【PAPER.0x06】论文笔记:High-density Multi-tenant Bare-metal Cloud
本文最后更新于:2024年7月27日 早上
出走字节 IaaS 开发实习两年,归来读安全 PhD 依然在做 DPU
0x00. 一切开始之前
最近不知道为什么又开始看 DPU 了(反正就是啥都想弄一点),所以先从这篇非常经典的论文入手:)
Abstract
虚拟化技术是 IaaS 的基石,虽然多租户共享同一物理机提高了数据中心服务器的利用率,但带来对安全问题的忧虑(尤其是侧信道攻击),且增加了资源开销;新兴的裸金属云提供了强隔离性与对硬件的完全访问,但只能将整台物理服务器租给用户,无法在出租后对用户程序控制,且扩展性差、成本效率低
本文提出一种新的高密度、多租户裸金属云设计:BM-Hive ,每个裸金属客户运行在各自的计算板上——带有专有 CPU 与内存的 PCIe 扩展板,其软硬件混合 virtio I/O 系统允许客户直接访问云网络与存储设备;BM-Hive 可以显著提升裸金属服务的成本效益,从硬件层分隔裸金属用户以提供更好的安全与隔离;BM-Hive 被作者部署在最大的公有云基础设施之一上,为数万用户同时服务
0x01. Introduction
虚拟化技术是公有 IaaS 云的基石,EPT 这样的高级虚拟化技术显著提升了 VM 性能,但多租户共享同一物理机带来对安全与性能的忧虑,尤其是针对 CPU 缓存与超线程等紧密结合的资源的侧信道攻击,此外共享资源冲突可以带来不可预估的性能波动
Limitations of existing approach :为了解决这些问题,租户独占物理机的裸金属服务出现了(称为单租户裸金属服务器,因为只能整个租出),但其仍有一些成本效益、性能、互通性上的限制:
- Cost :单租户裸金属服务器只能整个租出,但用户不一定需要这么多性能
- Single-thread performance :绝大多数云服务器使用核数多但单核弱的 Xeon ,裸金属服务的用户通常需要更高性能
- Interoperability and manageability :裸金属服务必须无缝结合到现有云系统中以从弹性云架构中受益,然而单租户裸金属服务与现有的基于 VM 的云不同,其通常由 Intel Management Engine 类已知不安全系统管理,且裸金属服务应当与 VM 镜像兼容以复用镜像
Our approach :本文给出 BM-Hive 的设计:一个可以解决所有这些挑战的可扩展的多租户裸金属服务,其由三部分组成:一个裸金属 hypervisor ( bm-hypervisor ,对应传统的 vm-hypervisor )、一组裸金属客户( bm-guest ,对应传统的 vm-guest)、一个 IO 枢纽(IO-Bond); bm-hypervisor 运行在服务器主 CPU 上管理所有 guests 的生命周期并作为 