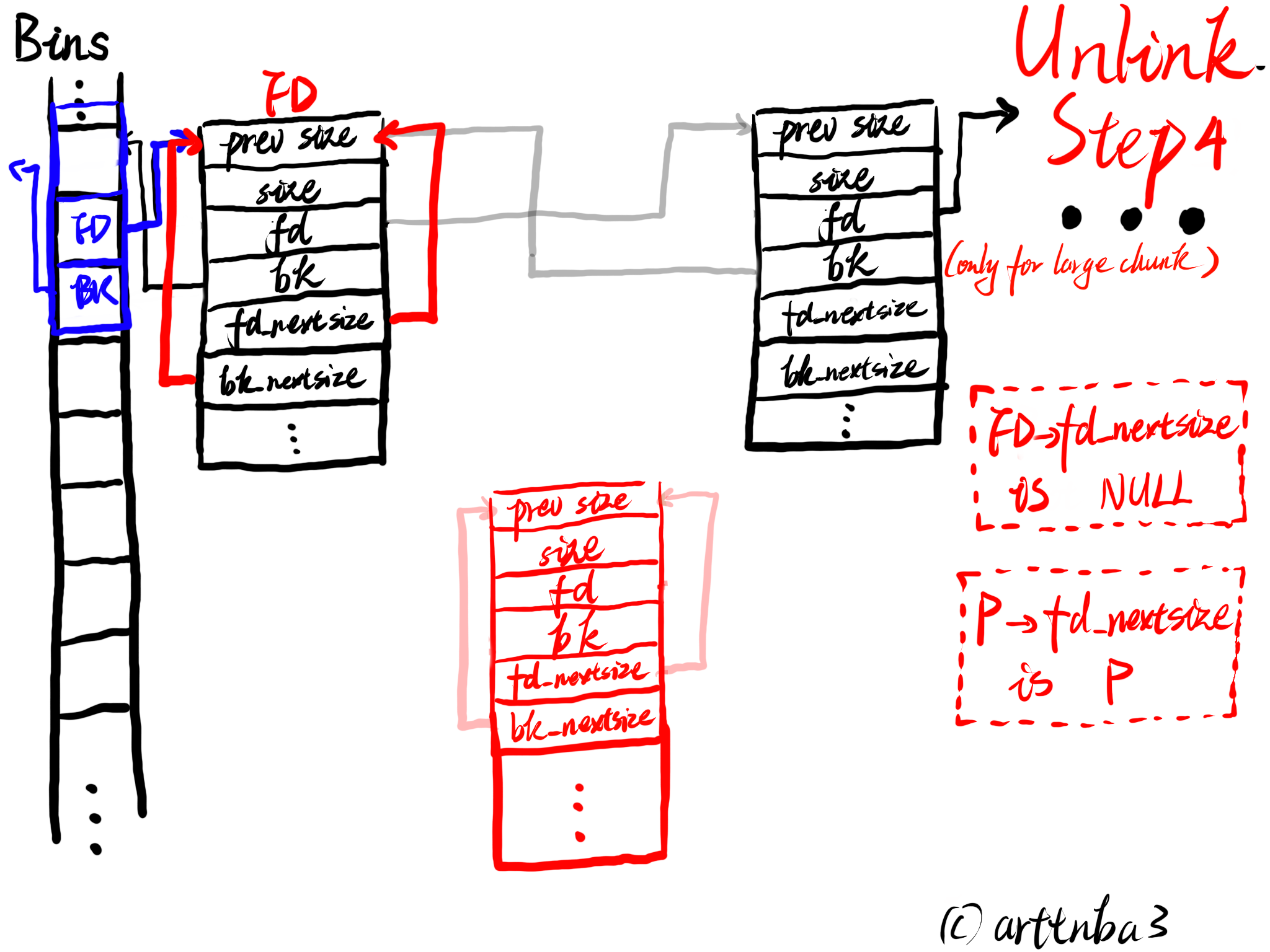
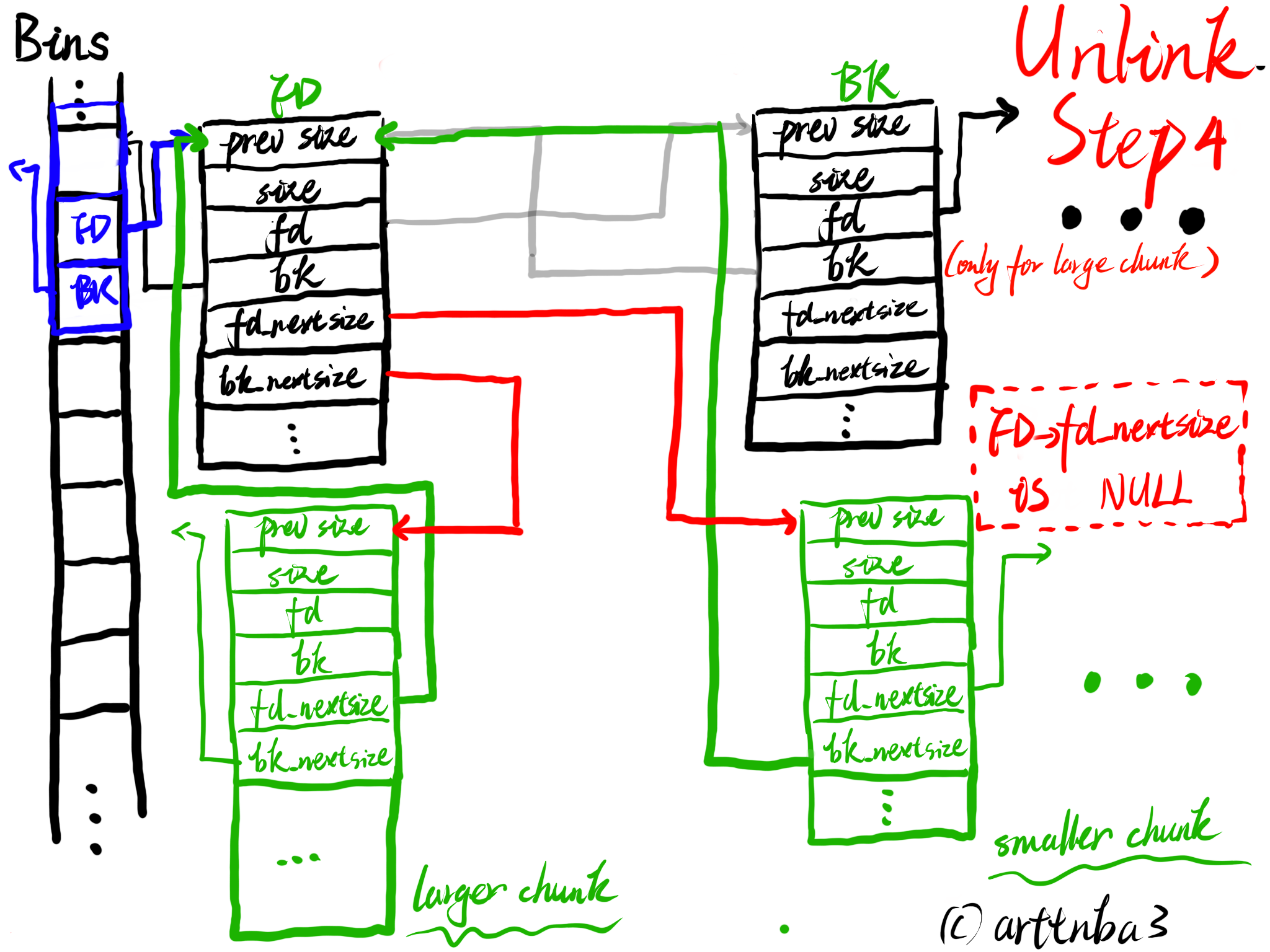
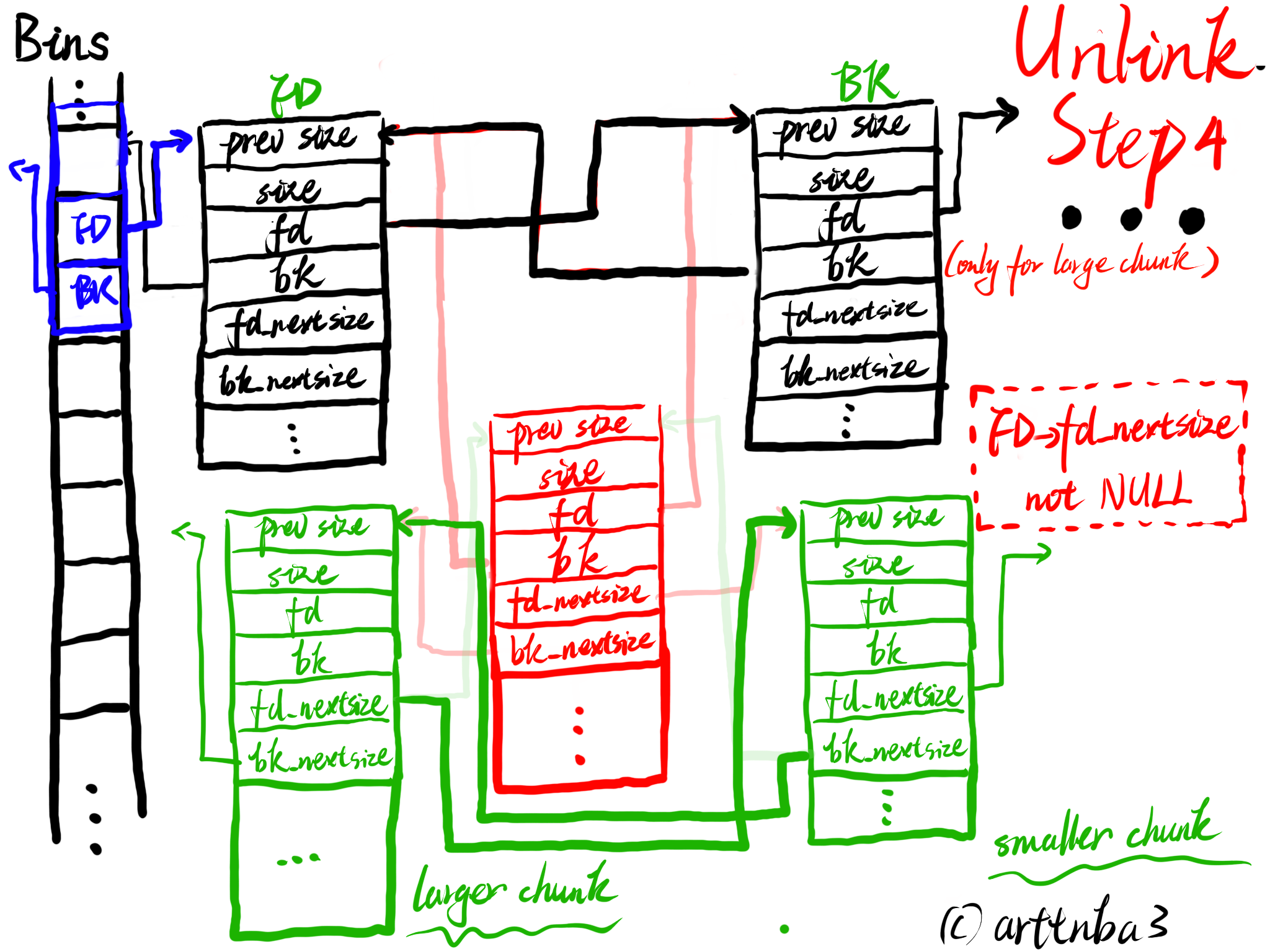
unlink操作应该是我在0x00中画图最多的一部分了…
__builtin_expect(expr, var):分支预测优化
gcc的分支预测优化代码,如下:
2
3
4
5/* Tell the compiler when a conditional or integer expression is
almost always true or almost always false. */
#ifndef HAVE_BUILTIN_EXPECT
# define __builtin_expect(expr, val) (expr)
#endif该代码用于编译器分支预测优化,当expr的值在大部分情况下都为var时,便可以使用该宏,编译器会针对该分支预测进行相应的优化
malloc_printerr()
定义于malloc.c中的一个函数,代码如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26static void
malloc_printerr (int action, const char *str, void *ptr, mstate ar_ptr)
{
/* Avoid using this arena in future. We do not attempt to synchronize this
with anything else because we minimally want to ensure that __libc_message
gets its resources safely without stumbling on the current corruption. */
if (ar_ptr)
set_arena_corrupt (ar_ptr);
if ((action & 5) == 5)
__libc_message (action & 2, "%s\n", str);
else if (action & 1)
{
char buf[2 * sizeof (uintptr_t) + 1];
buf[sizeof (buf) - 1] = '\0';
char *cp = _itoa_word ((uintptr_t) ptr, &buf[sizeof (buf) - 1], 16, 0);
while (cp > buf)
*--cp = '0';
__libc_message (action & 2, "*** Error in `%s': %s: 0x%s ***\n",
__libc_argv[0] ? : "<unknown>", str, cp);
}
else if (action & 2)
abort ();
}首先检查arena指针是否为空,若否则设置arena被破坏的标志位
随后根据action的不同的值做出不同的决策:
- 5:直接输出错误信息
- 1:声明了一个buf数组用以存储地址信息,随后输出错误信息
- 2:直接调用abort()函数终止程序
__libc_message()函数用于输出错误信息,该函数定义于sysdeps/posix/libc_fatal.c中,由于不是本篇文章的重点故不作详细说明
abort()函数定义于stdlib/abort.c中,用以终止程序并把core给dump下来,这里也不再深入说明
4.binmap:用来标识bin状态(是否为空)的数组
我们先来看malloc.c中对于binmap的说明如下:
1 | |
大意是说由于bins的数量过多,故ptmalloc在bin的遍历查找中使用一种称之为binmap的一级索引结构。binmap使用「位向量」来标记bins数组中的每一个bin,以便于能够快速遍历bins。
在一个bin被置空时其binmap内对应的标志位并不会被立即清空,只会在下次重新遍历时重新置位
binmap的设计思想是充分利用每一位来进行bin状态的标记
首先定义了三个宏:
- BINMAPSHIFT:binmap中一个map的计数量的移位数
- BITSPERMAP:binmap中每个map所储存的bit数,同时也是一个map所对应的bins数,为32
- BINMAPSIZE:binmap的大小,在这里可以看出来binmap中map的数量是根据bins的数量来计算的,为4
binmap在ptmalloc中是unsigned int类型,32位&&64位下都是4字节,由此我们便可以得出binmap的大致结构应当如下图所示:
