【PAPER.0x07】论文笔记:kAFL: Hardware-Assisted Feedback Fuzzing for OS Kernels
本文最后更新于:2024年7月31日 凌晨
Rabbit’s adventures in kernel land
0x00. 一切开始之前
在上一篇论文当中我们介绍了这个作者针对虚拟机设计的 fuzzer,这次我们来看他的另一篇使用 Intel PT 技术辅助的一个针对 OS kernel 设计的 fuzzer:kAFL
Abstract
基于反馈的 fuzzing 非常强大,但对内核进行 fuzz 难以应用反馈机制(即代码覆盖率指导),且内核 crash 导致的 os 重启会影响 fuzz 的性能
本文使用虚拟化技术与 Intel PT(Processor Trace)技术带来独立于 OS 的硬件辅助的 fuzzing 解决方案,这使得我们只需要额外开发一小部分与内核交互的用户空间组件;作者还开发了 kernel-AFL 框架,并在 Linux、Windows、macOS 上找到数个漏洞
0x01. Introduction
经典的不用看的章节
过去人们主要关注更容易被利用的用户态应用的安全漏洞,而随着用户态的各种加固,内核开始更加吸引攻击者
模糊测试长期以来被用来寻找漏洞,最新的反馈驱动型 fuzzer 通过反馈机制学习输入的有趣性并以此生成更多可能触发新路径的输入,但最火的 AFL 仅限于用户空间,fuzz 内核存在一系列额外的挑战:crash 与 timeout 需要虚拟化技术捕获并优雅地继续、内核代码存在更多不确定性、缺少 fuzz 命令行程序那样通过 stdin 直接输入的简易方法、部分内核组件不开源而无法在性能不损耗的情况下插桩
过去的内核 fuzzing 方法依赖于特定的驱动或是重编译,且由于使用模拟的缘故速度非常慢,或是非反馈驱动
本文介绍一种无需 ring0 代码甚至特定于 OS 的代码便能够对任意(甚至闭源)x86-64 内核进行 feedback fuzzing 的技术,实现为 kernel-AFL,Intel PT 技术提供了控制流信息,且生成反馈信息的开销极小(5%)
总而言之,本篇论文贡献如下:
- OS independence:作者展示了使用 VMM 生成覆盖率来对大部分闭源内核组件进行反馈驱动 fuzzing 是可行的
- Hardware-assisted feedback:作者使用了 Intel Process Trace 技术,其开销极小
- Extensible and modular design:作者使用了模块化设计,方便支持其他的 x86 内核/用户组件
- kernel-AFL:作者使用自己的理念开发了原型系统 kernel-AFL
0x02. Technical Background
本节介绍后续章节涉及的硬件特性