IO-Bond 后端,但不似 vm-hypervisor 那样要虚拟化 CPU 或内存,而是每个 bm-guest 都运行在各自的计算板上(由专有处理器、内存单元、PCIe 接口组成); IO-Bond 作为硬件的一部分由 FPGA 进行实现以用于在主板与计算板间通信,其一方面模拟 I/O 设备(例如 virtio 网络与块设备),另一方面将计算板与主板的 PCIe 总线连接并转发 bm-guest 的 I/O 请求到 bm-hypervisor
BM-Hive 的设计充分解决了单租户裸金属服务的限制, 首先 , BM-Hive 可以在一个 BM-Hive 服务器上支持 16 个 bm-guest ,提升服务密度的同时降低开销, 其次 ,bm-guest 可以使用任何计算板所支持的 CPU, 最后 , BM-Hive 可以无缝融合到现有云基础架构中;最主要的区别是 vm-guest 运行在虚拟 CPU 上,而 bm-guest 运行在计算板上,而这对云基础架构而言是无感知的(归功于 bm-hypervisor 与 IO-Bond ),表 1 对比了三种类型云服务的不同层;此外 bm-guest 无法完全控制整个服务器, bm-hypervisor 通过 PCIe 接口控制其执行,且 IO-Bond 在硬件中强制对 bm-guest 进行适当隔离
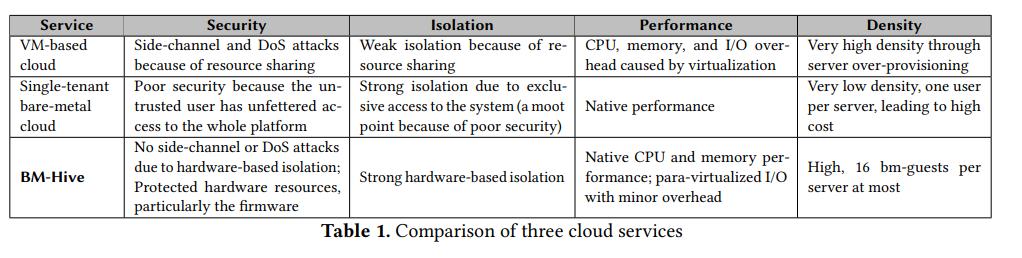
作者在最大的 IaaS 公有云数据中心之一部署了 BM-Hive ,并彻底分析了其安全性与性能表现,其实验展示了 BM-Hive 的强隔离、安全与性能
总而言之,本文贡献如下:
- 作者提出来新的裸金属云设计,结合了现有基于 VM 的与单租户裸金属的服务器的优点,并提供安全、灵活、可操作的裸金属云服务
BM-Hive有软硬件结合的 virtio 系统,让 guests 可以直接与现有云基础架构结合,直接获得云服务的可用性与弹性- 作者基于
BM-Hive的设计构建了一个产品级的系统并在真实的云中部署,证明了BM-Hive的可行性 - 作者在最大的公有云基础设施之一部署了
BM-Hive并充分测量其性能,证明了其相对基于 VM 的云服务的优点
0x02. Background and Motivation
Background :虚拟化是传统云的关键技术,主要有 CPU、内存、I/O 三个层面,CPU 与 内存虚拟化由处理器提供,云上 I/O 则通常是半虚拟化,Guest侧内核直接请求与处理高级 I/O 操作,而非模拟低级 I/O 操作(如寄存器访问),或是直接硬件设备直通
2.1 Impact on Performance
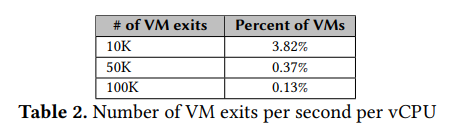