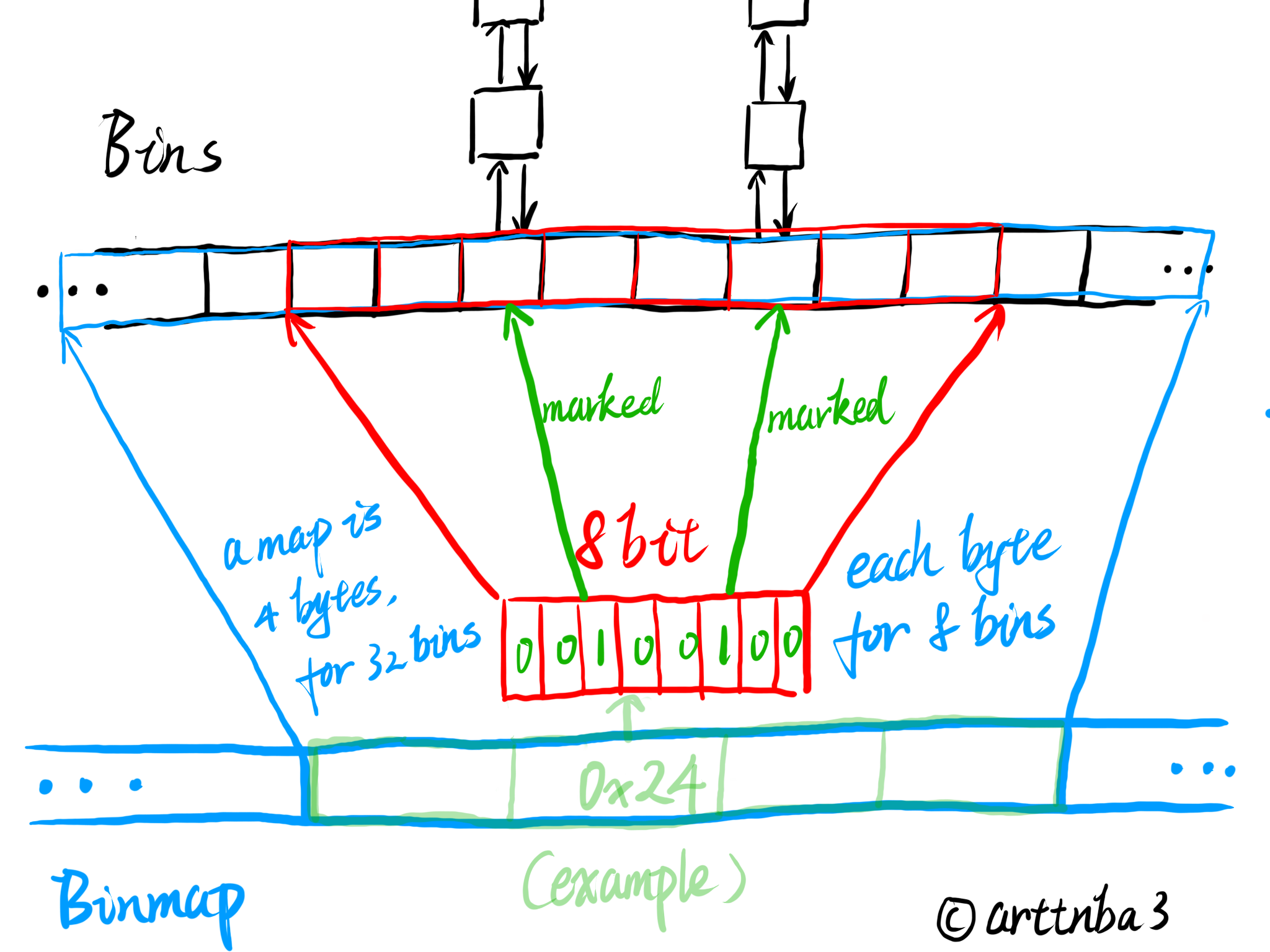
由此还定义了如下宏:
idx2block ():由bin对应bins数组的index获取其对应的binmap中的map的index(0~3)
idx2bit ():由bin对应bins数组的index获取其对应的binmap中的map的bit(该值应为2^n,n为[0, 31]中任一整数)
mark_bin ():在binmap中标记该bin为非空(设该bit为1)
unmark_bin ():在binmap中标记该bin为空(设该bit为0)
get_binmap ():获得一个bin在binmap中的标记位的原始值
不过我们还需要注意的一点便是:fastbin不使用binmap标志位,fastbin是专门用以存储小chunk的独立于bins数组之外的bins数组,设计的目的是提高chunk的使用效率,下面我们就来讲讲fastbin
四、Fastbins:快速存取chunk的数组
虽然我们在前面讲到在ptmalloc中使用Bins数组储存闲置的chunk,但是由于大部分程序都会频繁地申请以及释放一些较小的chunk,若是我们将大部分的时间都花在合并chunk、分割chunk、繁复的安全检查上,则会会大大地降低堆的利用效率,故ptmalloc独立于Bins之外单独设计了一个Fastbin用以储存一些size较小的闲置chunk,说明如下:
1 | |
Fastbins是一个用以保存最近释放的较小的chunk的数组,为了提高速度其使用单向链表进行链接
Fastbin采取FILO/LIFO的策略,即每次都取用fastbin链表头部的chunk,每次释放chunk时都插入至链表头部成为新的头结点,因而大幅提高了存取chunk的速度
Fastbin中的chunk永远保持在in_use的状态,这也保证了她们不会被与其他的free chunk合并
malloc_consolidate()函数将会清空fastbin中所有的chunk,在进行相应的合并后送入普通的small bins中
fastbin相关宏
malloc.c中同样定义了一些与fastbin相关的宏,如下:
1 | |
fastbin ():从一个arena中获取其fastbin数组相应下标的bin
fastbin_index ():根据chunk的size获取其应当处于的fast bin的index,在这里我们可以发现一点是fastbin计算index时是通过移位操作进行的,即标志位的不同对于fastbin index的计算并没有影响,这也是为什么我们在fastbin attack时能够利用malloc_hook - 0x23位置上的0x7f这个值分配到一个fake chunk的原因(后续会在malloc中说明fastbin相关的安全检查)
MAX_FAST_SIZE:【定义上的】最大的fastbin chunk的size,超过这个size的chunk都将会被送入unsorted bin中;32位系统下为0x50,64位系统下为0xA0
NFASTBINS:Fastbins中bin的数量,简单计算一下便可知32位下NFASTBINS为11,64位下NFASTBINS为10
fastbin size详解
需要注意的是虽然说定义了一个MAX_FAST_SIZE宏说明fastbin最大支持的size,但其实fastbin数组中的bin 7、8、9都是用不上的,这是因为fastbin chunk真正的size范围是由如下宏进行定义的
1 | |
- global_max_fast:fastbin chunk size最大值
- set_max_fast ():设置global_max_fast,若为0则初始化为SMALLBIN_WIDTH
- get_max_fast ():获取global_max_fast
而在malloc_init_state()函数中初始化fastbin chunk的max size为DEFAULT_MXFAST,而不是MAX_FAST_SIZE,在后面的部分我们会详细解析这个函数
1 | |
DEFAULT_MXFAST定义如下:
1 | |
也就是说32位下最大的fastbin chunk size为0x40, 64位下最大的fastbin chunk size为0x80,超过这个范围的chunk在free之后则会被送入unsorted bin中
五、malloc_par:堆管理器参数
在ptmalloc中使用malloc_par结构体来记录堆管理器的相关参数,该结构体定义于malloc.c中,如下:
1 | |
主要是定义了和mmap和arena相关的一些参数(如数量上限等),以及sbrk的基址
mp_:记录ptmalloc相关参数的malloc_par结构体
该静态结构体用以记录ptmalloc相关参数,同样定义于malloc.c中,如下:
1 | |