2.1 x86-64 Virtual Memory Layouts
内核空间通常位于虚拟高地址部分而用户空间位于低地址部分,OS 处理任务通常不会切换 CR3,而是在同一地址空间处理
2.2 Intel VT-x
我们将 CPU 分为三类:物理 CPU、逻辑 CPU(超线程可能带来多于物理 CPU 数量的逻辑 CPU,但仅有一个同时活动)、虚拟 CPU(基于逻辑 CPU 建立)
虚拟化中角色分为两种:虚拟机监视器(Virtual Machine Monitor)和虚拟机(Virtual Machine),VMM 管控 VM,VM 在 VMM 提供的透明上下文中执行
Intel VT-x 技术提供了硬件辅助的 CPU 虚拟化特性,将 CPU 额外分为 VMXOFF(不开启虚拟化)与 VMXON(开启虚拟化)的运行模式,并区分 VMX non-root(用于 VM)与 VMX root(用于 VMM)两种执行模式
VM 可能通过各种原因触发 VM-Exit 事件将控制权转交给 VMM 进行处理,VMM 通过包含 vCPU 信息的 VMCS 结构创建、启动、控制 VM
2.3 Intel PT
Intel 自第五代处理器引入 Intel PT 技术,提供执行和分支跟踪信息,不同于 Intel Last Branch Record 这样的分支记录技术,输出缓冲区的大小仅受主存大小而非特定寄存器的限制,输出格式基于数据包(packet-oriented)并分为通用执行信息与控制流信息包;Intel 在运行时提供各类控制流相关的数据包类型,因此我们需要用被跟踪的软件来翻译包含控制流分支地址的包
Intel 指定了五种类型的控制流影响指令,称为 Change of Flow Instruction (CoFI),不同类型的 CoFI 执行结果产生不同的信息包流,与本文相关的三种为:
- Taken-Not-Taken(TNT):条件跳转是否执行
- Target IP(TIP):间接跳转或转移指令(
indirect branch, near ret, far transfer)的目标 - Flow Update Packets(FUP):如中断或陷阱等异步事件, FUP 之后通常跟随一个 TIP 以指示接下来的指令
为了限制生成的数据量,Intel PT 提供了多种运行时过滤选项,如指令指针地址范围或特权级别(CPL),kAFL 以此将追踪限制为内核模式,同时利用 CR3 过滤来限制为特定的软件
Intel PT 支持为输出数据配置多目标域,kAFL 关注于允许指定多个输出区域的物理地址表(Table of Physical Addresses,ToPA)机制:每个 ToPA 表包含多个 ToPA 条目,其中包含用来存储追踪数据的内存块的物理地址、大小、类型(用于指示 CPU 访问 ToPA 表项时的行为)等信息
0x03. System Overview