Performance overhead :许多事件都能产生 VM exits 而造成大量开销(单个 exit 事件至少 10 µs 的情况下,每秒 5000+ 次 VM exit 将是不可忽视的开销),表 2 展示了在作者的云数据中心上 5 min 内的 300000 个 VM 的统计情况
即便是 Guest 直接访问硬件的设备直通也会有开销,基于 IOMMU 的实现可以增加 60% 的网卡在 CPU 上使用(但吞吐量不变)
此外还有其他会增加性能开销的层面(如 vCPU 锁、TLB等),但这些在 BM-Hive 服务器中都没有
Performance variation :共享资源的冲突同样带来性能影响,如 I/O 处理高峰期 host OS 可能抢占 guest VM 执行而造成性能开销与波动
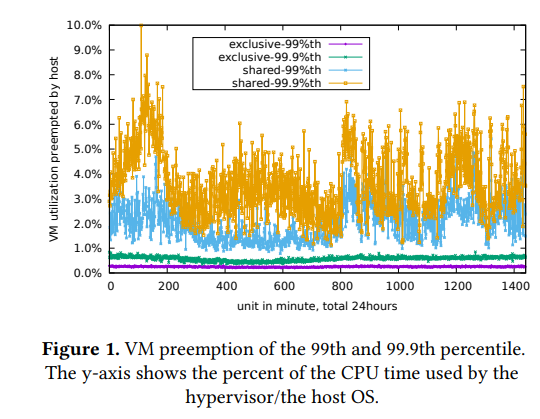
图 1 展示了作者的数据中心在 24 小时内的 20000 VM 由低到高的被 hypervisor 抢占率(shared 表示未与物理核心绑定),需要注意的是这种情况下没有 VM 主动尝试占有资源(否则会更糟)
2.2 Security Concerns
VM 间硬件资源共享可能导致侧信道攻击(如 Meltdown、Spectre、L1TF 等),但在 bm-guest 物理隔离的 BM-Hive 上不存在这个问题
hypervisor 漏洞是云上主要攻击面,但 bm-hypervisor 无需 CPU/内存 虚拟化且不能从 guests 侧直接访问
笔者注:这一块实际上笔者感觉不是很彳亍,因为模拟设备在 DPU 上模拟(通常由 QEMU 实现)同样会有漏洞,对于攻击者而言似乎只是攻击的位置变了
2.3 Nested Hypervisor
传统云用户想要再跑虚拟机只能依赖嵌套虚拟化,这增大了 hypervisor 设计复杂度与性能开销
0x03. Design
3.1 Design Requirements
BM-Hive 设计要求如下:
Multi-tenancy :
BM-Hive必须支持多租户共享同一物理服务器以实现细粒度 CPU 核心Security :
BM-Hive必须提供基于硬件的bm-guests间强隔离Interoperability :
BM-Hive必须与现有云基础架构兼容以获取已有的可用性、依赖性、弹性,互通性(interoperability)要求bm-guest同样能运行在 VM 中,这个特性称为cold migration,其一个依赖项便是bm-guest必须能够与云存储与网络进行高性能连接(由 virtio 这样的半虚拟化支持),BM-Hive通过特制的软硬件混合 virtio 实现Performance :
bm-guest应当有原生 CPU/内存性能与近原生 IO 性能以及最小的性能波动Cost efficiency :
bm-guest在同配置下 开销应比vm-guest小
3.2 System Overview
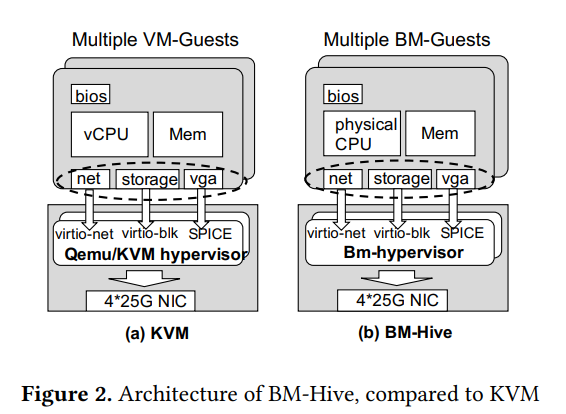