宏再展开的代码就不贴了,大概做了以下几件事:
- 设置了
top_pad为 0 - 设置了
n_maps_max为 65535 - 设置了
mmap_threshold为 128 * 1024 - 设置了
trim_threshold为 128 * 1024 - 设置了
arena_test在gcc中32下为2,64位下为8(不同的编译器中long的长度可能不同,这里仅以gcc为例)
六、heap_info:Heap Header(for heap allocated by mmap)
该结构体类型定义于arena.c中,如下:
1 | |
heap_info位于一个heap块的开头,用以记录通过mmap系统调用从Memory Mapping Segment处申请到的内存块的信息
heap_info之间链接成一个单向链表
其中有一个mstate类型,定义于include/malloc.h中:
1 | |
也就是说mstate其实是指向malloc_state结构体的指针的typedef别名,即指向arena的指针
结合注释我们可以得出heap_info结构体的成员如下:
- ar_ptr:指向管理该堆块的arena
- prev:该heap_info所链接的上一个heap_info
- size:记录该堆块的大小
- mprotect_size:记录该堆块中被保护(mprotected)的大小
- pad:即padding,用以在SIZE_SZ不正常的情况下进行填充以让内存对齐,正常情况下pad所占用空间应为0字节
那么我们可以得出使用mmap系统调用分配的一个heap的结构应当如下:
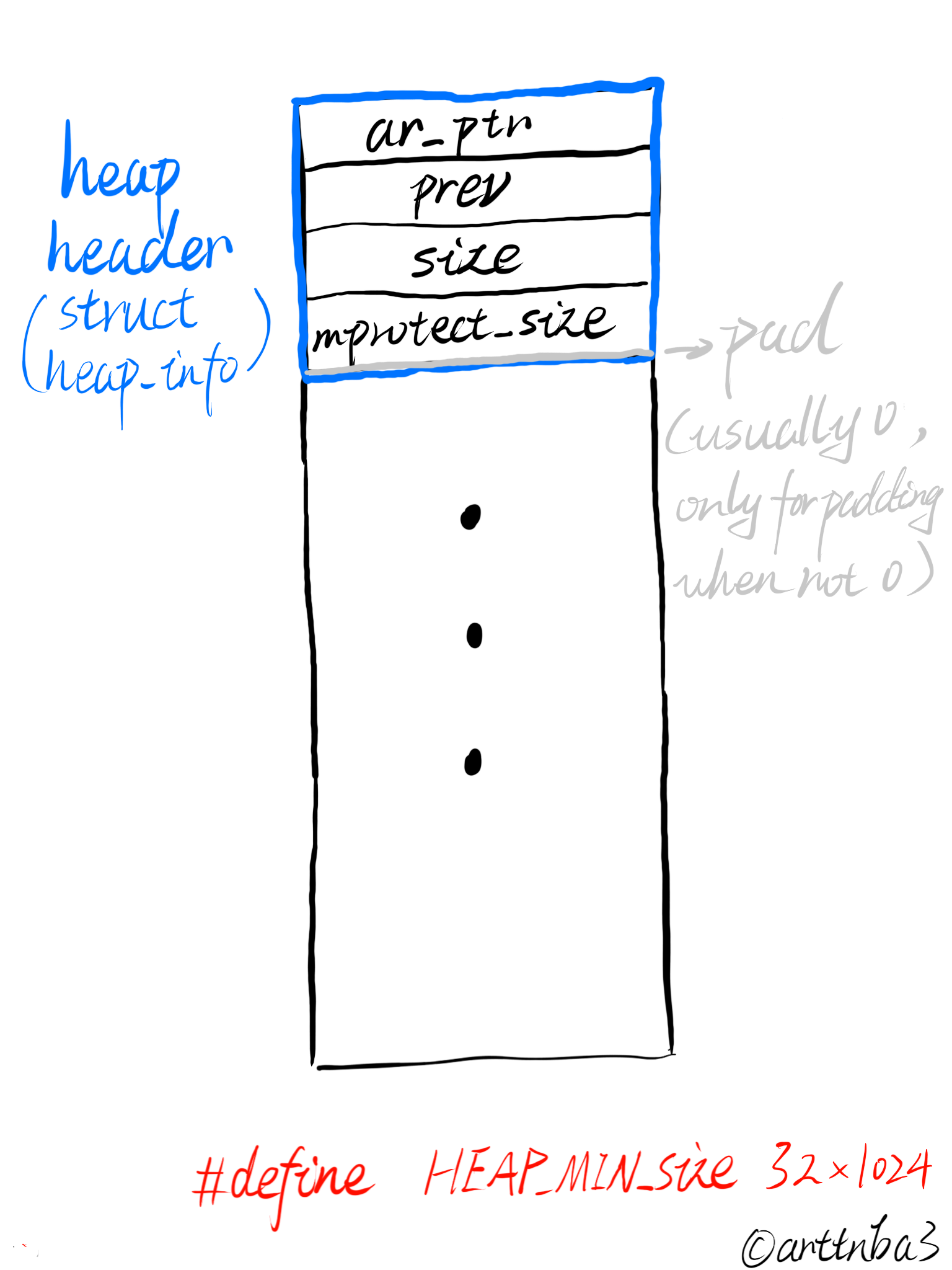
更多的会在后续讲到相关函数时说到
heap_info相关宏
arena.c中还定义了一些相关的宏,如下:
1 | |
HEAP_MIN_SIZE:用mmap所分配的堆块的最小大小,应当为
32 * 1024HEAP_MAX_SIZE:用mmap所分配的堆块的最大大小,这个值由
DEFAULE_MMAP_THRESHOLD_MAX宏决定,该宏定义于malloc.c中,如下:
1 | |
__WORDSIZE宏所获取的是字长的位数,定义于sysdeps/x86/bits/wordsize.h下,这里便不再赘叙
那么我们便可以得知在32位下mmap所分配的堆块的最大大小应当为2 * 512 * 1024,64位下应当为2 * 4 * 1024 * 1024 * (sizeof(long))
由于使用mmap分配的堆块的大小是对于HEAP_MAX_SIZE对齐的,故通过此特点可以通过指向堆块上某位置的指针直接获取到一个指向该堆块的指针,因此也定义了相关宏,如下:
1 | |
该宏用以通过一个指向某堆块上某位置的指针获取到指向该堆块的指针
七、arena:线程内存池
从最小的chunk开始自底向上分析现在终于到了分析arena的源码的时候,arena这个词直译是“竞技场”的意思,wsm要起这种奇怪的名字我也不知道,可能是因为听起来比较帅气吧,按照笔者的理解,arena在ptmalloc中用以表示「单个线程独立维护的内存池」,这是由于大部分情况下对于每个线程而言其都会单独有着一个arena实例用以管理属于该线程的堆内存区域,包括Bins、Fastbin等其实都是被放置在arena的结构体中统一进行管理的
在malloc.c中对于ptmalloc的内部数据结构说明如下:
1 | |
ptmalloc内部的内存池结构是由malloc_state结构体进行定义的,即arena本身便为malloc_state的一个实例对象
1.malloc_state结构体
malloc_state结构体定义于malloc/malloc.c中,代码如下:
1 | |
①mutex:互斥锁
从定义中我们不难读出mutex变量即为多线程互斥锁,用以保证线程安全
ptmalloc中有着对多线程的支持
②flags:标志位
接下来是一个整形变量flags,即标志位,用以表示arena的一些状态,如:是否有fastbin、内存是否连续等
flags标志位相关
为了节省空间,glibc充分地使用了用每一位(bit)来表示不同状态的思想,与chunk的size的标志位异曲同工
相关代码如下
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40/*
FASTCHUNKS_BIT held in max_fast indicates that there are probably
some fastbin chunks. It is set true on entering a chunk into any
fastbin, and cleared only in malloc_consolidate.