这节介绍系统总体架构,分为三个组件:fuzzing logic、VM infrastructure( QEMU-PT 与 KVM-PT)、user mode agent,整体架构如图 1 所示:
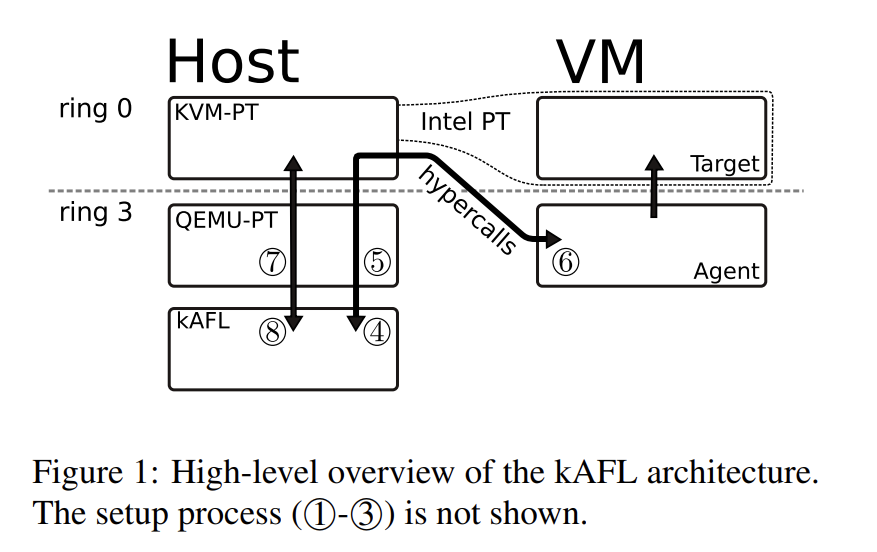
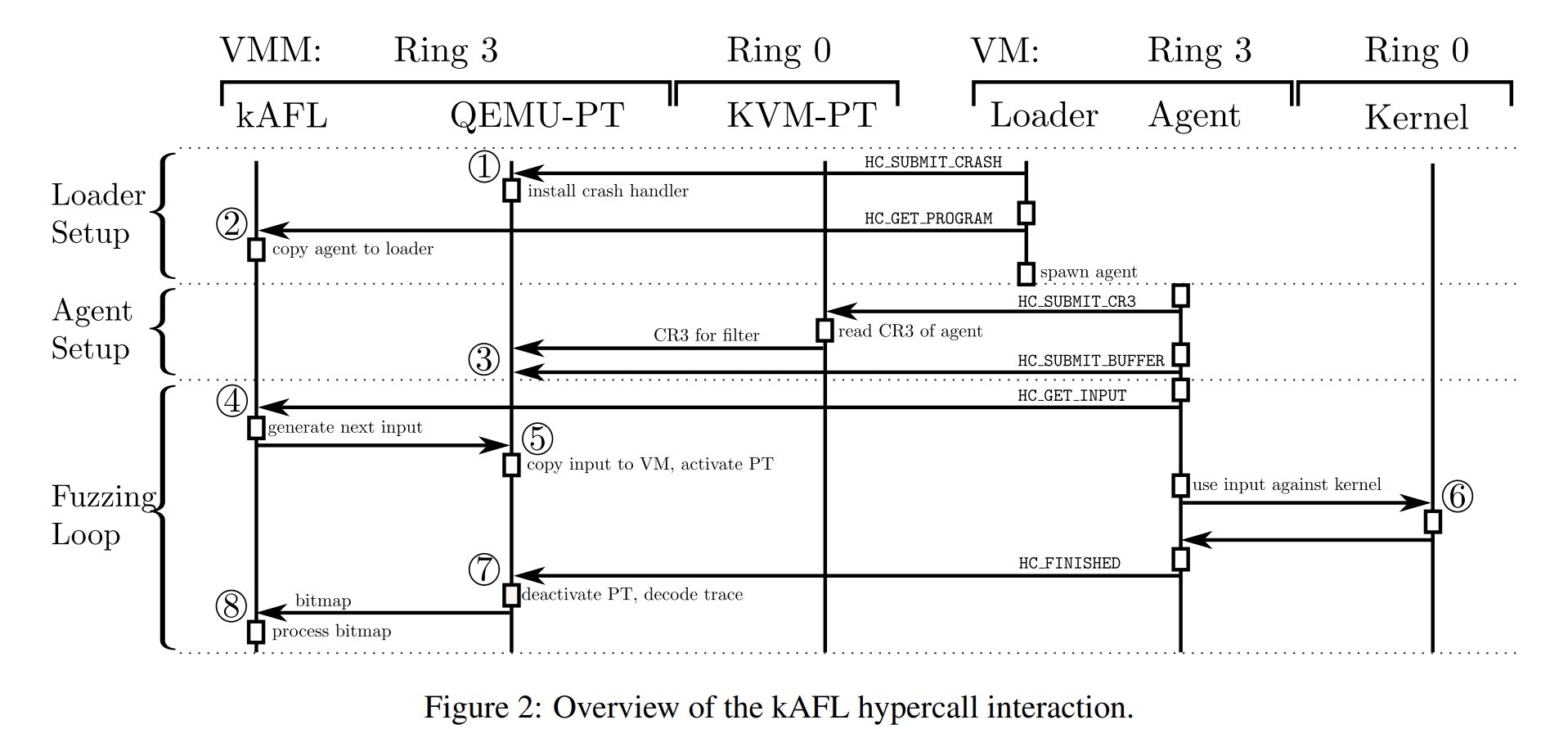
模糊测试过程如图 2 所示:
在 VM 启动时 user mode agent 的第一部分(loader)使用 hypercall
HC_SUBMIT_PANIC来向 QEMU-PT 提交kernel panic handler(Windows 下为BugCheck())的地址,QEMU-PT 将其更改为一个 hypercall 调用例程以让我们快速得知 VM 中的 crashesloader 使用 hypercall
HC_GET_PROGRAM来获取实际的 user mode agent 并启动fuzzer 开始初始化,agent 触发一个会由 KVM-PT 处理的 hypercall
HC_SUBMIC_CR3,hypervisor 从当前运行的程序中提取 CR3 的值并交给 QEMU-PT 进行过滤最后,agent 使用 hypercall
HC_SUBMIT_BUFFER来提交其想要获取输入的地址,接下来开始主 fuzzing 循环在主循环中,agent 通过 hypercall
HC_GET_INPUT来获取新的输入,fuzzing logic 生成一个新的输入并交给 QEMU-PT 由其拷贝到 guest 内存中在 VM-Entry 恢复虚拟机执行时开启 PT 追踪机制,此时 agent 使用输入与内核交互,在 Fuzzing 过程中 QEMU-PT 解码追踪数据并在需要时更新位图
交互完成后 agent 通过 hypercall
HC_FINISHED告知 hypervisor 停止追踪,位图被传递给 fuzzing logic 后续使用最后 agent 可以继续运行任何未被追踪的清理程序,然后发出另一个
HC_GET_INPUT以启动下一次循环迭代
3.1 Fuzzing Logic
fuzzing logic 是 kAFL 的控制组件,负责管理种子、生成输入等,大量采用了 AFL 所用的算法(如使用位图记录块转移),且使用并行 VM 协调提升性能,并负责与 QEMU-PT 通信以及显示统计数据
3.2 User Mode Agent
在目标 OS 中运行的 User Mode Agent 通过 hypercall 与 fuzzing logic 同步并获取新输入以与内核交互,在实践中作者额外使用loader component 通过 hypercall 接收 User Mode Agent 二进制并执行,同时负责检查 agent 的状态
3.3 Virtualization Infrastructure