图 2 对比了虚拟化架构与 BM-Hive 的区别,主要区别是 vm-guest 运行在虚拟化 CPU 与内存上而 bm-guest 运行在物理 CPU 与内存上,bm-hypervisor 是类似 vm-hypervisor 的用户态程序,管理 vm-guest 生命周期、提供 virtio 设备、与云基础架构交互等,其不需要虚拟化因而代码比 vm-hypervisor 简单得多,bm-hypervisor 进程与 bm-guest 间一一对应且只能通过 virtio 交互
Use scenario :云基础架构选择一个可用的裸金属服务器并选择一个空闲计算卡启动(通过开启 PCIe power),板上固件开始执行 boot loader 并随后加载 bm-guest 内核,云上绝大部分 guests 无法使用本地存储,因此 bootloader 与内核通过 virtio-blk 获取,作者通过扩展 EFI 固件以实现这一点
3.3 System Architecture
图 3 展示了 BM-Hive 的系统架构,每个裸金属服务器由简化的 Xeon 服务器(base )与一组计算卡(由 CPU、内存、PCIe 总线、FPGA 构建的 IO-Bond 组成的 PCIe 卡)组成,在 bm-guest 视角由计算卡模拟的 virtio 设备是常规的 PCIe 设备,IO-Bond 作为 bm-guest 中的 virtio 前端与 bm-hypervisor 中的 virtio 后端间的桥梁,并通过内置的 DMA 引擎进行命令与数据的转发;IO-Bond 目前支持 virtio 网络与存储设备,且可以轻易扩展,此外其可以由 ASIC 芯片实现
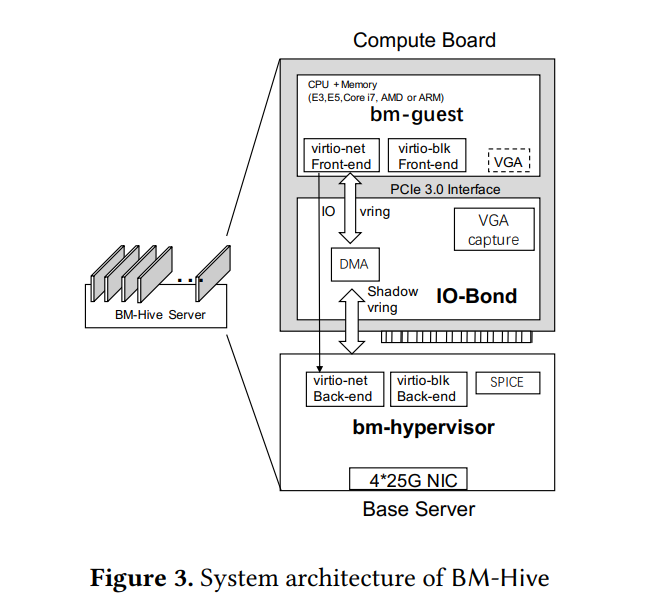
在 bm-hypervisor 的角度每个计算卡便是一个 PCIe 的 bm-guest 设备,一个 base 服务器可以支撑 16 张计算卡,bm-hypervisor 的功能主要有:1️⃣ 管理 bm-guest 生命周期与计算卡分配 2️⃣ 提供并维护 virtio 设备后端 3️⃣ 与现有云基础架构对接
3.4 IO-Bond
IO-Bond 用于充当计算卡上 virtio 设备的代理
3.4.1 IO-Bond: Frontend. IO-Bond 前端连接到计算板的 PCIe 总线,其 FPGA 模拟了 PCI 接口供 bm-guest 使用,并将 bm-guest 访问转发到后端
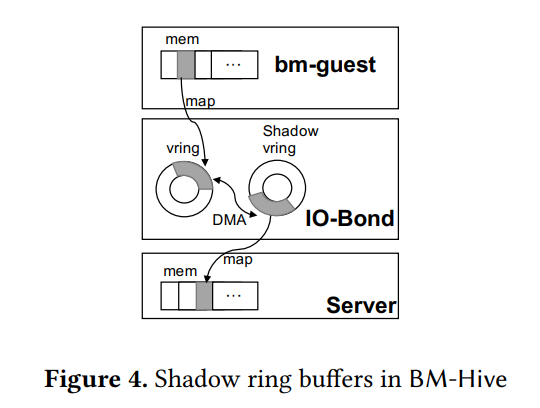
BM-Hive 无法直接使用虚拟化系统的共享环缓冲区设计(IO-Bond 前后端物理内存不共享),因此由 IO-Bond 为 bm-hypervisor 与 bm-guest 提供环缓冲区,并将 bm-hypervisor 的环缓冲区与其他进行同步(如图 4 所示),在一个缓冲区被添加上数据后 IO-Bond 的 DMA 引擎便会拷贝到其他缓冲区