The truth value is inverted so that have_fastchunks will be true
upon startup (since statics are zero-filled), simplifying
initialization checks.
*/
#define FASTCHUNKS_BIT (1U)
#define have_fastchunks(M) (((M)->flags & FASTCHUNKS_BIT) == 0)
#define clear_fastchunks(M) catomic_or (&(M)->flags, FASTCHUNKS_BIT)
#define set_fastchunks(M) catomic_and (&(M)->flags, ~FASTCHUNKS_BIT)
/*
NONCONTIGUOUS_BIT indicates that MORECORE does not return contiguous
regions. Otherwise, contiguity is exploited in merging together,
when possible, results from consecutive MORECORE calls.
The initial value comes from MORECORE_CONTIGUOUS, but is
changed dynamically if mmap is ever used as an sbrk substitute.
*/
#define NONCONTIGUOUS_BIT (2U)
#define contiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) == 0)
#define noncontiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) != 0)
#define set_noncontiguous(M) ((M)->flags |= NONCONTIGUOUS_BIT)
#define set_contiguous(M) ((M)->flags &= ~NONCONTIGUOUS_BIT)
/* ARENA_CORRUPTION_BIT is set if a memory corruption was detected on the
arena. Such an arena is no longer used to allocate chunks. Chunks
allocated in that arena before detecting corruption are not freed. */
#define ARENA_CORRUPTION_BIT (4U)
#define arena_is_corrupt(A) (((A)->flags & ARENA_CORRUPTION_BIT))
#define set_arena_corrupt(A) ((A)->flags |= ARENA_CORRUPTION_BIT)仅使用了flags的低三位作为标志位,从低位到高位的含义如下:
- 是否不存在fastbin chunk
- 是否不存在连续内存(块)
- arena是否被破坏
并定义了相关的获取&改变标志位的宏
③fastbinY:存放fastbin chunk的数组
首先是fastbin中所用的mchunkptr类型,定义如下:
1 | |
即mchunkptr为指向malloc_chunk结构体的指针套娃everyday,也就是说fastbinY是一个指针数组,用以存放指向malloc_chunk类型的指针
无论是从注释还是从名字中我们都可以知道这个数组便是fastbin
④top:指向Top Chunk的指针
Top Chunk是所有chunk中较为特殊的一个chunk,由于系统调用的开销较大,故一般情况下malloc都不会频繁地直接调用brk系统调用开辟堆内存空间,而是会在一开始时先向系统申请一个较大的Top Chunk,后续需要取用内存时便从Top chunk中切割,直到Top chunk不足以分配所需大小的chunk时才会进行系统调用
关于Top Chunk的相关事宜会在后续分析内存分配机制时详细说明
⑤last_remainder:chunk切割中的剩余部分
malloc在分配chunk时若是没找到size合适的chunk而是找到了一个size更大的chunk,则会从大chunk中切割掉一块返回给用户,剩下的那一块便是last_remainder,其随后会被放入unsorted bin中,相关事宜也会在后续分析内存分配机制时详细说明
⑥bins:存放闲置chunk的数组
这个bins便是我们先前所说的用以存放闲置chunk的指针数组,在这里我们可以看到其一共有NBINS x 2 - 2个元素,即一共有NBINS - 1个bin,也就是127个bin,而bin0不存在,故应当有126个bin,其中包含1个unsorted bin, 62个small bin, 63个large bin
⑦binmap:用以表示binmap的数组
binmap用以标记一个bin中是否有chunk以方便检索,需要注意的是chunk被取出后若一个bin空了并不会立即被置0,而会在下一次遍历到时重新置位
※fastbin不使用binmap标志位※
⑧next:指向下一个arena的指针
一个进程内所有的arena串成了一条循环单向链表,malloc_state中的next指针便是用以指向下一个arena,方便后续的遍历arena的操作(因为不是所有的线程都有自己独立的arena)
⑨next_free:指向下一个空闲的arena的指针
与next指针类似,只不过指向的是空闲的arena(即没有被任一线程所占用),这里便不再赘叙
⑩attached_threads:与该arena相关联的线程数
该变量用以表示有多少个线程与该arena相关联,这是因为aerna的数量是有限的,并非每一个线程都有机会分配到一个arena,在线程数量较大的情况下会存在着多个线程共用一个arena的情况
⑪system_mem:记录当前arena在堆区中所分配到的内存的总大小
该变量用以记录记录当前arena在堆区中所分配到的内存的总大小,似乎只在进行了系统调用brk调整堆区大小时会刷一波存在感
按笔者自己测试64位下这个值似乎是0x21000的整数倍,后面继续分析源码的时候应该会知道为什么
⑫ max_system_mem:记录当前arena在堆区中所分配到的内存的总大小的最大值
当操作系统予进程以内存时,system_mem会随之增大,当内存被返还给操作系统时,sysyetm_mem会随之减小,max_system_mem变量便是用来记录在这个过程当中system_mem的峰值
2.arena相关变量
在malloc/arena.c中定义了arena相关的一些变量,如下:
①thread_arena:每个线程所对应的arena
首先我们先看thread_arena,这是一个定义于arena.c中的变量,如下:
1 | |