fuzzing logic 使用 QEMU-PT 与 KVM-PT 交互以创建 VMs,KVM-PT 允许我们限定 Intel PT 范围为 vCPU 执行期间,QEMU-PT 负责与 KVM-PT 交互以配置 Intel PT 并访问与解码 output buffer 的追踪数据为被执行的条件跳转指令的地址的流,且基于已知非确定性基本款地址进行过滤(以预防假阳性)后以 AFL 兼容的位图格式提供给 fuzzing logic
作者使用客制化的 Intel PT 解码器,与 Intel 的现有方案比带来了性能提升
3.4 Stateful and Non-Deterministic Code
内核层的状态与异步性导致的不确定性需要被处理,状态不会被重置因为快照加载成本过高,中断可能带来不确定性基本块转移,作者使用两种技术解决这些问题:
第一种是过滤出中断及中断处理造成的转移,这可以通过 Intel PT 的追踪数据(带有 FUP 的 TIP)指示,丢弃直到 iret 指令前的基本块,同时通过一个简易的调用栈追踪所有中断(因为可能存在中断嵌套)
第二种是拉黑所有非确定性出现的基本块,作者会在位图更新时连续多次重新运行输入,将没有在所有试验中出现的基本块拉入黑名单,在后续处理在过滤
注:笔者认为作者使用的第二种技术可能会存在非常大的假阳性,因为内核在不同状态下同一输入的结果可能也是不同的
3.5 Hypercall
hypercall 由 vmcall 指令调起以主动触发 VM-Exit,作者修改了 KVM-PT 以接收 ring3 的 hypercall,并通过 rcx 寄存器传参,例如 HC_SUBMIT_BUFFER 通过 rcx 存储一个 guest 指针,另一个例子是告知 fuzzing logic 目标 OS 发生了 crash,注入的代码如 List 1 所示

0x04. Implementation Details
代码开源于 https://github.com/RUB-SysSec/kAFL
4.1 KVM-PT
Intel PT 允许我们在不修改/重编译目标内核的情况下追踪分支转移,据作者所知过去不曾有公开可用的驱动能够使用 Intel PT 仅追踪单个 vCPU 的 guest 执行,如 Simple-PT 在设计上不支持长期追踪,perf-subsystem 可以长期追踪但仅能追踪逻辑 CPU 而非 vCPU
为了解决这些缺点,作者开发了 KVM-PT,其允许我们在无限长的时间内追踪 vCPU ,并导出一个用户模式接口供 QEMU-PT 访问追踪数据
4.1.1 vCPU Specific Traces
开启 Intel PT 需要在 ring0 启用 MSR 寄存器的 IA32_RTIT_CTL_MSR.TraceEn 位,这需要在进入 VM 前完成,在 VM-Exit 后则需要反向操作,而手动修改 MSR 会产生不必要的追踪数据,作者使用 Intel VT-x 的 MSR 自动加载功能(如修改 VMCS.VM_ENTRY_CONTROL_MSR )来在 VM-Entry & VM-Exit 时加载预配置 MSR