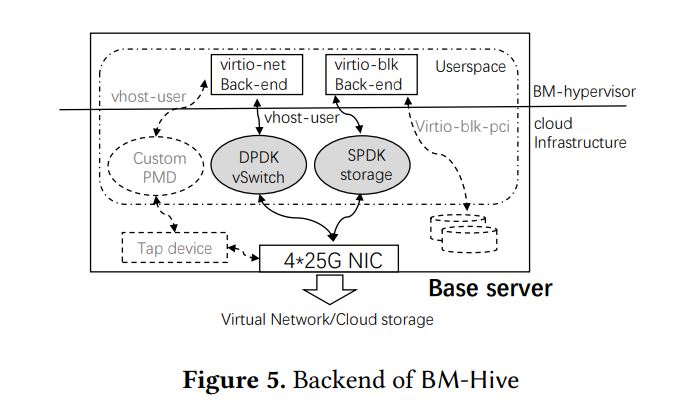
3.4.2 IO-Bond: Backend. IO-Bond 后端将请求转发到对应云设备,其设计主要关注与云基础架构间的高性能 I/O,在 BM-Hive 中所有 I/O 请求通过 vhost-user 协议与云基础架构(修改版 DPDK vSwitch 和 SPDK 云存储,使用 poll mode driver 而非中断)交互,由此所有请求在用户空间完成处理,避免额外的内核与用户态间内存拷贝;此外 BM-Hive 支持 VGA 设备以连接 bm-guest 控制台
3.4.3 IO-Bond Implementation. 每个 virtio 设备的每个 virtio 队列都有一个对应的后端 shadow vring(IO-Bond 与 bm-hypervisor 间的共享缓冲区,所有 shadow vring 被组织为一个缓冲区描述符列表并映射到 IO-Bond 中), bm-hypervisor 与 IO-Bond 间通过一对 mailbox 寄存器传递 PCI 访问提醒,且每个 shadow vring 都有一对 head/tail 寄存器
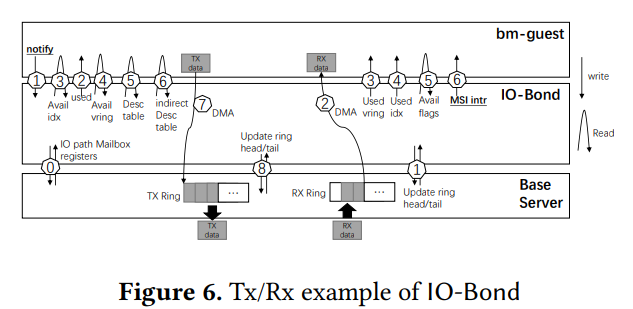
图 6 展示了 IO-Bond 如何响应 guests 的一个传统的 virtio Tx/Rx 工作流,bm-guest 写入 virtio 寄存器以通知 IO-Bond 、并在 Rx 数据到达时获得 MSI 中断;bm-hypervisor 中有一个专有线程拉取 IO mailbox 与 shadow vring head/tail 寄存器以避免中断,图中 1 ~ 6 为标准 virtio 操作;最终 IO-Bond 通过更新 head 寄存器通知 bm-hypervisor ,收到的 Rx 缓冲区被保留
得益于 IO-Bond 中 FPGA 的低开销,bm-guest 到 IO-Bond 的 PCI 读写操作仅需要 0.8 µs,IO-Bond 到 mailbox 寄存器又要 0.8 µs,单次访问总开销仅 1.6 µs;IO-Bond 为每个 virtio 网络/存储设备暴露一个 PCIe x4 接口,通过 PCIe x8 接口备份到 bm-hypervisor ,IO-Bond 内部 DMA 吞吐量为 50Gbps(每个 x4 接口为 32 Gbps),通过服务器共享网络接口(100 Gbps) 转发到云服务,且 bm-guest 间贷款消耗会动态平衡以保持公平
3.5 Costs efficiency
数据中心的盈利能力取决于 vCPU 密度,传统的基于 VM 的服务器需要为 hypervisor 与 host OS 保留 CPU 核心,而 BM-Hive 具有更高的 vCPU 成本效益(虽然需要额外的 CPU 与 FPGA 支出)