不难看出thread_arena是一个静态的每个线程都会有一份的全局变量,类型为mstate,由此我们可以知道的是,在允许的情况下,ptmalloc会为每个线程单独分配一个arena,而每个线程都会有一个thread_arena指针指向自己所用的arena
__thread:线程变量
GCC关键字之一,也是GCC内置的线程局部存储设施,其存储效率近似于全局变量
对于一个被__thread关键字修饰的一个变量而言,每个线程都会独立有一个该变量的实例,线程之间该变量实例的值互不干扰
只能用以修饰POD类型变量、全局变量、静态变量
attribute_tls_model_ie
该宏定义于include/libc-symbols.h下
#define attribute_tls_model_ie __attribute__ ((tls_model ("initial-exec")))是一个attribute,设置了其tls mode为”initial-exec”;该mode可用于优化定义于动态加载库中的线程局部变量,但需要对于该变量的所有引用操作都位于定义该变量的模块中
详见IBM knowledgeCenter - ftls-model
Thread-Local Storage:线程本地存储(TLS)
对于一个进程中的所有线程而言,他们共享着同一个内存空间,因而若存在一全局/静态变量,则所有线程都会共享一份变量实例,当一个线程对其进行修改时,则会同时影响到其他的线程,而结果并不一定是我们想要的
因而就有了TLS的概念——线程本地存储:各个线程独立拥有一个变量实例,相互之间并不影响
__attribute__
GNU C特性,简单来说就是根据函数的不同的功能所决定的返回值而用来优化所生成的代码的,比如说内存分配函数通常会返回一个指向内存块的指针,那么就可以使用__attribute__((malloc))进行优化
详见手册
②narenas:arena数量
该变量用以记录arena的数量,定义于arena.c中,如下
1 | |
该静态变量被初始化为1,即默认一开始便有一个arena(main_arena)
③main_arena:初始主线程arena
main_arena为一个定义于malloc.c中的静态的malloc_state结构体,如下:
1 | |
由于其为libc中的静态变量,该arena会被随着libc文件一同加载到Memory Mapping Segment
④free_list:空闲arena链表(头结点)
free_list同样是一个mstate变量,用以保存空闲arena链表的头节点指针,定义于arena.c中,相关代码如下
1 | |
我们可以看到为了应对多线程操作,free_list同样有着一个对应的互斥锁
⑤ arena_mem:非主线程的arena所占用的内存空间总大小
定义于arena.c中,如下:
1 | |
该变量用以记录非main_arena所分配到的空间的总大小
3.arena相关函数与宏
①malloc_init_state():初始化arena内成员
该函数位于malloc.c中,如下:
1 | |
大概做了以下几件事:
- 将arena中所有bin(fastbin除外)的fd与bk都指向bin自身
- (使用sbrk进行增长的堆区域在内存中为连续区域的情况下若该arena非main_arena则)设置该arena的标志位中的noncontiguous,笔者推测这是由于非主线程arena的内存区域位于由mmap映射的MMS段,一般来说并非连续内存,故设置该标志位,而所管理的内存位于heap区的main_arena则可以通过系统调用sbrk在heap区进行增长,故不设置该标志位(MORECORE_CONTIGUOUS被设为1,即意为sbrk系统调用的堆区内存增长连续(MORECORE为sbrk的封装))
- 若该arena为main_arena则设置set_max_fast为默认值,该值32位下为0x40,64位下为0x80
- 设置标志位FASTCHUNKS_BIT,即一个arena在默认情况下并不拥有fastbin chunk
- 将该areva的top chunk指针指向unsorted bin,用以表示初始时top chunk大小为0
②_int_new_arena():创建一个新的arena
该函数定义于arena.c中,如下:
1 | |
该函数首先会尝试从Memory Mapping Segment区域分配一个大小为size + heap_info + malloc_state + MALLOC_ALIGNMENT + __mp.top_pad的内存块,若失败则重新尝试分配一个大小仅为heap_info + malloc_state + MALLOC_ALIGNMENT + __mp.top_pad的内存块,若仍失败则返回NULL,需要注意的是在new_heap()函数中该值会被自动转换为一个对分页大小对齐的size,若该值小于HEAP_MIN_SIZE(32*1024)则会被自动转换为HEAP_MIN_SIZE,详细会在后续new_heap()函数解析中说明
接下来该函数会将获得的内存块从heap header往后的一块大小为malloc_state的区域当作是一个新的arena来继续操作
也就是说此时该内存块的布局应当如下:
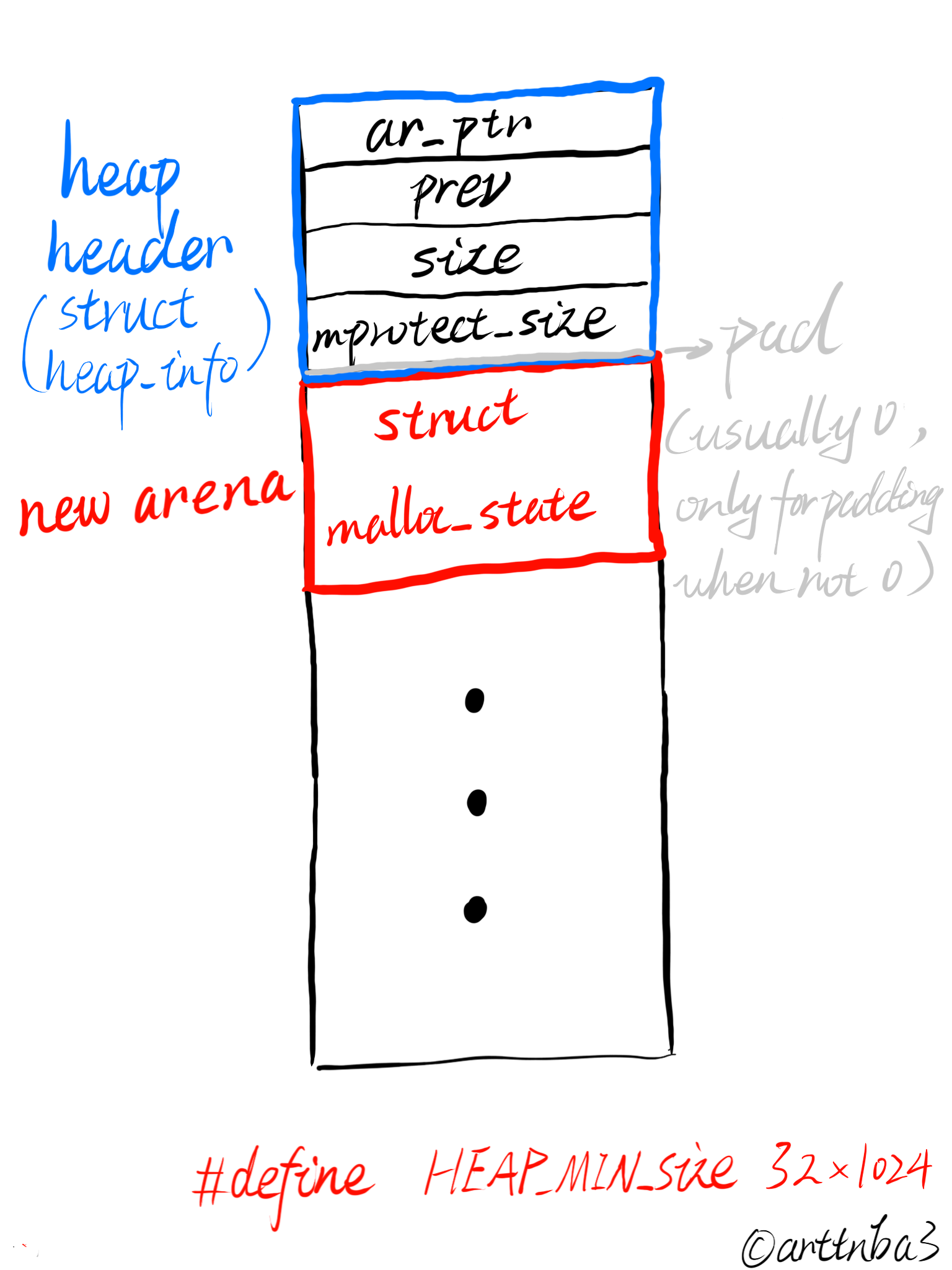
随后会调用malloc_init_state()函数初始化该arena,并设置其关联线程数为1,设置分配到的内存大小为heap header中的size,并使arena_mem加上该size
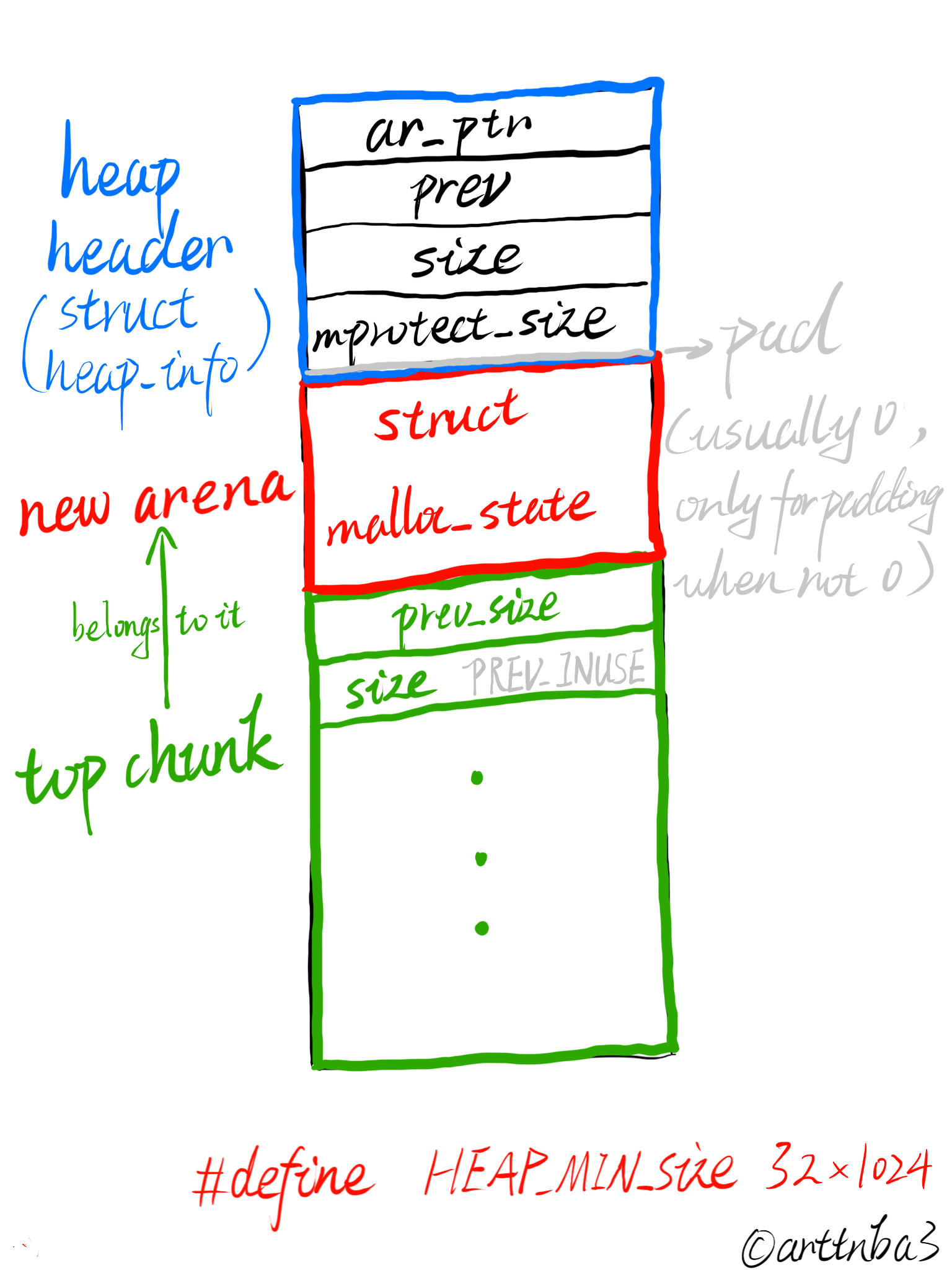
最后,剩余的内存会被视作该arena的top chunk,并设置PREV_INUSE标志位
此时这一块内存的布局如下:
需要注意的是若是内存地址未对MALLOC_ALIGNMENT对齐则会适当调整top chunk的位置
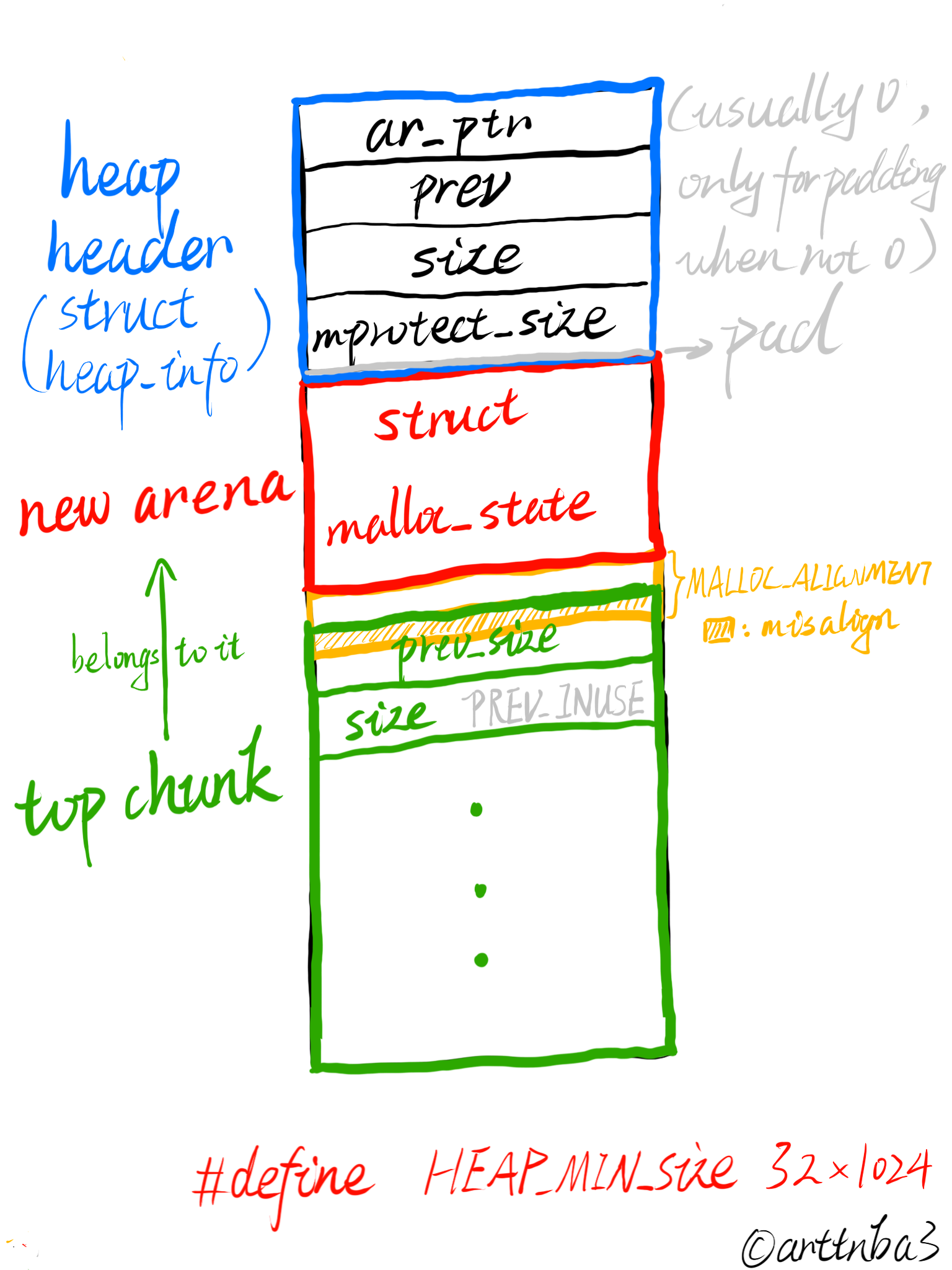
接下来会将该线程的arena设为该arena,并将该arena插入到arena链表中的main_arena之后
最后解锁线程原arena,锁上新的arena,并将新的arena返回
LIBC_PROBE:「LIBC探针」
LIBC_PROBE为系统探针的上层封装,该宏定义于include/stap-probe.h中,如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34#ifdef USE_STAP_PROBE
# include <sys/sdt.h>
/* Our code uses one macro LIBC_PROBE (name, n, arg1, ..., argn).
Without USE_STAP_PROBE, that does nothing but evaluates all
its arguments (to prevent bit rot, unlike e.g. assert).
Systemtap's header defines the macros STAP_PROBE (provider, name) and