笔者注:这点事都能写这么一大段❓
4.1.2 Continuous Tracing
如图 3 所示的物理地址表(Table of Physical Addresses,ToPA)项结构体数组用以指示 Intel PT 如何填充缓冲区,在主缓冲区填满后 CPU 可以停止追踪或是产生能造成 VM-Exit 的中断(当前的实现为非即时)以让 VMM 重置缓冲区后恢复 VM 执行,overflow buffer 被放置在 main buffer 后以避免实际传递中断前可能的追踪数据丢失(其若也溢出则导致追踪停止,此时会新增一个数据表指示数据丢失)
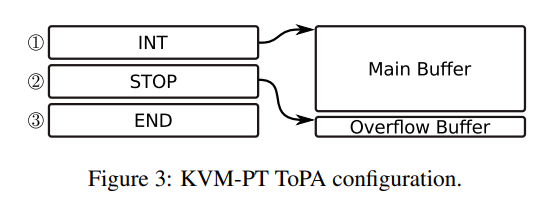
4.2 QEMU-PT
QEMU-PT 通过 KVM-PT 的用户空间接口(ioctl() 与 mmap() )配置 Intel PT 并定期检查 ToPA,并将 Intel PT 数据包解码为类似 AFL 的位图
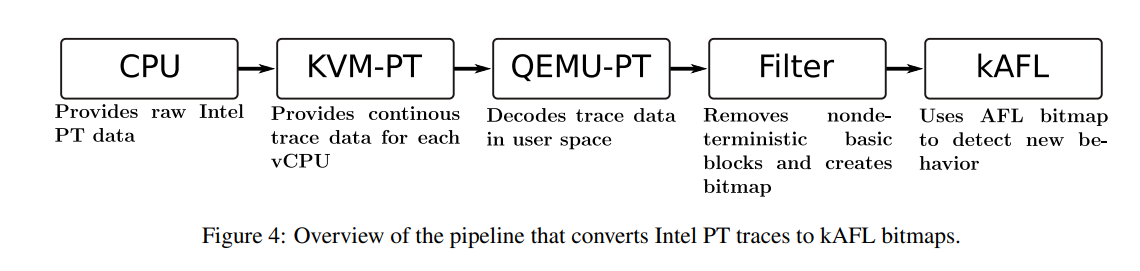
4.2.1 PT Decoder
解码器需要足够高效以应对产生速率为几百 MB 每秒的内核模糊测试追踪数据,且需要足够的精确
Intel 为客制 Intel PT 解码器提供了自己的通用解码引擎 libipt ,但 kAFL 仅依赖流信息,而 libipt 在提供执行数据与流信息的同时并不缓存反汇编指令,因此作者实现了一个类似即时(just-in-time)解码器的软件,并缓存所有反汇编指令以优化查找,同时忽视与测试用例无关的数据包
作者的解码器在 ToPA 区域被填充后便开始解码(而非等待填满),并翻译为 AFL 位图格式
4.3 AFL Fuzzing Logic
作者的 fuzzing logic 与 AFL 十分相似,每个基本块被给予一个随机 ID,从块 A 到 B 的转移被通过如下方程赋予一个偏移值到位图中:
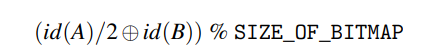
不同于编译期随机,kAFL 使用基本块的地址作为 ID,在观测到转移后便增加位图中计数,在 fuzzing 迭代结束后将位图的每个 entry 舍入以仅保留最高位,并与全局静态位图对比以检查是否发现新位,若是则添加到全局静态位图并将触发新位的输入添加到队列中,当发现了有趣的输入时则进行逐字节变异,该阶段完成后在随机位置进行变异(若前阶段发现新的输入则将推迟),触发新转移的输入将会给予更高的优先级
0x05. Evaluation
作者的实验机器为 Intel i7-6700 processor, 32 GB DDR4 RAM ,为避免 IO 性能影响,所有基准测试在一个 RAM disk 上完成