能耗也是成本效率的一个点,但 BM-Hive 与传统 VM 服务器提供的 vCPU 不同,因此很难比较
0x04. Evaluation
4.1 Environment Setup
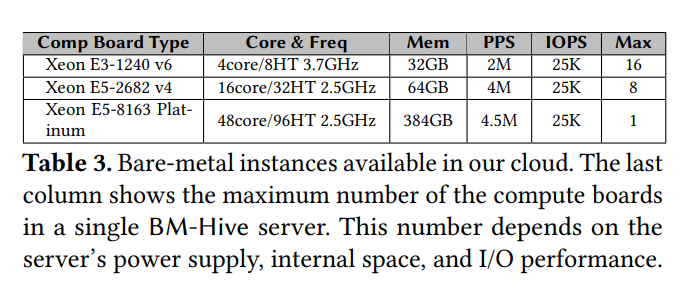
表 3 展示了作者部署 BM-Hive 的公有云上的实例配置,注意一个云实例的 I/O 性能通常被限速以预防资源误用和提升整体服务质量
4.2 CPU and Memory Performance
所有实验在带有相同的基于 CentOS 的系统的 Xeon E5-2682 v4 实例上完成,作者对比了 BM-Hive 与 VM 以及物理机(可行时)的性能,vm-guest 与 bm-guest 都运行在 64G 内存的 Xeon E5-2682 v4 CPU 上,vm-guest 独占实例且固定到有 NMUA 节点亲和力的物理 CPU 核心上
作者将 BM-Hive 与 vm-guest 与物理机器的性能进行比较,内核版本为 3.10.0-514.26.2.el7 ,但物理机有 2 个 CPU 插槽与 384G 内存,图 7 与 8 展示了 SPEC CINT 2006 与 STREAM 的多次测试结果
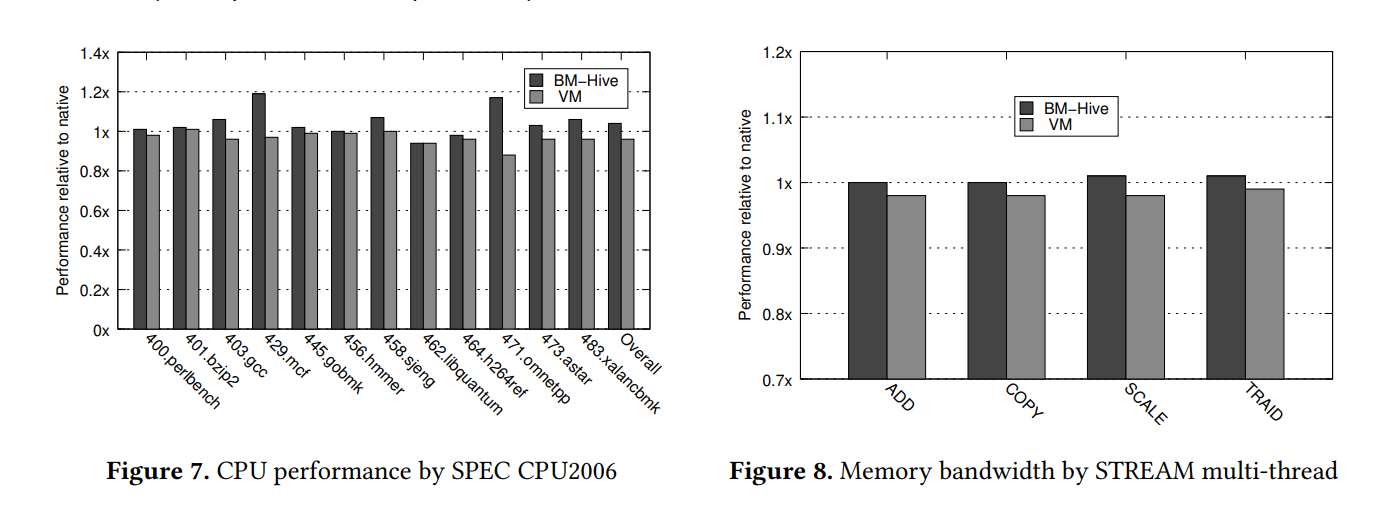
CPU 的测试结果相近,BM-Hive 比物理机快 4%,VM 比物理机慢 4% ,注意到 bm-guest 与物理机性能并不完全相同(因为配置与设计不同), vm-guest 则因为虚拟化的缘故存在开销
BM-HIve 在内存上同样占优,如图 8 所示BM-HIve 几乎与物理机完全相同,但 vm-guest 由于虚拟化开销最多只有 bm-guest 98% 的性能
Summary :同配置 bm-guest比 vm-guest 有更好的 CPU 与内存性能,且 BM-HIve 可以利用单线程性能更高的 CPU
4.3 I/O Performance
bm-guest 与 vm-guest 有着近乎一样的基于 virtio 的 IO 路径,但 BM-Hive 有着软硬件结合的设计,本节我们对比同一云网络与存储下的性能,guests 网速被限制在 4M PPS 与 10Gbps 的带宽,存储被限制在 25 IOPS 与 300 MBps 的带宽
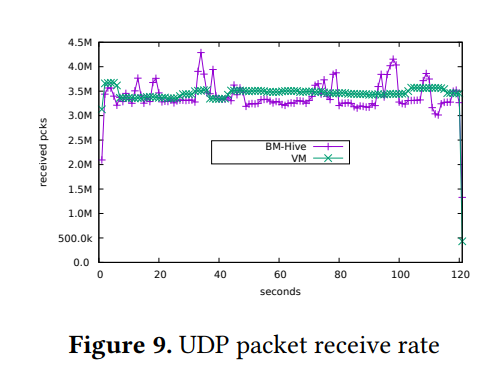
Network performance :作者使用 netperf-2.5 在两个 bm-guest 间收发 UDP 包(并添加 vm-guest 对照组),结果如图 9 所示, bm-guest 与 vm-guest 都达到了 3.2M PPS,由于 BM-Hive 的 I/O 路径更长所以 vm-guest 有着更少的抖动