STAP_PROBEn (provider, name, arg1, ..., argn). For "provider" we paste
in MODULE_NAME (libc, libpthread, etc.) automagically.
The format of the arg parameters is discussed here:
https://sourceware.org/systemtap/wiki/UserSpaceProbeImplementation
The precise details of how register names are specified is
architecture specific and can be found in the gdb and SystemTap
source code. */
# define LIBC_PROBE(name, n, ...) \
LIBC_PROBE_1 (MODULE_NAME, name, n, ## __VA_ARGS__)
# define LIBC_PROBE_1(lib, name, n, ...) \
STAP_PROBE##n (lib, name, ## __VA_ARGS__)
# define STAP_PROBE0 STAP_PROBE
# define LIBC_PROBE_ASM(name, template) \
STAP_PROBE_ASM (MODULE_NAME, name, template)
# define LIBC_PROBE_ASM_OPERANDS STAP_PROBE_ASM_OPERANDS
...//不使用PROBE的宏就不贴出来了,其逻辑仅为定义该宏为空依旧是套娃宏,STAP_PROBE##n宏定义在sys/sdt.h下,需要注意的是这个文件似乎不属于glibc
谷歌了一下,在终端使用如下指令安装systemtap-sdt-dev
sudo apt install systemtap-sdt-dev然后就能获得sdt.h了
在sdt.h中定义了13个STAP_PROBE宏,如下:
令人看着头大的写法
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29#define STAP_PROBE(provider, name) \
_SDT_PROBE(provider, name, 0, ())
#define STAP_PROBE1(provider, name, arg1) \
_SDT_PROBE(provider, name, 1, (arg1))
#define STAP_PROBE2(provider, name, arg1, arg2) \
_SDT_PROBE(provider, name, 2, (arg1, arg2))
#define STAP_PROBE3(provider, name, arg1, arg2, arg3) \
_SDT_PROBE(provider, name, 3, (arg1, arg2, arg3))
#define STAP_PROBE4(provider, name, arg1, arg2, arg3, arg4) \
_SDT_PROBE(provider, name, 4, (arg1, arg2, arg3, arg4))
#define STAP_PROBE5(provider, name, arg1, arg2, arg3, arg4, arg5) \
_SDT_PROBE(provider, name, 5, (arg1, arg2, arg3, arg4, arg5))
#define STAP_PROBE6(provider, name, arg1, arg2, arg3, arg4, arg5, arg6) \
_SDT_PROBE(provider, name, 6, (arg1, arg2, arg3, arg4, arg5, arg6))
#define STAP_PROBE7(provider, name, arg1, arg2, arg3, arg4, arg5, arg6, arg7) \
_SDT_PROBE(provider, name, 7, (arg1, arg2, arg3, arg4, arg5, arg6, arg7))
#define STAP_PROBE8(provider,name,arg1,arg2,arg3,arg4,arg5,arg6,arg7,arg8) \
_SDT_PROBE(provider, name, 8, (arg1,arg2,arg3,arg4,arg5,arg6,arg7,arg8))
#define STAP_PROBE9(provider,name,arg1,arg2,arg3,arg4,arg5,arg6,arg7,arg8,arg9)\
_SDT_PROBE(provider, name, 9, (arg1,arg2,arg3,arg4,arg5,arg6,arg7,arg8,arg9))
#define STAP_PROBE10(provider,name,arg1,arg2,arg3,arg4,arg5,arg6,arg7,arg8,arg9,arg10) \
_SDT_PROBE(provider, name, 10, \
(arg1,arg2,arg3,arg4,arg5,arg6,arg7,arg8,arg9,arg10))
#define STAP_PROBE11(provider,name,arg1,arg2,arg3,arg4,arg5,arg6,arg7,arg8,arg9,arg10,arg11) \
_SDT_PROBE(provider, name, 11, \
(arg1,arg2,arg3,arg4,arg5,arg6,arg7,arg8,arg9,arg10,arg11))
#define STAP_PROBE12(provider,name,arg1,arg2,arg3,arg4,arg5,arg6,arg7,arg8,arg9,arg10,arg11,arg12) \
_SDT_PROBE(provider, name, 12, \
(arg1,arg2,arg3,arg4,arg5,arg6,arg7,arg8,arg9,arg10,arg11,arg12))依然是套娃定义,跟进
2
3
4
5
6
7
8
9
10
11#ifdef __ASSEMBLER__
# define _SDT_PROBE(provider, name, n, arglist) \
_SDT_ASM_BODY(provider, name, _SDT_ASM_STRING_1, (_SDT_DEPAREN_##n arglist)) \
_SDT_ASM_BASE
# define _SDT_ASM_1(x) x;
# define _SDT_ASM_2(a, b) a,b;
# define _SDT_ASM_3(a, b, c) a,b,c;
# define _SDT_ASM_5(a, b, c, d, e) a,b,c,d,e;
...