类似 AFL ,若一个造成 crash 的输入触发了此前未有的基本块转移,则作者认为其是唯一的(但不意味着底层错误唯一)
5.1 Fuzzing Windows
作者实现了一个小的特定于 Windows 10 的 user mode agent,通过虚拟磁盘对 NTFS 的 4 天 + 19 小时 fuzzing 后找到了 59 个独立的 crashes(都是除以 0 错误),经检查作者怀疑可能只有一个独立的错误
此外作者还实现了一个通用 syscall fuzzing agent,但在 Windows 下 13 个小时的 6.3 百万次执行中未发现 crash,由于 kAFL 得益于覆盖率反馈很快习得如何生成有效载荷以执行有效系统调用,导致了 fuzzing agent 中的意外的用户回调,从而使得 agent 需要高昂开销以重启,导致美妙仅能执行约 134 次
5.2 Fuzzing Linux
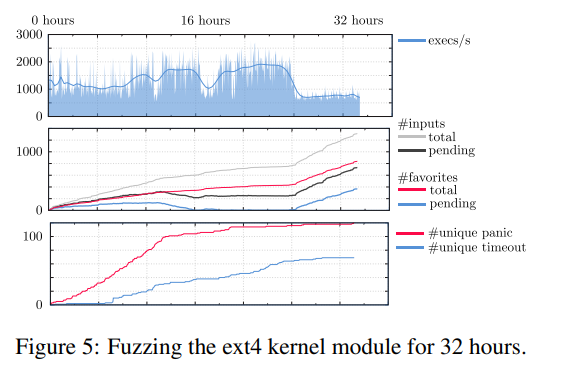
作者为 Linux 实现了一个类似的 agent 以测试 ext4 ,但效率比 Windows 快得多(每秒 1k~2k次执行),从而在 12 天的测试中发现了 160 个独立的 crash 并确认了多个 bug,图 5 展示了另一个模糊测试的前 32 小时
5.3 Fuzzing macOS
作者在 HFS 驱动中找到了 150 个 crash 并手动确认了至少三个为导致内核崩溃的独立漏洞,这可以造成 DoS 攻击,此外 kAFL 在 APFS 内核扩展中发现了 220 个独立的 crash,目前都被上报给了 Apple
5.4 Rediscovery of Known Bugs
作者在 keyctl() 接口上评估了 kAFL,成功找到此前已知的 CVE-2016-07583,并找到了一个未知错误(已被分配为 CVE-2016-86504),其在短短一小时内成功触发 17 个独立的 KASan 报告与 15 个独立的 panic,生成了超过 3400 万个输入,发现了 295 个有趣的输入,每秒执行约 9k 次,该实验为 8 进程并行
5.5 Detected Vulnerabilities
kAFL 在测试过程中发现超过 1k 个独立的 crash,作者手动分析了一部分并与对应的维护者确认了如下漏洞:

5.6 Fuzzing Performance
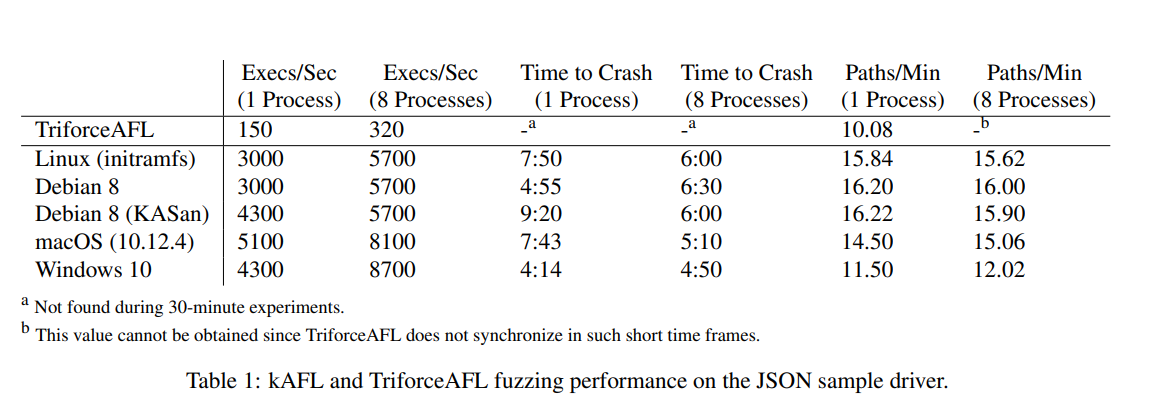
作者创建了一个基于 jsmn 的 JSON parser driver(如 List 2 所示,在 JSON 字符串以 "KAFL" 起始时触发 crash)并在三个系统上进行了测试,并与 TriforceAFL 和 syzkaller 进行对比