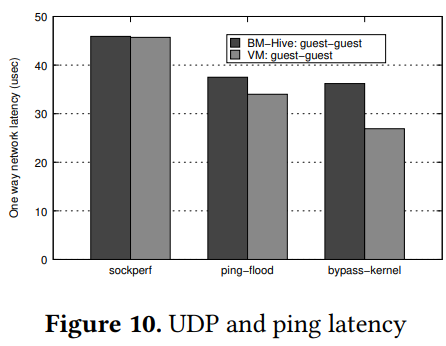
作者使用不同的工具对比了 bm-guest 与 vm-guest 的延迟以测算 IO-Bond 开销,图 10 显示了使用 sockperf-3.5 测试 UDP 的结果(并使用 DPDK 绕过内核),由于 BM-Hive 的 I/O 路径更长所以 vm-guest 结果更好(在 ICMP 上也是)
吞吐量也是网络性能的重点,作者使用 netperf-2.5 测试 64 个单个数据包为 1400B 的 TCP 连接,bm-guest 为 9.6 Gbps, vm-guest 为 9.59 Gbps
总之,BM-Hive 性能满足设计目的,此外作者通过取消 PPS 限制来测量其最大网络性能(可以达到 16M PPS)
Storage performance :作者通过100Gbps 网络访问 SSD 云存储运行 fio benchmark 使用 8 线程进行 4KB 随机读写, bm-guest 与 vm-guest 都是饱和存储速率,但如图 11 所示 bm-guest 有更低的平均延迟与 99.9% 延迟
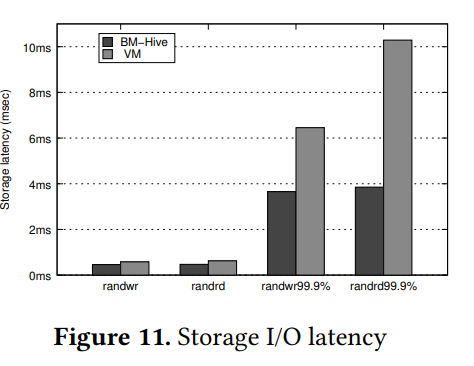
作者还测试了无限制的访问本地 SSD 的存储性能, BM-Hive 在 IOPS 上比 VM 快 50%,在带宽上快 100%,平均延迟仅为 60µs
总之,BM-Hive 的存储性能得益于 IO-Bond 的 DMA 引擎而比需要额外内存拷贝的 VM 更好
Summary :bm-guest 与 vm-guest 都能达到基于云的网络与存储 IO 限制,但 bm-guest 在更坏情况(99.9 percentile)下更好,在无限制下比 vm-guest 性能显著提高
4.4 Application Performance
一个重要的实验是 BM-Hive 执行云上常用应用的性能,测试结果如图 12、13、14 所示
详细的实验数据就不抄了,自己去看原文(笑)
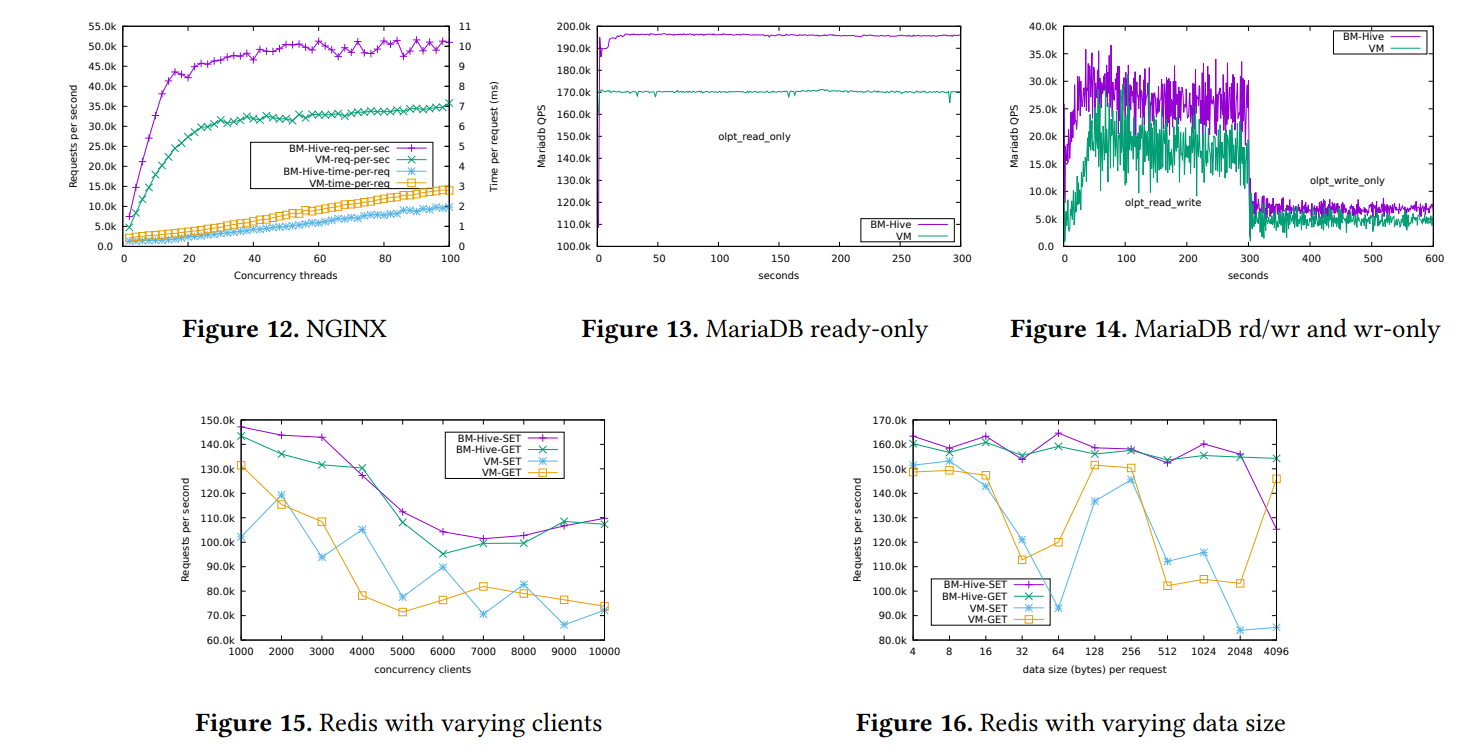
Summary : BM-Hive 运行流行云上应用的性能比基于虚拟化的云服务更好
0x05. Related Work
Reducing world switches :虚拟化的主要开销之一便是 guest 与 hypervisor 间的切换,有一部分工作便关注于减少切换,例如形如网卡的高速驱动会产生大量中断,ELI (Exit-Less Interrupt)致力于将 hypervisor 从中断路径上移除从而让 Guest 直接处理中断以提高吞吐量并减少延迟;此外在 guest 侧也有优化空间,如 KVM 最近引入的 halt_polling 特性在让 CPU 休眠前拉取唤醒请求以避免 guest 在休眠后又立即被等待中的唤醒请求唤醒;但 BM-Hive 不会有这些问题