#else
...//前面在stap-probe.h中若是没有def __ASSEMBLER__ 的话STAP_PROBE就是空了,所以后面的就不贴了依旧套娃,再度跟进
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26#define _SDT_ASM_BODY(provider, name, pack_args, args) \
_SDT_ASM_1(990: _SDT_NOP) \
_SDT_ASM_3( .pushsection .note.stapsdt,_SDT_ASM_AUTOGROUP,"note") \
_SDT_ASM_1( .balign 4) \
_SDT_ASM_3( .4byte 992f-991f, 994f-993f, _SDT_NOTE_TYPE) \
_SDT_ASM_1(991: .asciz _SDT_NOTE_NAME) \
_SDT_ASM_1(992: .balign 4) \
_SDT_ASM_1(993: _SDT_ASM_ADDR 990b) \
_SDT_ASM_1( _SDT_ASM_ADDR _.stapsdt.base) \
_SDT_SEMAPHORE(provider,name) \
_SDT_ASM_STRING(provider) \
_SDT_ASM_STRING(name) \
pack_args args \
_SDT_ASM_1(994: .balign 4) \
_SDT_ASM_1( .popsection)
#define _SDT_ASM_BASE \
_SDT_ASM_1(.ifndef _.stapsdt.base) \
_SDT_ASM_5( .pushsection .stapsdt.base,"aG","progbits", \
.stapsdt.base,comdat) \
_SDT_ASM_1( .weak _.stapsdt.base) \
_SDT_ASM_1( .hidden _.stapsdt.base) \
_SDT_ASM_1( _.stapsdt.base: .space 1) \
_SDT_ASM_2( .size _.stapsdt.base, 1) \
_SDT_ASM_1( .popsection) \
_SDT_ASM_1(.endif)
这你🦄的又套回去了啊这↑里↓便是系统探针的实现原理了,由于不是本篇重点故具体代码就先不分析了(
其实是不会
System Tap:「内核探测工具」
In computing, SystemTap (stap) is a scripting language and tool for dynamically instrumenting running production Linux kernel-based operating systems. System administrators can use SystemTap to extract, filter and summarize data in order to enable diagnosis of complex performance or functional problems.
SystemTap consists of free and open-source software and includes contributions from Red Hat, IBM, Intel, Hitachi, Oracle, the University of Wisconsin-Madison and other community members
大意是说SystemTap是一个用以对基于Linux内核的操作系统进行动态插桩的脚本语言工具,系统管理员可以用它来提取、过滤、汇总数据以进行复杂性能或功能问题的诊断
In order to aid in debugging and monitoring internal behavior, the GNU C Library exposes nearly-zero-overhead SystemTap probes marked with the libc provider.
为了帮助调试和监视内部行为,GNU C库公开了用libc提供程序标记的开销几乎为零的系统探针。
在get_free_list()函数中用到的探针为memory_arena_reuse_free_list,说明如下:
Probe: memory_arena_reuse_free_list (void *$arg1)
This probe is triggered when
mallochas chosen an arena that is in the free list for use by a thread, within theget_free_listfunction. The argument $arg1 holds a pointer to the selected arena.总之,调试linux内核的时候便可以在这些地方使用相应的系统探针
③get_free_list():尝试从free_list中获取一个空闲arena
该函数同样定义于arena.c中,用以从free_list中获取一个空闲的arena,如下:
1 | |
get_free_list()函数首先会检查free_list是否为空,若为空则直接返回NULL,不为空的情况下则会进行如下操作:
- 首先尝试锁上free_list_lock后再次检查free_list是否为空,若还是不为空才会取出头结点,并调用detach_arena()函数将当前线程原先使用的arena的关联线程数减一,这里的二次检查是为了防止多线程间的冲突(举个例子,可能有个线程在其之前先取出了free_list中的空闲arena,而当前线程必须要等待其解锁互斥锁free_list_lock后才能继续接下来的操作,若是仍使用前面所获取的arena那就乱套了);
- 调用mutex_unlock()函数解锁free_list互斥锁,随后再次检查此前获得的arena是否为NULL
- 若获得的arena不为NULL则锁上其互斥锁,将当前线程的thread_arena设为该arena
- 将最终的result返回给上层函数
④arena_get():获得一个arena
代码如下:
1 | |
arena_get()宏将会获取一个空间充足的arena并锁上对应的互斥锁:
- 将thread_arena给到ptr,并调用arena_lock()宏进行检查无误后尝试锁上互斥锁
- 若检查发现thread_arena为NULL(该线程第一次调用malloc)或该arena被破坏,则会尝试遍历arena链表寻找可用的arena
- 若无法找寻到可用的arena则会创建一个新的arena
接下来我们来看其内部实现的核心宏arena_lock()与核心函数arena_get2()
do{…}while(0):约定俗成书写形式
或许不少人在第一眼看到这个写法时都会觉得这么写是在脱裤子放屁(x)(包括笔者),但其实这种写法有其存在的意义所在
设想假如我们定义了这样一个宏:
#define DO_SOMETHING_USELESS() foo1();foo2();而假设在这样一段代码中我们使用了这个宏:
2
3
4if (somthing)
DO_SOMETHING_USELESS();
else
printf("fxck you!\n");那么会被展开成如下形式:
2
3
4if (somthing)
foo1();foo2();;
else
printf("fxck you!\n");毫无疑问下方的else便无法匹配到上方的if
可能有人想问了,若是加个括号呢?
#define DO_SOMETHING_USELESS() { foo1();foo2(); }则展开后是如下形式:
2
3
4if (somthing)
{ foo1();foo2(); };
else
printf("fxck you!\n");由于多了一个分号,下方的else还是无法匹配到上方的if
因此考虑使用do{…}while(0)的写法:
#define DO_SOMETHING_USELESS() do{ foo1();foo2(); }while(0)则展开后是如下形式:
2
3
4if (somthing)
do{ foo1();foo2(); }while(0);
else
printf("fxck you!\n");下方的else便能成功匹配到上方的if
可能有人要杠了:wsm不直接加括号、然后在调用该宏时不写分号?这是因为对于普通的C语言语句而言其末尾语法要求是要加分号的,因此古早时期宏的写法也便约定俗成要在语句末尾写上分号,因而便出现了do{}while(0)的写法,以便统一宏与一般语句的书写格式
⑤arena_lock():将arena上锁
代码如下:
1 | |
首先检查ptr是否为空,并调用arena_is_corrupt宏检查arena是否被破坏
- 若是检查通过,则调用mutex_lock()函数将arena中的互斥锁上锁(多线程相关函数便不在这里赘叙了)
- 若是检查不通过,则调用arena_get2()函数获得一个新的arena
⑥arena_get2():遍历free_list,若无合适则尝试获取一个新的arena或使用已有arena
arena_get2()函数同样定义于arena.c中,如下
1 | |
首先会调用get_free_list()函数尝试从free_list中获取一个arena,若成功则直接返回
若无法从free_list中获取获取到arena(free_lIst为空),首先会检查narenas_limit变量是否为0,该变量用以记录一个进程中的arena数量限制,由于该变量为静态变量,故初始值默认应当为0
初始值为0的情况下便会先检查ptmalloc参数中的arena_max是否为0,由于mp_也是一个静态变量,故arena_max初始值也应当为0
若arena_max不为0(没有设定arena_max),则直接将其值赋予narenas_limit
否则,将narenas与ptmalloc参数中的arena_test进行比较,若是arena数量已经超出了test值,则重新初始化arena数量上限:调用__get_nprocs()函数获取CPU的核心数以设定arena的数量上限,32位下为核心数乘2,64位下为核心数乘8,若是无法获取到核心数,则直接按照核心数为2进行计算,当线程数大于核心数的2倍时,便必然有线程处于等待状态,因此在这里便根据核心数计算arena上限数(至于64位下为什么是乘8,笔者也暂且蒙在古里指在蒙古待会)
随后检查arena数量是否达到上限(narenas == narena_limit),若否,则接下来会调用宏catomic_compare_and_exchange_bool_acq将narenas的值加1,随后调用_int_new_arena()函数创建一个新的arena,若成功则返回,否则重新将narenas的值减1
若arena数量已经达到上限,则会调用reused_arena()函数尝试从现有arena中寻找可用的arena上锁后返回,需要注意的是该函数遍历arena时会过滤掉传入的avoid_arena
__glibc_likely(expr) && __glibc_unlikely(expr):分支预测优化(封装宏)
对__builtin_expect宏的封装,定义于misc/sys/cdefs.h中,如下:
2
3
4
5
6
7#if __GNUC__ >= 3
# define __glibc_unlikely(cond) __builtin_expect ((cond), 0)
# define __glibc_likely(cond) __builtin_expect ((cond), 1)
#else
# define __glibc_unlikely(cond) (cond)
# define __glibc_likely(cond) (cond)
#endif只有宏__GNUC__的值大于3时才会启用该宏,其核心是宏__bulltin_expect(expr, var)
internal_function
定义于malloc.c中,如下:
2
3
4
5
6/* On some platforms we can compile internal, not exported functions better.