30 分钟的测试结果如表 1 所示,然而 TriforceAFL 未能触发崩溃路径,因而很难与 kAFL 比较覆盖率
覆盖率结果如图 6 所示,不过随着 fuzzing 时间增长,新路径更难被发现,因此这不是个好的指标
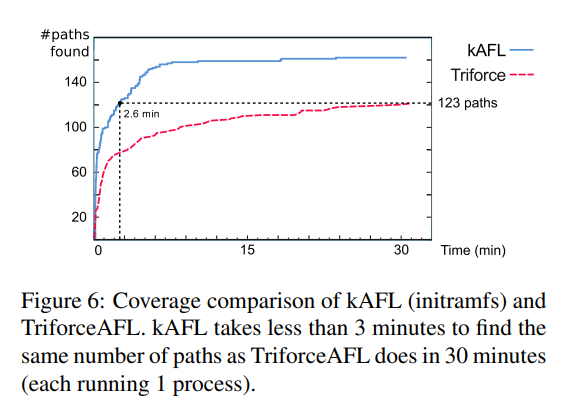
图 7 显示了 kAFL 与 TriforceAFL 在 raw execution 上的性能对比
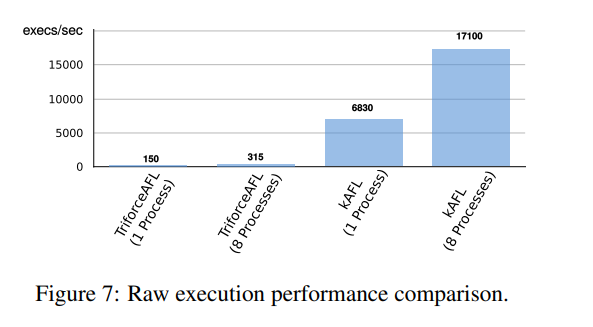
与 syzkaller 间作者并未做性能对比,因为其是一个高度特定的 syzkaller fuzzer,且其知识使其可以在无反馈下产生更高的代码覆盖率,因此除非作者实现了相同的系统调用逻辑,否则覆盖率对比会存在误导性
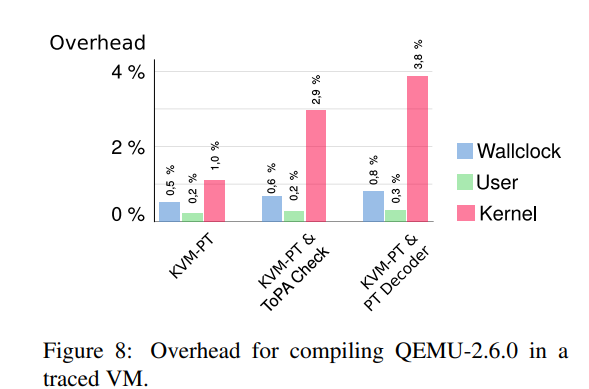
5.7 KVM-PT Overhead
作者在一个 i5-6500@3.2Ghz 桌面环境中对了不同的 KVM-PT 配置,将追踪限定在内核地址空间,图 8 说明了没有 KVM-PT 下的执行相对开销
多的不抄了,自己看原文:)
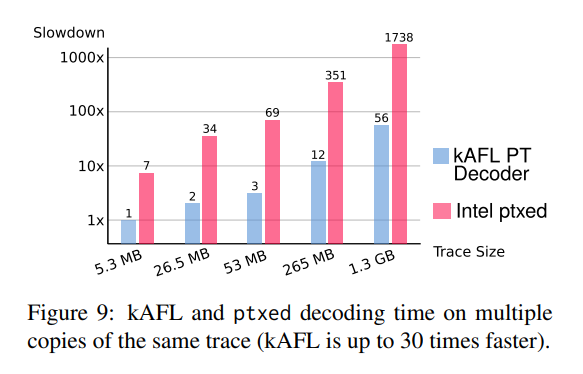
5.8 Decoder Engine
解码过程没有硬件加速,因此解码器对 fuzzing 整体性能有显著影响,作者将自己的解码器与 Intel ptxed 进行了对比,在一个 i5-6500@3.2Ghz 环境中进行了测试,结果如图 9 所示
0x06. Related Work
6.1 Black-Box Fuzzers
此类 fuzzer 与目标程序没有任何交互,为了提高效率通常会进行一些假设,例如 Radamsa 或 zzuf 会假设大量覆盖率良好的输入会反复发生变异与重组,而 Peach 与 Sulley 需要程序员指定如何生成看起来几乎像真正文件的半可用输入文件;上述这些都有一个重要缺陷:耗时过高
为了提高黑盒 fuzzer 的性能,研究人员提出了不少技术,如 Holler 提出了从旧的 crash 输入中习得输入语法的有趣部分 ,还有人提出根据程序追踪来推断输入语法等,Rebert 则优化了对有趣输入的选择
6.2 White-Box fuzzers
程序分析方法被引入以减少测试负担,类似 SAGE 、DART 、 KLEE 、 SmartFuzz 、Mayhem 这样的工具尝试使用符号执行与约束求解技术枚举复杂路径,TaintScope 、BuzzFuzz 、Vuzzer 利用污点追踪与类似的动态分析技术来发现新路径,他们通常都能找到隐藏在 checksum、magic constraint 等难以被随机输入满足的复杂代码路径,另一种办法是使用相同类型的信息来搜索危险行为而非新代码路径
缺点是这些技术通常难以实现并扩展到大型程序上,据作者所知目前暂时没有针对操作系统的这样的工具