Memory virtualization :内存通常被虚拟化为两级页表:GVA➡️GPA➡️HPA,因此现有工作之一便是减少开销极大的 TLB miss ,如增大 TLB 覆盖率(例如使用大页)或减少 TLB 惩罚,如 POM-TLB 便是将内存的一部分作为 TLB 以增大 TLB,或是跟踪页访问以维护 TLB 而减少 TLB miss;但 BM-Hive 不会有这些问题
Device virtualization :现有虚拟设备大都通过半虚拟化实现,最流行的便是 virtio ,此外如 SR-IOV 网卡等也支持原生虚拟化;特别地,BM-Hive 通过混合方式实现了 virtio 以与现有云基础架构交互
Minimal hypervisor :也有一些工作关注于创建最小的 hypervisor ,如 Intel 的 ACRN 便是用于嵌入式 IOT 设备的小型 hypervisor ( 笔者注:嵌入式设备还要跑 VM? );BM-Hive 比传统的 hypervisor 都简单,因为其并不虚拟化任何东西,也不直接与 bm-guest 交互
Nest hypervisor :BM-Hive 目标之一便是让用户能运行自己的虚拟机,在传统架构上嵌套虚拟化可以实现但开销较大,BM-Hive 的用户直接运行在物理 CPU 上因而有着完全的硬件虚拟化支持
Other bare-metal services :绝大部分公有云都部署了单租户裸金属服务,限制如第 1 节所示;部分公有云也为 VM 部署了特殊的网络设备,例如 Azure 也有智能网卡,但据作者所知其更关注底层云基础架构的优化,而 BM-Hive 并不接触云基础架构层
也有部分系统有着相似的整体架构,如 Intel 的 VCA2 便是一个带有三个 Xeon E3 v1258L 处理器的 PCIe 卡,但 BM-Hive 是为了云服务而生的
0x06. Discussion
本节讨论 BM-Hive 的潜在提升与未来研究计划
Improvements to IO-Bond : IO-Bond 的设计可以进行优化(例如将包处理从 bm-hypervisor 卸载到 IO-Bond 上),除了使用 FPGA 以外也可以使用 ASIC 实现
Live Migration and Upgrade :虚拟机动态迁移非常重要,Orthus 被用于在不停止虚拟机的情况下动态升级 VMM,BM-Hive 的设计使其可以直接应用 Orthus 的方案升级 VMM,但 bm-guest 的迁移则更有挑战,目前的方案是插入一个虚拟化曾并将其转换为 vm-guest ,但仍存在优化空间
SGX Support :SGX 是一个可信执行环境,但目前的虚拟机不好使用这个东西,作者计划在未来为 BM-Hive 添加原生 SGX 支持
0x07. Summary
作者设计了 BM-Hive 并进行了评估,很好很强大🎇🎆🎇