Let the environment provide a macro and define it to be empty if it
is not available. */
#ifndef internal_function
# define internal_function
#endif大意是说这是为了一些特殊用途而预留的一个宏,该宏默认定义为空
catomic_compare_and_exchange_bool_acq
该宏定义于include/atomic.h中,如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15#ifndef catomic_compare_and_exchange_bool_acq
# ifdef __arch_c_compare_and_exchange_bool_32_acq
# define catomic_compare_and_exchange_bool_acq(mem, newval, oldval) \
__atomic_bool_bysize (__arch_c_compare_and_exchange_bool,acq, \
mem, newval, oldval)
# else
# define catomic_compare_and_exchange_bool_acq(mem, newval, oldval) \
({ /* Cannot use __oldval here, because macros later in this file might \
call this macro with __oldval argument. */ \
__typeof (oldval) __atg4_old = (oldval); \
catomic_compare_and_exchange_val_acq (mem, newval, __atg4_old) \
!= __atg4_old; \
})
# endif
#endif在glibc源码中笔者并没有找到关于
__arch_c_compare_and_exchange_bool_32_acq宏的定义,故默认应当是使用else这一块的内容首先会将oldval的值拷贝一份,随后再调用宏
catomic_compare_and_exchange_val_acq(套娃来套娃去该宏同样位于include/atomic.h中,如下
2
3
4
5
6
7
8
9
10#ifndef catomic_compare_and_exchange_val_acq
# ifdef __arch_c_compare_and_exchange_val_32_acq
# define catomic_compare_and_exchange_val_acq(mem, newval, oldval) \
__atomic_val_bysize (__arch_c_compare_and_exchange_val,acq, \
mem, newval, oldval)
# else
# define catomic_compare_and_exchange_val_acq(mem, newval, oldval) \
atomic_compare_and_exchange_val_acq (mem, newval, oldval)
# endif
#endif
又套了一层娃继续跟进
2
3
4
5
6
7
8/* Atomically store NEWVAL in *MEM if *MEM is equal to OLDVAL.
Return the old *MEM value. */
#if !defined atomic_compare_and_exchange_val_acq \
&& defined __arch_compare_and_exchange_val_32_acq
# define atomic_compare_and_exchange_val_acq(mem, newval, oldval) \
__atomic_val_bysize (__arch_compare_and_exchange_val,acq, \
mem, newval, oldval)
#endif宏
__arch_compare_and_exchange_val_32_acq已经在sysdeps/(多个文件夹中皆有)/atomic-machine.h中定义了,我们直接跟进__atomic_val_bysize的定义即可
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/* Wrapper macros to call pre_NN_post (mem, ...) where NN is the
bit width of *MEM. The calling macro puts parens around MEM
and following args. */
#define __atomic_val_bysize(pre, post, mem, ...) \
({ \
__typeof (*mem) __atg1_result; \
if (sizeof (*mem) == 1) \
__atg1_result = pre##_8_##post (mem, __VA_ARGS__); \
else if (sizeof (*mem) == 2) \
__atg1_result = pre##_16_##post (mem, __VA_ARGS__); \
else if (sizeof (*mem) == 4) \
__atg1_result = pre##_32_##post (mem, __VA_ARGS__); \
else if (sizeof (*mem) == 8) \
__atg1_result = pre##_64_##post (mem, __VA_ARGS__); \
else \
abort (); \
__atg1_result; \
})在这里则又会根据
*mem的大小调用相应的宏,定义于sysdeps/ia64/atomic-machine.h中,如下:
2
3
4
5
6
7
8
9
10
11
12#define __arch_compare_and_exchange_val_8_acq(mem, newval, oldval) \
(abort (), (__typeof (*mem)) 0)
#define __arch_compare_and_exchange_val_16_acq(mem, newval, oldval) \
(abort (), (__typeof (*mem)) 0)
#define __arch_compare_and_exchange_val_32_acq(mem, newval, oldval) \
__sync_val_compare_and_swap ((mem), (int) (long) (oldval), \
(int) (long) (newval))
#define __arch_compare_and_exchange_val_64_acq(mem, newval, oldval) \
__sync_val_compare_and_swap ((mem), (long) (oldval), (long) (newval))对于1字节与2字节长的指针,进程会直接调用abort()终止(笔者也不明白wsm这么设计),而对于4字节长与8字节长的指针,则会调用GCC内置的原子操作
__sync_val_compare_and_swap查看GCC手册中说明如下:
bool __sync_bool_compare_and_swap (`type` *ptr, `type` oldval `type` newval, ...)type
__sync_val_compare_and_swap (type*ptr,typeoldvaltypenewval, ...)ptrisoldval ptr
The “bool” version returns true if the comparison is successful and newval was written. The “val” version returns the contents of
*ptr before the operation.那么一切就真相大白了
套娃catomic_compare_and_exchange_bool_acq宏需要传入三个参数:mem、newval、oldval,其中mem应当要为一个指针类型,随后比较oldval与*mem的值是否相等,若是则将*mem赋值为newval并返回0,若否则返回非零值
catomic_decrement
定义于include/atomic.h中,如下:
2
3#ifndef catomic_decrement
# define catomic_decrement(mem) catomic_add ((mem), -1)
#endif套娃,跟进
2
3
4#ifndef catomic_add
# define catomic_add(mem, value) \
(void) catomic_exchange_and_add ((mem), (value))
#endif还是套娃,再跟进
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16#ifndef catomic_exchange_and_add
# define catomic_exchange_and_add(mem, value) \
({ __typeof (*(mem)) __atg7_oldv; \
__typeof (mem) __atg7_memp = (mem); \
__typeof (*(mem)) __atg7_value = (value); \
\
do \
__atg7_oldv = *__atg7_memp; \
while (__builtin_expect \
(catomic_compare_and_exchange_bool_acq (__atg7_memp, \
__atg7_oldv \
+ __atg7_value, \
__atg7_oldv), 0)); \
\
__atg7_oldv; })
#endif最终我们可以知道该宏的用处是将一个变量的值减一,同样由于考虑到多线程操作的情况,在这里使用的是原子操作
⑦reused_arena():寻找可用arena上锁后返回
同样定义于arena.h中,如下:
1 | |
操作步骤如下:
首先检查next_to_use,若为NULL则设为main_arena
接下来从next_to_use开始遍历arena链表,若找到一个未被破坏且能成功上锁的arena(即该未被破坏的arena未被上锁)则跳转到下一步,否则会二次遍历arena链表,寻找未被破坏的且非avoid_arena的arena并上锁,若仍旧失败则返回NULL
接下来将原arena关联线程数减一,新arena关联线程数加一,并将next_to_use设为该arena的next指针指向的arena,为了防止多线程冲突,这一步操作会先锁上free_list,操作结束后再行解锁
最后将该线程arena设为获取到的arena并返回
⑧detach_arena():将arena关联线程数减一
同样定义于arena.c中,如下:
1 | |
该函数首先会检查其参数replace_arena是否不为NULL,只有不为NULL时才会进一步操作
随后使用assert检查replace_arena的attached_threads成员是否大于0
只有在一切正常的情况下,才会将该arena的关联线程数减一
⑨arena_for_chunk():获取一个堆块对应的arena
该宏定义于arena.c中,如下:
1 | |
首先会检查该chunk的NON_MAIN_ARENA标志位,若为false则直接返回main_arena,否则会先获取该chunk所属的heap后再通过heap header(heap_info)获取到其所属的arena