6.3 Gray-Box Fuzzers
灰盒 fuzzer 在保留黑盒的高吞吐量与简易性获得白盒所使用的高级机制提供的额外覆盖,比较好的灰盒测试的例子是 AFL,其使用覆盖率信息指引以避免在不触发新状态的输入上耗费时间,其他的一些 fuzzer 也使用了类似机制
为了进一步提高灰盒测试的有效性,许多用在黑盒测试中的技术也被使用,例如 Böhme 展示了如何使用马尔可夫链来提高灰盒测试性能
6.4 Coverage-Guided Kernel Fuzzers
Vyukov 放出的项目 syzkaller 是第一个公开的能够用于覆盖率引导的内核 fuzzer ;Nossum 与 Casanovas 通过一个修改版 AFL 证明了绝大部分 Linux 文件系统驱动对于反馈驱动的模糊测试都是脆弱的
Hertz 和 Newsham 在 2016 年发布了名为 TriforceAFL 的 AFL 修改版,其基于一个修改版的 QEMU ,利用了对应的模拟后端通过在执行控制流更改指令后确定当前的指令指针来测量模糊测试进度,这理论上可以测试任何 QEMU 能模拟的操作系统,但事实上 TriforceAFL 仅限于能够从只读文件系统启动的操作系统(基本上只有 UNIX-like),无法测试 macOS 或 Windows 等闭源操作系统
0x07. Discussion
作者的工作仍有一些缺陷
OS-Specific Code. 作者使用了少量特定于操作系统的代码来执行三个任务:将模糊测试输入转为与操作系统的交互、获取操作系统对崩溃处理程序的地址、返回某些驱动程序的地址
这些功能都不是必须的,第一个问题可以用通用系统调用来避免,同时也不一定需要崩溃处理程序的地址来检测 VM crash
Supported CPUs. 本文的工作局限于支持 Intel VT-x 技术的 CPU,但对于哪些 CPU 确乎支持指令指针过滤、multi-entry ToPA 等含糊其辞,
Just-In-Time Code. intel PT 并不提供已执行指令指针的完整列表,这需要解码器完成控制流重建,但若程序在运行时被修改(例如 JIT)则无法准确恢复运行时控制流,因此解码器需要对程序应用的修改信息,如 Deng 等人使用 EPT violation 实现,更老的做法是使用影子页表
Multibyte Compares. 本文的工作无法知道程序中较大的 magic values,但使用比如混合执行(如 Driller )或是污点追踪(如 Vuzzer )技术可以提高性能,但都无法轻易被应用到闭源操作系统内核中
Ring 3 Fuzzing. 作者仅针对内核代码使用了该技术,但这个方法也适用于用于用户态,作者预计其将由于基于动态二进制插桩的方法(如 winAFL )
0x08. Conclusion
作者提出了使用 CPU 新特性的反馈驱动的内核模糊测试方法,性能明显优于其他方法,很好很强大🎆🎇🎇🎆